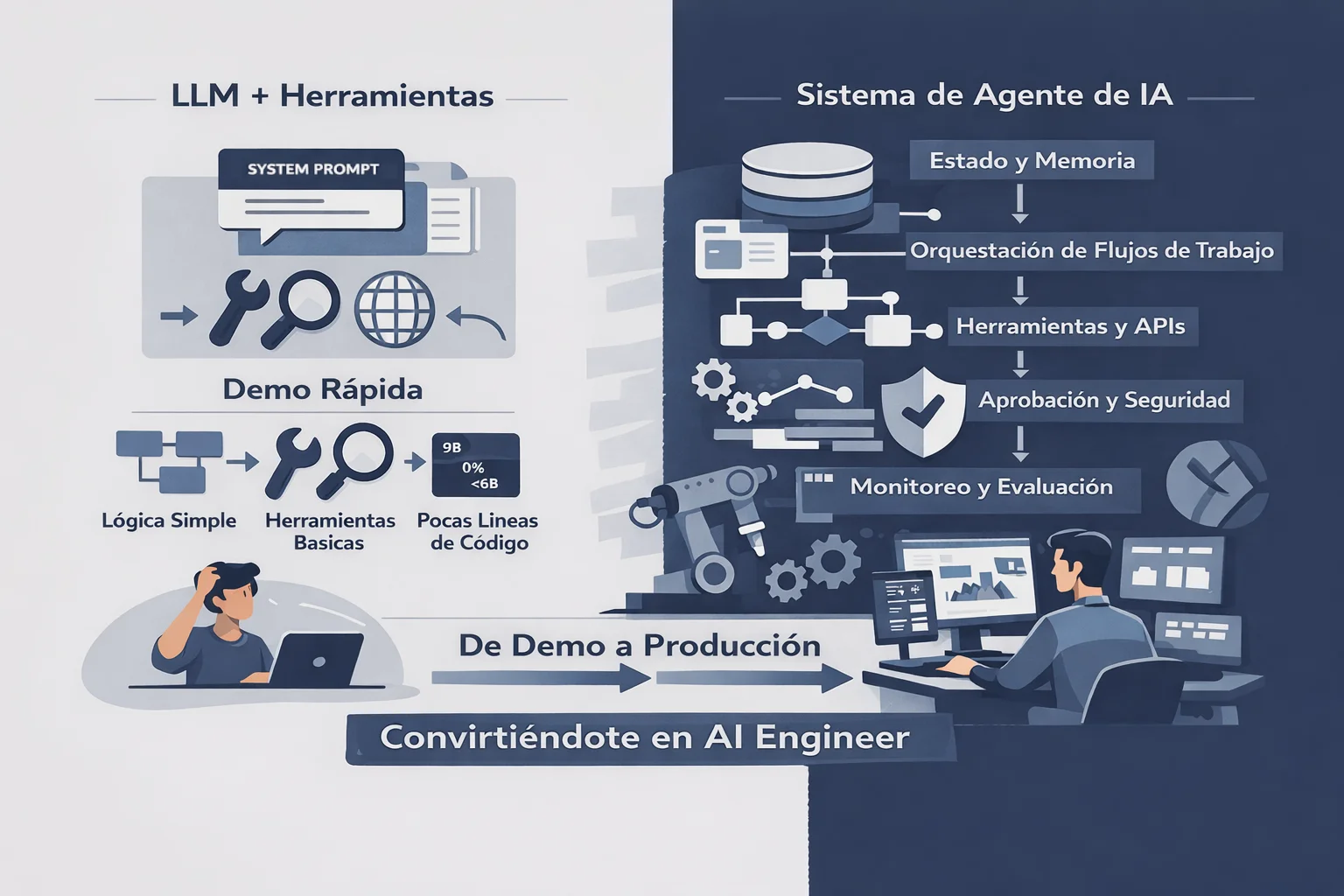
Cuando piensas hoy en construir un agente de IA, la imagen que tienes en la cabeza probablemente es algo así: toma un LLM, dale un system prompt, conéctale unas cuantas funciones que pueda llamar, pon todo en un bucle. El modelo razona, elige una herramienta, obtiene un resultado, razona de nuevo. Unas pocas líneas de Python. Listo.
Ese modelo mental no está del todo equivocado. Un agente sí necesita un modelo, y sí necesita herramientas. Pero llamar a eso un agente es como llamar a una aplicación web “un servidor que devuelve HTML.” Técnicamente cierto. Prácticamente inútil como principio de diseño. En el momento en que intentas construir algo que sobreviva al uso real — usuarios reales, fallas reales, consecuencias reales — esa imagen simple se derrumba.
Los inicios rápidos y las demos refuerzan esto. Están optimizados para el “momento aha” — lograr que algo funcione en cinco minutos. Eso está bien para el marketing. Es activamente engañoso para la ingeniería. El inicio rápido no te muestra qué pasa cuando el agente necesita recordar algo de tres pasos atrás. No te muestra qué pasa cuando una herramienta falla y el agente necesita decidir si reintentar o escalar. No te muestra cómo saber si el agente está funcionando correctamente, o si simplemente produce resultados que suenan plausibles.
Por eso existen frameworks como LangChain y LangGraph — para manejar la complejidad que la versión del quickstart ignora. Gestión de estado, orquestación de múltiples pasos, coordinación de herramientas, puntos de control. Son herramientas de ingeniería reales, y algunas son excelentes. Pero hay algo con lo que me sigo encontrando: el framework te da mejores herramientas para implementar soluciones. No diseña las soluciones por ti. La arquitectura — las decisiones sobre qué mantener en el estado, cómo debería funcionar la memoria, qué herramientas necesitan puertas de seguridad — eso sigue siendo tu responsabilidad.
Esa conclusión — que construir agentes se trata menos de aprender una librería y más de convertirte en un nuevo tipo de ingeniero — es de lo que se trata Construyendo Agentes.
Donde el Modelo Simple se Rompe
La distancia entre un agente simple y uno confiable no es incremental — es arquitectónica. Y aparece rápido. Toma un escenario común: un agente que recopila investigación de múltiples fuentes, la sintetiza, redacta un documento estructurado y señala lo que necesita revisión humana. Tres herramientas, un objetivo claro, unas 200 líneas de código de orquestación. Debería ser sencillo.
En la práctica, estos sistemas tienden a funcionar un 60% de las veces. El otro 40% es una mezcla de fallas difíciles de predecir y más difíciles aún de depurar:
Colapso de contexto. Después de tres o cuatro llamadas a herramientas, la ventana de contexto se llena con resultados intermedios y el modelo empieza a tratar observaciones antiguas como si fueran nuevas. El agente pierde el hilo de dónde está en el flujo de trabajo — no porque las herramientas fallen, sino porque nadie diseñó el estado para sobrevivir más de unos pocos turnos.
Mal uso de herramientas. El agente llama a la herramienta correcta con los parámetros incorrectos — no incorrectos de forma aleatoria, sino incorrectos con confianza. Construye una interpretación plausible de lo que la herramienta espera, y resulta que esa interpretación es equivocada. Generalmente es señal de que los esquemas de las herramientas son ambiguos, no de que el modelo esté roto.
Bucles de alucinación. El agente repite la misma consulta de búsqueda con frases ligeramente distintas, cada vez obteniendo resultados levemente diferentes, ninguno satisfactorio, hasta que se agota el tiempo o produce un resumen confuso que mezcla hechos de cuatro iteraciones distintas. Sin detección de bucles, sin condición de salida — el sistema simplemente entra en espiral.
Ninguna de estas son fallas del modelo. El modelo hace exactamente lo que esperarías que hiciera un modelo de lenguaje dados los inputs que recibe. Son fallas de arquitectura. El sistema no tiene una gestión de estado adecuada. Las definiciones de las herramientas no imponen contratos de parámetros. No hay mecanismo de puntos de control, ni forma de inspeccionar lo que realmente está pasando dentro de una ejecución de varios pasos.
La guía Building Effective Agents de Anthropic traza esta línea con claridad: lo que separa una demo funcional de un sistema funcional es todo lo que sucede entre las llamadas a las herramientas — la orquestación, las transiciones de estado, las decisiones de enrutamiento. Ese “entre” es donde la mayoría de los sistemas de agentes se desmoronan.
Lo Que un Agente Real Realmente Contiene
Aquí está la lista honesta. Lo que un sistema de agentes en producción realmente requiere:
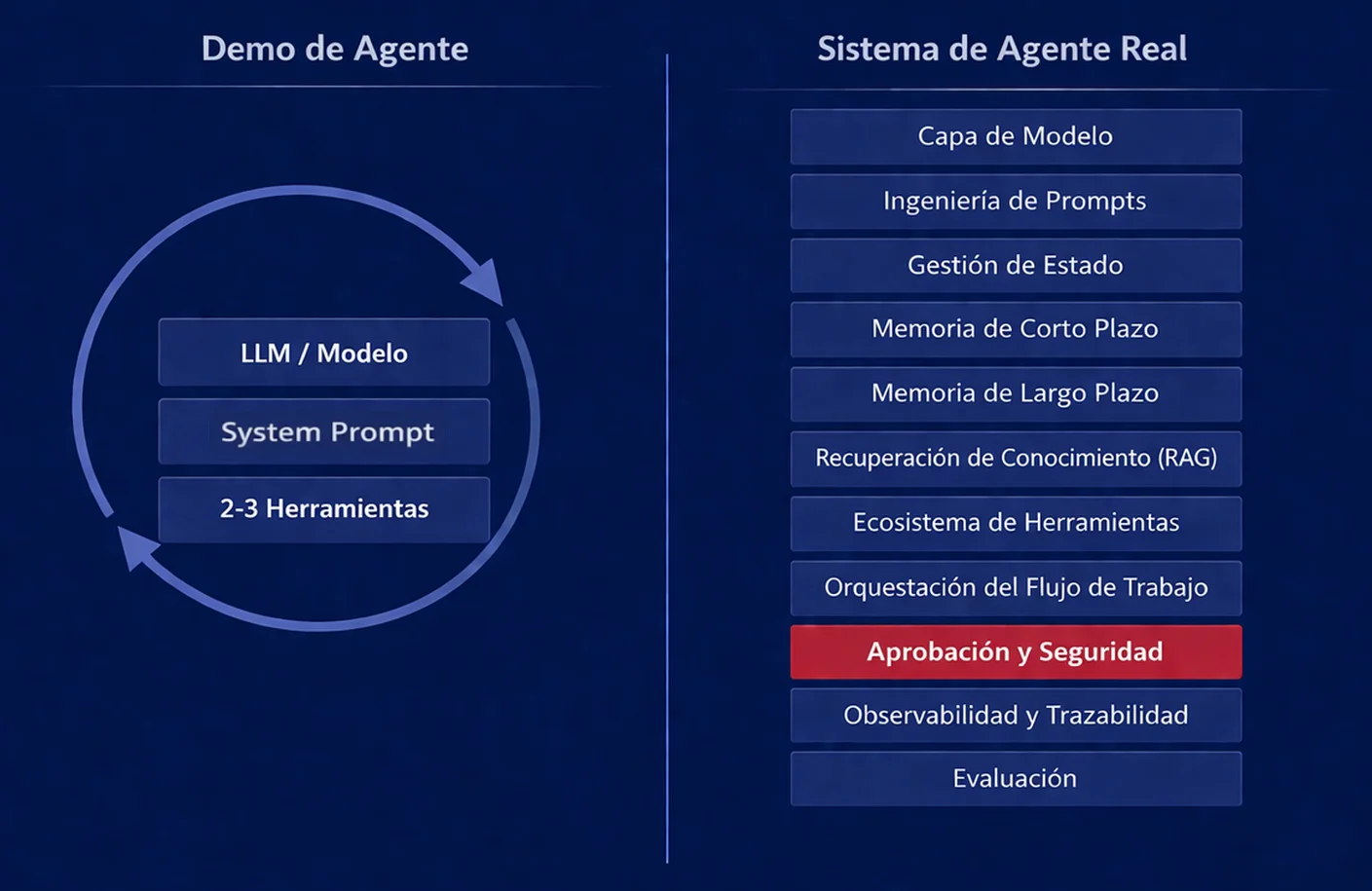
Capa de modelo — Qué modelo, qué proveedor, cómo manejar los límites de tasa y los fallos. Más fácil de lo que suena hasta que necesitas fallbacks.
Ingeniería de prompts — No solo el system prompt. La estrategia de contexto completa: qué va en el prompt estático, qué se inyecta dinámicamente, cómo estructurar los resultados de las herramientas, cómo manejar conversaciones largas sin degradar la calidad.
Gestión de estado — Todo lo que el agente sabe en cada paso. No solo “el historial de conversación” sino: tarea actual, puntos de control de progreso, resultados intermedios, qué se ha intentado, qué está pendiente. Este es su propio problema de diseño.
Memoria de corto plazo — Lo que el agente recuerda dentro de una sesión. No es lo mismo que la ventana de contexto. Tienes que decidir qué conservar, qué comprimir, qué descartar.
Memoria de largo plazo — Lo que el agente recuerda entre sesiones. Requiere almacenamiento, recuperación y decisiones sobre qué vale la pena recordar. La mayoría de las demos se saltan esto por completo.
Recuperación de conocimiento (RAG) — Cómo el agente accede a conocimiento con el que el modelo no fue entrenado — documentación de la empresa, políticas internas, datos de dominio. Estrategia de fragmentación, elección de embeddings, método de recuperación, reranking. Un campo con sus propios modos de fallo.
Ecosistema de herramientas — No solo “funciones que el modelo puede llamar” sino: diseño de esquemas, validación de parámetros, manejo de errores, gestión de efectos secundarios, límites de permisos. Cada herramienta es una superficie para el fallo.
Orquestación del flujo de trabajo — Cómo se estructuran, secuencian, ramifican y reúnen las tareas de varios pasos. Cuándo ejecutar en paralelo, cuándo esperar, cuándo abandonar.
Capa de aprobación y seguridad — Qué requiere confirmación humana. Qué nunca debería ocurrir automáticamente. Cómo implementar paradas duras. Frecuentemente es una idea de último momento. Debería ser una preocupación de diseño de primer orden.
Observabilidad y trazabilidad — ¿Puedes ver lo que el agente realmente hizo? ¿Qué llamadas a herramientas se hicieron, con qué parámetros, en qué orden, con qué resultados? Sin esto, depurar es adivinar.
Evaluación — ¿Cómo sabes si el agente está funcionando correctamente? No solo “¿produjo una salida?” sino “¿produjo la salida correcta?” Esta es probablemente la capa menos discutida en todo el campo.
Cada una de estas es una disciplina de ingeniería distinta. La mayoría de ellas no existía como campo con nombre hace cinco años. Todas son necesarias. Puedes saltarte algunas en un agente simple. No puedes saltarte ninguna en uno serio.
Esta serie va a explorar cada una de estas capas — qué involucran realmente, dónde fallan, y qué se necesita para hacerlas bien.
El Ecosistema Hoy
El ecosistema que ha crecido alrededor de la construcción de agentes es — sinceramente — impresionante. No en el sentido del hype. En el sentido de “esto señala algo real.”
En el lado de frameworks y SDKs: LangChain/LangGraph se ha convertido en el punto de partida por defecto para la mayoría de equipos que construyen agentes — la comunidad más grande, la mayor cantidad de integraciones, y probablemente el tratamiento más explícito del estado de agentes disponible en herramientas de código abierto. CrewAI se enfoca en la orquestación de múltiples agentes — varios agentes colaborando en tareas — y ha encontrado un seguimiento sólido para ese patrón específico. AutoGen/AG2, el enfoque de Microsoft, adopta un modelo conversacional de múltiples agentes. Mastra es un framework con TypeScript como primera clase que vale la pena seguir si estás construyendo en un ecosistema JavaScript. Vercel AI SDK apuesta por lo web-nativo y el streaming.
Luego están los SDKs de primera parte de los propios proveedores de modelos. Anthropic lanzó el Claude Agent SDK. OpenAI lanzó su Agents SDK. Google publicó ADK (Agent Development Kit). Cuando los proveedores de modelos empiezan a lanzar frameworks con opiniones propias para construir con sus modelos, significa que han pasado de “aquí está la API” a “así es como realmente construyes con esto.”
Y por debajo de todo, está la capa de protocolo. MCP — Model Context Protocol — alcanzó 97 millones de descargas mensuales del SDK antes de ser donado a la Agentic AI Foundation para su gestión abierta. A2A (Agent-to-Agent) de Google y ACP de OpenAI están atacando la interoperabilidad entre agentes. Estos son movimientos de infraestructura aburridos. Los movimientos de infraestructura aburridos importan.
La observación a la que sigo volviendo: cuando Stripe, Coinbase, Google, Anthropic, Microsoft y decenas de startups bien financiadas están todas construyendo infraestructura para agentes simultáneamente, algo real está pasando. No necesariamente en la dirección que ninguna empresa individual predice, pero real. Esto no es una moda que quedará como nota al pie en cinco años.
No tengo idea de qué frameworks específicos van a ganar. Esa es una pregunta aparte. Lo que el ecosistema te dice es que el problema subyacente — construir sistemas de agentes confiables — es difícil e importante en igual medida. La inversión en infraestructura confirma la existencia del problema.
Por Qué “AI Engineer” Está Empezando a Significar Algo
Swyx acuñó el término “AI Engineer” en 2023 en un ensayo en Latent Space. En ese momento se sentía aspiracional — una forma de describir lo que algunas personas empezaban a hacer antes de que el rol tuviera nombre. Tres años después es un título de trabajo en miles de ofertas, con expectativas específicas asociadas.
Esto es lo que las empresas realmente están buscando contratar: no “¿puedes llamar la API de OpenAI?” — cualquiera puede hacer eso en minutos. Quieren saber: ¿puedes diseñar la gestión de estado para un flujo de trabajo de agentes de múltiples turnos? ¿Puedes implementar un sistema de memoria que escale? ¿Puedes depurar un agente que produce resultados sutilmente incorrectos? ¿Puedes construir un pipeline de evaluación que te diga si una nueva versión del modelo es realmente mejor? ¿Puedes diseñar esquemas de herramientas que reduzcan el mal uso sin sobre-restringir la flexibilidad del modelo?
Ese es un conjunto de habilidades diferente al de ML Engineering, que se enfoca en el entrenamiento, el ajuste fino y la evaluación en la capa del modelo. También es diferente de la ingeniería de software tradicional, aunque se apoya mucho en ella. El AI Engineer opera en el espacio entre ambas: entiende los modelos lo suficiente como para trabajar con ellos de forma confiable, y entiende los sistemas lo suficiente como para construir la infraestructura que hace que los modelos sean útiles.
Creo que el rol seguirá cristalizándose. No porque alguien decidiera inventar un nuevo rol, sino porque el trabajo lo exige. Cuando la inteligencia central de tu sistema es probabilística y el resto del sistema tiene que ser confiable, necesitas ingenieros que puedan pensar en ambos registros simultáneamente.
La Tensión en el Corazón de Todo
Esto es lo que encuentro más interesante sobre construir agentes — y lo que creo que la mayoría de los tutoriales pierden por completo.
Hemos pasado treinta años construyendo sistemas deterministas. Entrada → lógica → salida. Los mismos inputs siempre producen los mismos outputs. Depurar significa rastrear la lógica. Probar significa cubrir los casos extremos. La confiabilidad significa escribir la lógica correctamente.
Los agentes rompen con esto. Parte de la inteligencia del sistema es probabilística — los mismos inputs podrían producir outputs diferentes en distintas ejecuciones. El modelo razona, y el razonamiento tiene varianza. Eso no es un bug. Es la característica. La capacidad del modelo para manejar situaciones novedosas, para generalizar, para producir outputs útiles para inputs que nunca ha visto — todo eso viene de la misma naturaleza probabilística que lo hace impredecible.
Pero la confiabilidad del sistema igualmente tiene que ingeniarse. A los usuarios no les importa que el modelo subyacente sea probabilístico. Les importa si el agente hace lo que se supone que debe hacer, de forma consistente, sin cometer errores catastróficos.
Entonces terminas con esta tensión: abraza el probabilismo en la capa del modelo, ingenia la confiabilidad en todo lo demás. Outputs estructurados para restringir lo que devuelve el modelo. Validación para verificar si tiene sentido. Lógica de reintento para cuando no lo tiene. Puertas de aprobación para acciones irreversibles. Evaluación para verificar que el sistema está mejorando con el tiempo.
Esta tensión define cada decisión de diseño en los sistemas de agentes. ¿Cuánto confías en el modelo? ¿Dónde agregas salvaguardas? ¿Qué hardcodeas versus qué dejas flexible? No hay una respuesta universal — depende de la tarea, las apuestas, el usuario. Pero pensar en estos compromisos es, yo diría, la habilidad intelectual central del AI Engineer.
Los ingenieros civiles aprendieron a construir con madera, luego con acero, luego con concreto. Cada material requirió nuevas disciplinas — nuevas formas de pensar sobre carga, fallo, tolerancias. Los LLMs son un nuevo material para construir software. La disciplina todavía se está inventando.
El Descubrimiento Que Se Repite
Hay un patrón por el que pasa casi todo el que construye agentes. Se ve más o menos así:
“Solo voy a usar un framework” → “¿por qué el estado sigue comportándose raro?” → “bien, necesito un diseño de estado adecuado” → “espera, la memoria es su propio problema completo” → “estos esquemas de herramientas están causando mal uso” → “no tengo idea si esto está funcionando correctamente” → “no puedo depurar esto sin trazas.”
Cada nueva capacidad revela una nueva capa. Cada capa tiene sus propios modos de fallo, sus propios patrones de diseño, su propio cuerpo de conocimiento. No ves la siguiente capa hasta que la anterior te obliga a mirar.
Las sesiones de depuración son las que cambian la perspectiva. Un agente trata una tarea que ya completó como si todavía estuviera pendiente — y el bug no está en ninguna línea de código individual. Está en el esquema de estado. Dos partes diferentes del flujo de trabajo escriben en la misma clave con suposiciones diferentes sobre lo que representa el valor. El modelo no está equivocado. El diseño de estado está equivocado. Ese tipo de falla no aparece en ningún tutorial de inicio rápido. Solo aparece cuando el sistema es lo suficientemente complejo como para tener suposiciones en conflicto — es decir, cuando empieza a parecerse a un sistema real.
Este es el momento en que la mayoría de los constructores pasan de “estoy aprendiendo un framework” a “estoy aprendiendo un oficio.” El framework maneja la fontanería. El oficio es todo lo que está por encima: las decisiones sobre estructura, límites, confianza y recuperación de fallos que ninguna librería puede tomar por ti.
La serie paralela que estoy escribiendo — Trabajando con Agentes — explora cómo es trabajar con agentes día a día: el cambio de productividad, los cambios en el flujo de trabajo, lo que le hace a cómo piensas sobre el trabajo. Esta serie es sobre lo que pasa cuando intentas construirlos. Es la capa que está debajo de esa experiencia.
Por Qué los Frameworks No Son Suficientes
Esto es, creo, lo más importante que puedo decirte antes de entrar en esta serie.
Los frameworks resuelven la sintaxis, no la arquitectura. Puedes conocer la API de StateGraph de LangGraph al derecho y al revés y aun así construir un agente terrible. El framework te da herramientas. No toma tus decisiones de diseño.
El framework no te enseña: cómo diseñar el estado para tu flujo de trabajo específico, cuándo la memoria de corto plazo es suficiente versus cuándo necesitas almacenamiento persistente de largo plazo, qué herramientas deberían ser de solo lectura versus cuáles tienen efectos secundarios que requieren puertas de aprobación, cómo estructurar un conjunto de evaluación que realmente te diga si el agente está funcionando correctamente, qué hacer cuando el modelo devuelve con confianza algo plausible pero incorrecto.
Django no te enseña a construir una buena aplicación web. Rails no te enseña buen diseño de bases de datos. LangGraph no te enseña buen diseño de agentes. Estas herramientas implementan patrones bien. No eligen los patrones por ti.
Esto no significa que los frameworks sean malos — el modelo de estado explícito de LangGraph y las trazas de LangSmith se han convertido en herramientas estándar por buenas razones. La comunidad de LangChain ha producido más patrones útiles de agentes que cualquier otro lugar del ecosistema. Estas herramientas son necesarias — pero las decisiones de diseño que realmente determinan si un agente funciona o no viven por encima de la capa del framework. De eso se trata esta serie: Construyendo Agentes.
La Analogía del Oficio
A esto sigo volviendo.
Construir agentes se parece más a aprender un oficio que a aprender una tecnología. De la misma forma en que la carpintería no es solo “saber qué es un formón” — es entender la veta, el diseño de las uniones, qué pasa cuando la madera se mueve con la humedad, la sensación específica de un corte que va bien versus uno que va mal. Puedes leer sobre los patrones de la veta durante un año y aun así producir muebles que se agrietan. El conocimiento vive en las manos y en la experiencia acumulada de los fracasos.
La arquitectura funciona igual. Puedes conocer todos los principios — carga, ciencia de materiales, sistemas estructurales — y aun así diseñar un edificio con un defecto que solo se revela cuando el viento golpea desde una dirección específica en una estación específica. La disciplina se construye a partir del reconocimiento de patrones acumulado a través del encuentro con sistemas reales.
Los agentes son así. Los modelos conceptuales son necesarios pero insuficientes. En el momento en que construyes algo con requisitos reales de estado e interacciones reales con herramientas, aparecen casos extremos que ningún tutorial anticipó. Tu sistema de memoria recupera el contexto equivocado en un paso crítico y tienes que decidir: ¿agrego más lógica de recuperación, o simplifico el esquema? Tu herramienta falla a mitad de una operación de varios pasos y el agente necesita decidir si se completó o no — y tu gestión de estado o captura suficiente para recuperarse, o no. Estas son decisiones de criterio. El criterio viene de la experiencia.
Por eso estoy escribiendo la serie como historias, no como especificaciones. El conocimiento de oficio vive en historias, no en documentación. La documentación te dice qué funciones existen. Las historias te dicen cuándo usarlas y qué pasa cuando no lo haces.
Hacia Dónde Va Esto
Un agente que funciona una vez es una demo. Un agente que funciona de forma confiable es arquitectura. La distancia entre los dos es de lo que se trata esta serie.
Si alguna vez construiste un agente que funcionaba en pruebas y se cayó en producción — o si estás a punto de empezar a construir uno y quieres ahorrarte parte del dolor — los próximos capítulos van a profundizar en cada capa: estado, memoria, recuperación, herramientas, confiabilidad, observabilidad. No como teoría, sino como problemas de ingeniería que tienen soluciones reales y compromisos reales.
El modelo mental que la mayoría carga — LLM más herramientas, unas pocas líneas de código — no está mal como punto de partida. Pero es el punto de partida de un camino que resulta ser mucho más largo e interesante de lo que parece desde afuera.
Recursos
- Anthropic: Building Effective Agents — Guía fundamental sobre patrones de diseño de agentes de Anthropic; la referencia más clara para pensar en la arquitectura de agentes
- Andrew Ng: Agentic Design Patterns — La taxonomía canónica: reflexión, uso de herramientas, planificación, múltiples agentes; modelos mentales útiles para estructurar el comportamiento de los agentes
- Lilian Weng: LLM Powered Autonomous Agents — Un estudio académico profundo sobre arquitecturas de agentes que se mantiene como referencia sólida años después de su publicación
- Chip Huyen: Building A Generative AI Platform — Marco de disciplina de ingeniería para sistemas de IA; cómo funciona realmente la infraestructura de IA en producción
- Swyx: Rise of the AI Engineer — El ensayo que acuñó el rol y definió el conjunto de habilidades; todavía la mejor articulación de lo que separa la ingeniería de IA de las disciplinas adyacentes
- LangGraph Documentation — El tratamiento de framework más explícito sobre estado y orquestación de agentes disponible en código abierto
- Harrison Chase: What is a Cognitive Architecture? — El concepto de sistemas de agentes como arquitecturas cognitivas; un reencuadre útil que conecta el diseño de agentes con cómo razonan los sistemas
- Model Context Protocol (MCP) — El estándar abierto para conectar IA a herramientas y fuentes de datos; ahora bajo la gestión de la Agentic AI Foundation
- Claude Agent SDK — El SDK de primera parte de Anthropic para construir sistemas de agentes con Claude
- OpenAI Agents SDK — El framework de agentes de OpenAI, con buena documentación sobre transferencias y salvaguardas
- Simon Willison: Agentic Engineering Patterns — Patrones prácticos para construir con agentes de código; la perspectiva más fundamentada y honesta sobre qué funciona y qué no
- Hamel Husain: Your AI Product Needs Evals — Enfoques prácticos para construir pipelines de evaluación para sistemas basados en LLMs; la capa que la mayoría omite

Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.