El Cambio: Por Qué los Rankings Ya No Significan Visibilidad

La web no se rompió de un día para el otro. Se desplazó.
En 2012, Google empezó a responder algunas consultas directamente en la página de resultados — paneles del Knowledge Graph. En 2014 llegaron los Featured Snippets. Cada paso movió la respuesta un poco más cerca del usuario y un poco más lejos de tu sitio. Luego, en mayo de 2023, Google lanzó la Search Generative Experience — rebautizada después como AI Overviews — y el desplazamiento se aceleró más allá del punto en que se pudiera ignorar.
La pregunta solía ser: “¿Cómo posiciono?” Ahora hay una segunda pregunta que importa igual: “¿Cómo consigo que me citen?”
Este post cubre tanto el cambio como la primera respuesta práctica a él — dos bases que todo sitio debería tener en su lugar antes de preocuparse por algo más sofisticado.
El Cambio
El volumen de búsqueda tradicional está cayendo, los motores de respuesta con IA absorben millones de consultas al día, y la mayoría de esas interacciones nunca producen un clic. Los números ya no son proyecciones — son la realidad actual.
Todo el SEO que conocemos — palabras clave, backlinks, meta etiquetas, velocidad de página, diseño móvil — se construyó alrededor de un modelo simple: subir tu enlace en una lista de resultados. Ese modelo se está rompiendo.
Las búsquedas por usuario en EE.UU. ya bajaron un 20% año tras año. Y el problema no es solo que busquen menos — es lo que pasa cuando sí buscan. Los AI Overviews aparecen en la mitad de las búsquedas en EE.UU., y cuando lo hacen, el 83% terminan sin un clic. El usuario recibe la respuesta ahí mismo. La lista de enlaces de abajo — la lista que pasamos años optimizando — no la toca nadie.
Y eso es solo Google. Sumale que cientos de millones de personas ya ni siquiera pasan por un buscador — le preguntan directamente a ChatGPT, Perplexity o Claude, y reciben una respuesta sintetizada con citas. El SEO no está muerto, pero ya no es suficiente por sí solo.
Y esto no solo afecta a sitios pequeños. En enero de 2026, Adam Wathan — creador de Tailwind CSS — reveló que tuvo que despedir al 75% de su equipo de ingeniería por lo que llamó el “impacto brutal” de la IA en su negocio. El titular suena dramático hasta que ves los números: el equipo de ingeniería eran 4 personas — despidió a 3, quedó 1. El tráfico a la documentación de Tailwind había caído un 40% en dos años, y los ingresos un 80%. Lo paradójico: Tailwind como framework estaba creciendo más rápido que nunca. Pero los desarrolladores ya no visitaban el sitio — Cursor, GitHub Copilot y ChatGPT respondían sus dudas directamente en el editor. El embudo que convertía visitas a la documentación en ventas de productos pagos simplemente se rompió. Todo explotó cuando Wathan cerró un PR en GitHub que proponía hacer la documentación más accesible para LLMs, argumentando que facilitar el acceso a los modelos solo significaba menos tráfico y menos ingresos. El hilo acumuló cientos de comentarios, el repo se hizo privado temporalmente, y la historia llegó a Hacker News con más de 1.100 puntos. Como Wathan dijo en su podcast: “Tailwind es más grande y más popular que nunca, y nuestros ingresos cayeron cerca del 80%.” La historia tuvo un final feliz — Vercel, Google y otras empresas terminaron patrocinando al proyecto, y Tailwind sobrevivió. Pero el modelo de negocio que lo sostenía ya no existe, y lo que venga después va a tener que verse muy diferente. Es quizá el ejemplo más visible de lo que este cambio significa en la práctica.
AEO No Surgió de la Nada
Antes de entrar en las bases prácticas, vale la pena saber que esto ya tiene investigación detrás.
Un artículo de la Universidad de Princeton presentado en KDD 2024 demostró que estrategias específicas de optimización pueden aumentar la visibilidad en respuestas de motores generativos hasta en un 40%. Ellos lo llaman GEO (Generative Engine Optimization), otros le dicen LLMO — SEMrush y Ahrefs ya tienen guías completas sobre el tema con diferentes nombres. Al final, todos hablan de lo mismo: optimizar para motores que dan respuestas en vez de enlaces.
Las dos primeras bases que cualquier sitio puede poner en su lugar son más simples de lo que parecen.
Los Motores de Respuesta
No todos los motores de respuesta con IA funcionan igual. Entender cómo Google AI Overviews, ChatGPT, Claude y Perplexity rastrean y recuperan contenido es el primer paso para hacerse visible ante ellos — y todo empieza por el robots.txt.
Para optimizar para los motores de respuesta, ayuda entender cómo funcionan realmente. No todos operan de la misma manera. Pasé más tiempo del esperado revisando documentación de crawlers — las diferencias importan.
Google AI Overviews no usa un crawler separado. Si Googlebot ya indexó tu página, eres elegible. Lo interesante es su técnica de “query fan-out” — al construir una respuesta, el sistema lanza múltiples sub-consultas relacionadas. Una página que rankea en posición 40 para un tema relacionado puede terminar citada en la respuesta principal. El contenido que mejor funciona son bloques de respuesta específicos y autocontenidos — párrafos que responden una pregunta concreta sin depender del contexto alrededor. Algunos análisis sugieren que el rango ideal está entre 134 y 167 palabras por bloque.
ChatGPT corre tres crawlers separados, cada uno controlable de forma independiente: GPTBot para entrenamiento, OAI-SearchBot para su índice de búsqueda, y ChatGPT-User para navegación en tiempo real. Puedes bloquear el entrenamiento mientras permites la búsqueda — son decisiones separadas. La mayoría de la gente no sabe esto.
Claude también tiene tres bots — ClaudeBot, Claude-SearchBot, y Claude-User. Su búsqueda web está impulsada por Brave Search. Los tres respetan robots.txt, incluyendo Crawl-delay.
Perplexity usa PerplexityBot para indexación (explícitamente no para entrenamiento de modelos) y Perplexity-User para consultas en tiempo real. Favorece la densidad factual, la actualidad y una estructura HTML limpia. Sus dominios más citados: Reddit, YouTube y Gartner — no exactamente el podio del SEO tradicional.
Permitir los crawlers de IA en robots.txt es la base — y una decisión sorprendentemente activa. Este sitio permite explícitamente 13 crawlers:
# AI/LLM Crawlers - Explicitly allowed
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: anthropic-ai
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
# ... más Bytespider, CCBot, Applebot-Extended, Amazonbot, Meta-ExternalAgent, cohere-aiDecidí permitirlo todo — tanto crawlers de entrenamiento como de búsqueda. Para un sitio personal, la visibilidad importa más que optar por no participar en un uso de datos que de todas formas no puedo controlar. Un sitio comercial podría pensar diferente — bloquear GPTBot para entrenamiento mientras permite OAI-SearchBot para citas. El punto es que estas son decisiones independientes ahora, y “no hacer nada” también es una decisión.
Algo que vale la pena notar: Apple está construyendo su propio sistema de búsqueda con IA. “World Knowledge Answers” se espera en iOS 26.4, impulsado en parte por los modelos Gemini de Google. Su crawler Applebot-Extended ya está evaluando contenido para entrenamiento de IA. Para cuando lance, los sitios que ya permitan Applebot estarán en el índice. Los que no, no.
La Primera Base: Darle a la IA un Menú
Estar en la lista de permitidos significa que los bots de IA pueden visitar. Pero aparecer y ser entendido son cosas distintas — una lección que aprendí más lentamente de lo que debería. Un crawler que llega a una página llena de clases de Tailwind, íconos SVG y markup de navegación tiene que excavar entre mucho ruido para encontrar el contenido real.
Ahí es donde entra llms.txt.
La especificación llms.txt fue propuesta por Jeremy Howard en septiembre de 2024. La premisa es simple: en vez de hacer que un modelo de lenguaje rastree todo tu sitio para entender qué hay ahí, le entregas un índice estructurado — un archivo Markdown en /llms.txt que le da a los sistemas de IA un resumen curado de tu sitio. Qué cubre, cómo está organizado, dónde encontrar las cosas. Unas 10 a 30 líneas que toman unos minutos escribir.
La adopción todavía es temprana — Semrush reporta que solo unos 951 dominios habían publicado un archivo llms.txt a mediados de 2025. Los primeros adoptadores son mayormente orientados a desarrolladores: Anthropic, Cloudflare, Vercel, Supabase.
En junio de 2025, John Mueller de Google dijo que “ningún sistema de IA usa llms.txt.” Pero desde entonces, Cloudflare lanzó Markdown for Agents y el ecosistema se movió rápido — herramientas como Cursor, Claude y otros agentes de código ya consumen archivos Markdown como fuente primaria de contexto. El llms.txt encaja exactamente en esa dirección.
Lo pienso como el sitemap.xml de la era de la IA: el costo es unas líneas de Markdown, y si el patrón se consolida — que todo indica que sí — la información ya está ahí.
Así se ve el de este sitio:
# XergioAleX.com
> Personal website and technical blog by Sergio Alexander Florez Galeano
> (XergioAleX): CTO & Co-founder at DailyBot (Y Combinator S21).
## Core Sections
- Home: /
- Blog: /blog/
- About: /about/
- Portfolio: /portfolio/
...
## Blog Tags
- tech — Software development tutorials and technical articles
- ai — Artificial intelligence and machine learning content
...
## Blog Series
- Building XergioAleX.com (8 chapters)
- Trading Journey (3 chapters)
## Crawling Guidance
- All public content is intended for indexing by search engines and LLM systems.
- Structured data (JSON-LD) is embedded on all pages for machine consumption.
## Detailed Version
For comprehensive content descriptions, see: /llms-full.txtTambién hay un llms-full.txt — 130 líneas con descripciones detalladas de páginas, áreas temáticas y el stack tecnológico completo. A la fecha, ningún crawler de IA lo consume automáticamente — pero desarrolladores ya lo usan manualmente como contexto en herramientas como Cursor, y plataformas como Mintlify lo generan por defecto para toda su documentación. El patrón está ganando tracción aunque los buscadores no lo adopten formalmente todavía.
La Segunda Base: Hablar su Vocabulario
Aquí es donde el AEO se vuelve concreto — y, honestamente, un poco tedioso.
Los datos estructurados son E-E-A-T — Experiencia, Expertise, Autoridad, Confiabilidad — codificados en un formato que las máquinas pueden analizar directamente. Las páginas con schema markup tienen tasas de citación por IA 2,8 veces más altas. Google, Microsoft y OpenAI usan datos estructurados en sus funciones de IA generativa. Los sitios con datos estructurados y bloques FAQ muestran tasas de citación por IA mediblemente más altas comparados con los que no los tienen.
El schema más importante en este sitio es el tipo Person — aparece en cada página:
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Sergio Alexander Florez Galeano",
"alternateName": "XergioAleX",
"url": "https://xergioalex.com",
"image": "https://xergioalex.com/images/profile.png",
"description": "CTO & Cofounder of DailyBot (Y Combinator S21). Computer Science Engineer, MSc in Data Science, with 14+ years building digital products.",
"jobTitle": "CTO & Co-founder",
"worksFor": {
"@type": "Organization",
"name": "DailyBot",
"url": "https://dailybot.com"
},
"alumniOf": [
{ "@type": "Organization", "name": "Y Combinator" },
{ "@type": "CollegeOrUniversity", "name": "Universidad Tecnológica de Pereira" }
],
"knowsAbout": [
"Software Engineering", "Artificial Intelligence", "Web Development",
"DevOps", "Blockchain", "Algorithmic Trading", "Startup Building"
],
"sameAs": [
"https://github.com/xergioalex",
"https://www.linkedin.com/in/xergioalex/",
"https://x.com/XergioAleX",
"https://www.instagram.com/xergioalex"
]
}Cada campo cumple un propósito. alumniOf con Y Combinator — credibilidad institucional. worksFor — contexto profesional actual. sameAs con cuatro perfiles sociales — verificación de identidad entre plataformas. knowsAbout — señales de autoridad temática. Nada de esto es decorativo. Cada campo es algo que un sistema de IA puede usar cuando decide si citar este sitio como fuente.
Los datos estructurados me llevaron un tiempo considerable. No es un trabajo emocionante — escribir schemas JSON, validarlos en el Schema.org Validator para verificar que la estructura sea correcta, asegurarse de que cada página tenga los tipos correctos.
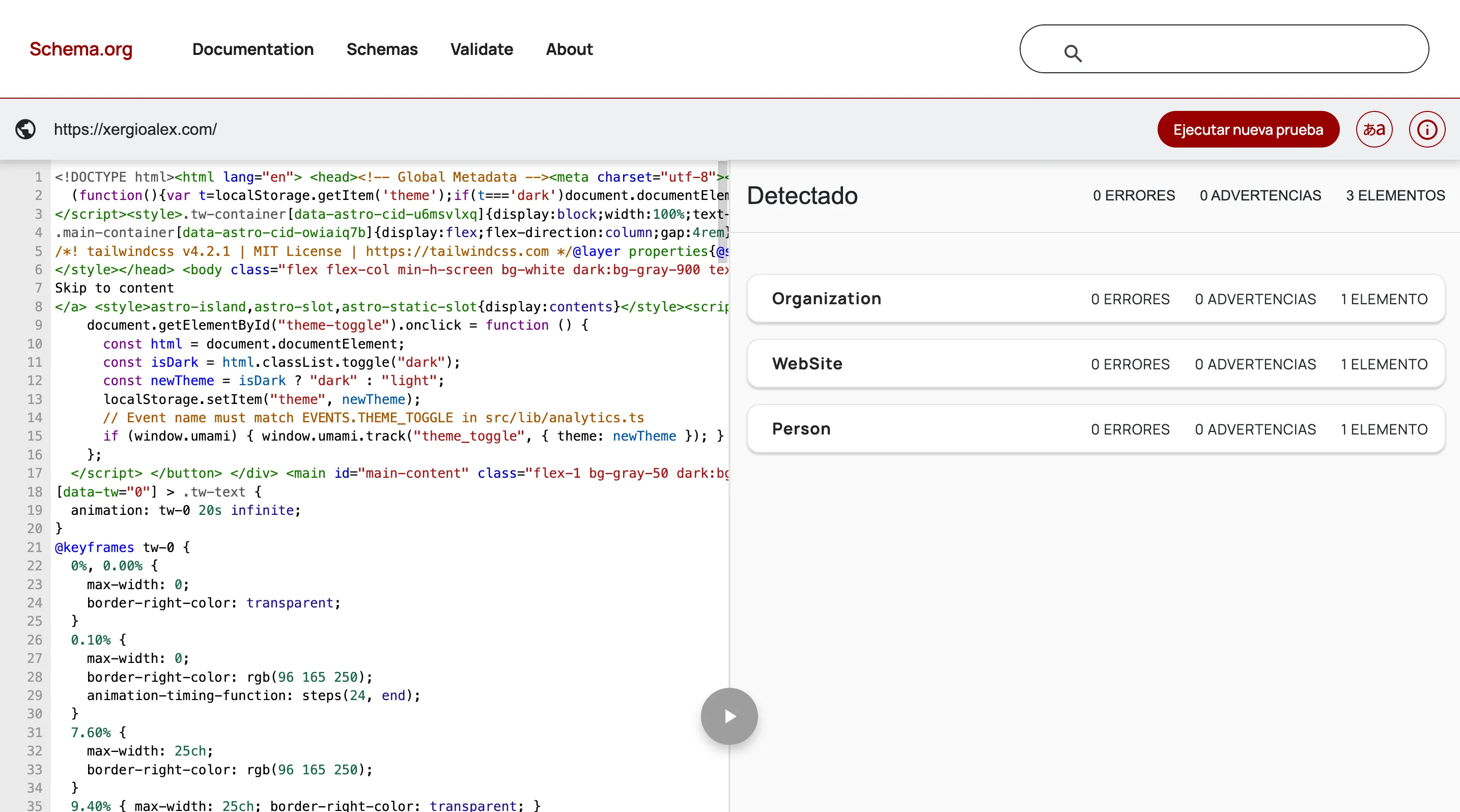
En un blog post la cosa se pone más interesante — además de los schemas base, aparecen BlogPosting y BreadcrumbList:
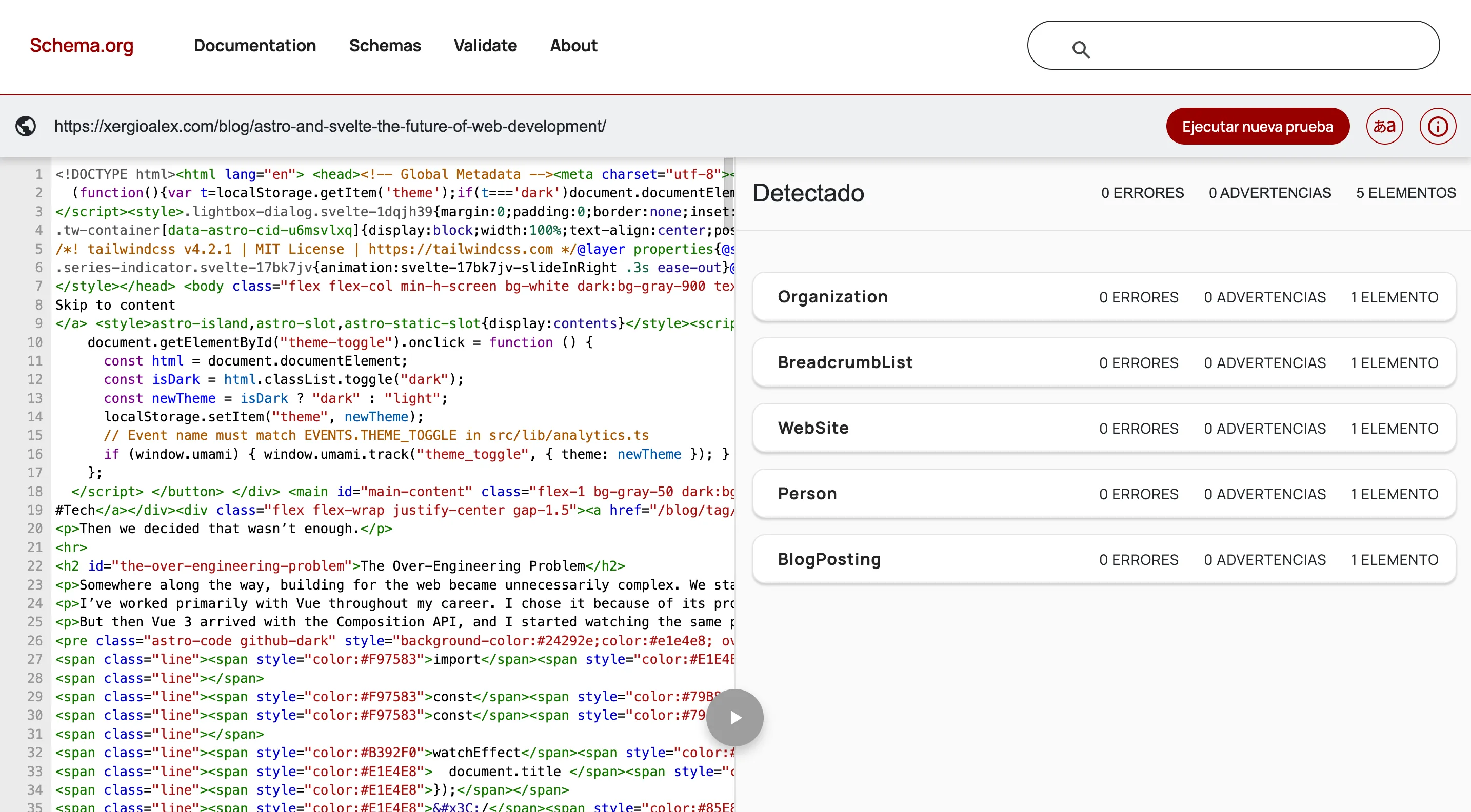
Al expandir el BlogPosting, se ve todo lo que la IA puede leer sin parsear el HTML: título, descripción, imagen, fechas de publicación y modificación, keywords, conteo de palabras — cada campo es una señal explícita que le ahorra trabajo de inferencia al modelo.
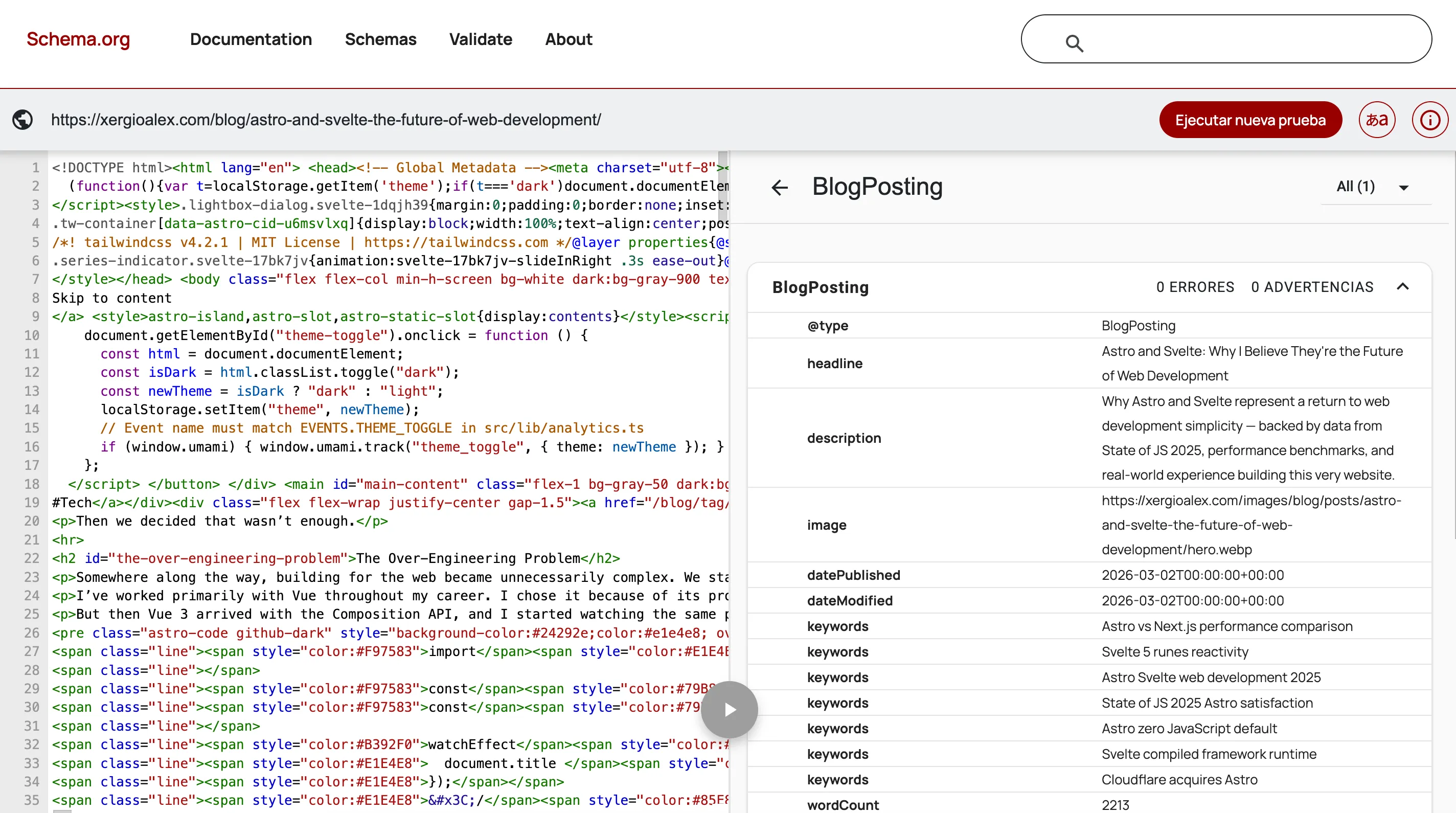 Pasé una tarde entera en el schema
Pasé una tarde entera en el schema BlogPosting, comparando la especificación de schema.org para verificar qué propiedades usan realmente los sistemas de IA versus cuáles son técnicamente válidas pero ignoradas. La mayor parte del primer borrador estaba mal en cosas pequeñas. Volver a revisar documentación que ya había leído no fue divertido.
Pero es la optimización que comunica significado directamente a las máquinas — no solo contenido, sino contexto. Quién escribió esto, por qué está calificado para escribirlo, cuándo fue actualizado por última vez. Esa es la capa que importa.
Más allá del schema Person, este sitio tiene 9 tipos JSON-LD en total: BlogPosting (con wordCount, timeRequired, dateModified y datos de autor anidados), BreadcrumbList en cada página, Organization para DailyBot, WebSite, CollectionPage, ContactPage y ProfilePage.
Lo Que Viene
Las bases están en su lugar: crawlers permitidos, un menú en /llms.txt, datos estructurados en cada página. Pero ser rastreable y ser legible por máquinas son solo las condiciones mínimas — te meten en el juego. La frontera más interesante es darle a los agentes de IA un canal directo a tu contenido, saltando el parseo de HTML por completo con endpoints nativos de Markdown.
De eso trata el próximo capítulo: Markdown for Agents: Cómo Hacer que tu Contenido Hable el Idioma de la IA. Sigamos construyendo.
Recursos
Investigación y Datos
- Artículo GEO de Princeton — Generative Engine Optimization (KDD 2024)
- Search Engine Land: Caída en Búsquedas de Escritorio en EE.UU.
- Demand Sage: Estadísticas de AI Overviews
- Demand Sage: Estadísticas de Perplexity AI
- DevClass: Tailwind Labs Despide al 75% de Ingenieros por Impacto de la IA
- GitHub: Discusión sobre Documentación LLM-Friendly en Tailwind CSS
- AirOps: Schema Markup y Tasas de Citación por IA
- BrightEdge: Schema y Visibilidad en AI Overview
Definiciones y Guías
- SEMrush: Answer Engine Optimization
- Ahrefs: Answer Engine Optimization
- Search Engine Land: AAO — Assistive Agent Optimization
- Ahrefs: Rankings en Búsqueda vs Citas de IA
Estándares y Especificaciones
- Especificación Oficial de llms.txt
- Schema.org
- SEMrush: Reporte de Adopción de llms.txt
- Stackmatix: Datos Estructurados en Búsqueda con IA (Google, Microsoft, OpenAI)
- Google: Introducción a los Datos Estructurados
Documentación de Crawlers
- Crawlers de OpenAI
- Crawlers de Anthropic
- Crawlers de Perplexity
- Google: Cómo Tener Éxito en la Búsqueda con IA
- Apple World Knowledge Answers
Herramientas

Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.