Rastreando lo Invisible: Cómo Construí Analíticas para Bots de IA sin JavaScript del Lado del Cliente

Este sitio corre en Cloudflare Pages. Una de las cosas que viene con la plataforma es un directorio functions/ — pones un archivo TypeScript ahí, y Cloudflare lo detecta automáticamente y lo despliega como middleware en el edge. Cada solicitud pasa por él. Sin infraestructura que gestionar.
Tenía un uso específico para eso. Esto es lo que construí.
El Punto Ciego
El stack de analíticas de este sitio me gusta cómo quedó. Umami para rastreo de eventos con privacidad primero. Cloudflare Web Analytics en el edge. Gratuitos, rápidos, sin banners de cookies ni scripts pesados.
Lo que no noté — o no pensé con suficiente cuidado — fue quién no podía ser contado.
Ambas herramientas funcionan de la misma manera. Un snippet de JavaScript corre en el navegador del visitante. El snippet dispara eventos. Los eventos llegan a una API. Los números suben en un dashboard. Esa cadena solo funciona si hay un navegador. Si hay un visitante que realmente ejecuta JavaScript.
Hoy en día, algunos de los visitantes más importantes de un sitio de contenido no son ese tipo de visitante.
El Problema con los Crawlers
Los crawlers de IA — GPTBot, ClaudeBot, PerplexityBot, los demás — no navegan la web como los humanos. Envían una solicitud HTTP, leen el HTML, y se van. No hay navegador ni ejecución de JavaScript.
Entonces cada vez que GPTBot rastrea una página, no veo nada. La solicitud se sirve, el crawler la consume, y mis analíticas registran cero. Para el dashboard, esa visita nunca ocurrió.
Lo irónico: este sitio se había esforzado por invitar a esos crawlers. Un robots.txt que los nombraba explícitamente a los doce con reglas Allow: /. Archivos llms.txt y llms-full.txt para consumo de LLMs. Datos estructurados para ayudar a los sistemas de IA a entender el contenido.
Les había abierto la puerta. No tenía idea si alguien estaba entrando.
Y no son solo los bots de IA. Lectores de RSS, crawlers de motores de búsqueda, herramientas de monitoreo — todo lo que no usa navegador es invisible para las analíticas del lado del cliente. Yo había asumido que “analíticas” significaba “analíticas JavaScript” sin cuestionarlo.
La Solución
Lo que necesitaba era simple: algo que pudiera inspeccionar cada solicitud, mirar el encabezado User-Agent, y registrar el bot antes de servir el contenido estático. El directorio functions/ de Cloudflare Pages hace exactamente eso — pones un archivo TypeScript ahí y se despliega como middleware en el edge.
Un archivo. Sin nuevas dependencias, sin cambios al build de Astro.
Recorriendo el Código
Aquí está functions/_middleware.ts completo, con explicación de cada parte.
Las Definiciones de Tipos
interface Env {
PUBLIC_UMAMI_WEBSITE_ID?: string;
}
interface EventContext {
request: Request;
env: Env;
next: () => Promise<Response>;
waitUntil: (promise: Promise<unknown>) => void;
}Las Cloudflare Pages Functions corren en un entorno Worker. La interfaz EventContext define lo que recibe el middleware: la solicitud entrante, el entorno (donde leo los secretos), una función next() para pasar la solicitud aguas abajo, y waitUntil() para trabajo asíncrono no bloqueante.
Definí estas interfaces inline en lugar de instalar @cloudflare/workers-types. Los tipos que necesito son pocos y estables — no valía la pena agregar una dependencia.
La Lista de Bots
const AI_BOT_PATTERNS: ReadonlyArray<{ pattern: RegExp; name: string }> = [
{ pattern: /GPTBot/i, name: 'GPTBot' },
{ pattern: /ChatGPT-User/i, name: 'ChatGPT-User' },
{ pattern: /ClaudeBot/i, name: 'ClaudeBot' },
{ pattern: /anthropic-ai/i, name: 'anthropic-ai' },
{ pattern: /Google-Extended/i, name: 'Google-Extended' },
{ pattern: /Bytespider/i, name: 'Bytespider' },
{ pattern: /CCBot/i, name: 'CCBot' },
{ pattern: /PerplexityBot/i, name: 'PerplexityBot' },
{ pattern: /Applebot-Extended/i, name: 'Applebot-Extended' },
{ pattern: /Amazonbot/i, name: 'Amazonbot' },
{ pattern: /Meta-ExternalAgent/i, name: 'Meta-ExternalAgent' },
{ pattern: /cohere-ai/i, name: 'cohere-ai' },
];Son los mismos bots listados en robots.txt con reglas explícitas Allow: /. No es coincidencia — la puerta abierta y el sensor usan la misma lista.
Cada entrada tiene un patrón regex y un nombre limpio. Los nombres aparecen en los eventos de analíticas, así que quería que fueran legibles. “GPTBot” es más útil en un dashboard que la cadena de User-Agent sin procesar.
La Función de Detección
function detectAiBot(userAgent: string): string | null {
for (const { pattern, name } of AI_BOT_PATTERNS) {
if (pattern.test(userAgent)) {
return name;
}
}
return null;
}Escaneo lineal a través de la lista de patrones. Gana el primer match. Devuelve el nombre del bot si lo encuentra, null si no.
Simple. La lista son doce elementos. Un trie o matching más sofisticado sería optimización prematura para algo que corre en resultados null el 99.9%+ de las veces.
El Manejador de Solicitudes
export async function onRequest(context: EventContext): Promise<Response> {
const userAgent = context.request.headers.get('user-agent') || '';
const botName = detectAiBot(userAgent);
// Solicitudes de no-bots: pasar inmediatamente con cero overhead
if (!botName) {
return context.next();
}
// Bot detectado: log a consola (visible en logs en tiempo real del dashboard de CF)
const url = new URL(context.request.url);
console.log(
`[AI Bot] ${botName} → ${url.pathname} (${context.request.method})`
);
// Rastrear a Umami via API server-side (no bloqueante)
const websiteId = context.env.PUBLIC_UMAMI_WEBSITE_ID;
if (websiteId) {
context.waitUntil(sendToUmami(websiteId, botName, context.request));
}
return context.next();
}Cada solicitud pasa por esta función. Si no es un bot, context.next() devuelve la respuesta inmediatamente — el overhead para visitantes humanos son doce pruebas de regex, microsegundos.
Si se detecta un bot, pasan dos cosas: un log de consola (para visibilidad en tiempo real en el dashboard de Cloudflare) y una llamada a context.waitUntil() hacia Umami.
Luego context.next() devuelve la página real. El bot recibe su respuesta.
El Payload de Umami
function buildUmamiPayload(
websiteId: string,
botName: string,
url: string,
hostname: string,
language: string
): object {
return {
payload: {
website: websiteId,
url,
hostname,
language,
name: 'ai_bot_visit',
data: {
bot: botName,
path: url,
method: 'GET',
},
},
type: 'event',
};
}La API server-side de Umami acepta un payload JSON con un type y un payload. El nombre del evento es ai_bot_visit — el mismo que uso para todo el tracking de bots. El objeto data personalizado adjunta el nombre del bot y la ruta, lo que significa que puedo filtrar por bot en el dashboard de Umami.
La Llamada de Rastreo
async function sendToUmami(
websiteId: string,
botName: string,
request: Request
): Promise<void> {
const requestUrl = new URL(request.url);
const body = buildUmamiPayload(
websiteId,
botName,
requestUrl.pathname,
requestUrl.hostname,
'en-US'
);
try {
await fetch(UMAMI_API_URL, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(body),
});
} catch {
// Falla silenciosamente — las analíticas nunca deben romper el sitio
}
}Un fetch a la API de Umami envuelto en try/catch con un catch vacío. Si Umami está caído o la solicitud expira, el sitio sirve normalmente. Las analíticas nunca deberían romper nada.
Decisiones
Regex en Lugar de una Biblioteca
No hay paquete npm para detección de bots de IA aquí. Miré un par — isbot, crawler-user-agents — y honestamente, hacen más de lo que necesito. Doce patrones regex hacen el trabajo. Los patrones vienen de la documentación oficial de cada bot (OpenAI, Anthropic, Google, etc.), y son lo suficientemente estables como para que un enfoque regex sobreviva a cualquier biblioteca que los envuelva.
El compromiso: cuando aparece un nuevo bot de IA y quiero rastrearlo, actualizo el array y el archivo robots.txt. Dos lugares. Manual, pero obvio. Si usara una biblioteca, estaría esperando un ciclo de release en lugar de hacer un cambio de dos líneas.
waitUntil() en Lugar de await
Esta sí importa. Si hubiera escrito:
await sendToUmami(websiteId, botName, context.request);
return context.next();Entonces cada visita de bot bloquearía esperando a que la llamada a la API de Umami se resolviera antes de devolver una respuesta. Para un bot que no se preocupa por la latencia, esto no tiene sentido. Para el rendimiento en el edge, es activamente malo.
context.waitUntil() registra una promesa que se resuelve después de enviar la respuesta. El bot recibe su página inmediatamente, la llamada a Umami corre en segundo plano. Hacer lo mínimo antes de responder, diferir el resto.
La Misma Instancia de Umami
Rastro los bots de IA en el mismo sitio web de Umami que los visitantes humanos — no en un proyecto separado. Los eventos están etiquetados ai_bot_visit y llevan data.bot para que pueda filtrar y segmentar. Pero los datos viven en el mismo lugar.
La alternativa era un sitio de Umami separado solo para bots. Lo pensé unos treinta segundos y decidí que era sobre-ingeniería. Quiero ver el tráfico de bots junto al tráfico humano — mismo dashboard, misma línea de tiempo, mismo contexto. Un bot visitando el blog la misma semana que un pico de tráfico de un artículo compartido es interesante. En dashboards separados, esa correlación es más difícil de ver.
La variable de entorno PUBLIC_UMAMI_WEBSITE_ID ya está configurada en el dashboard de Cloudflare — el middleware la lee desde context.env. No agregué un nuevo secreto ni una nueva variable de entorno. La infraestructura ya estaba.
Lo Que Puedo Ver Ahora Que Antes No Podía
El primer deploy, nada pasó. Sin logs, sin eventos. Pensé que tenía un bug. Resulta que solo tenía que esperar — los bots no visitan en tu horario. Como una hora después, [AI Bot] GPTBot → /blog/building-xergioalex-website/ (GET) pasó por los logs en tiempo real de Cloudflare.
Ese es un crawler real de OpenAI, leyendo uno de mis posts del blog. No tengo idea en qué ciclo de entrenamiento de modelo entró, ni si el contenido terminó en algún dataset de fine-tuning. Pero puedo ver que ocurrió. Eso es lo importante. Antes de esto, era invisible. Ahora está registrado.
En Umami, los eventos ai_bot_visit aparecen en la sección de eventos personalizados con el nombre del bot adjunto. Puedo filtrar por bot = ClaudeBot, ver qué páginas ha visitado el crawler de Anthropic, y compararlo con la distribución de vistas de página de los lectores humanos. Puedo rastrear si el tráfico de bots se correlaciona con la publicación de nuevos posts. Puedo ver qué secciones del sitio se rastrean más.
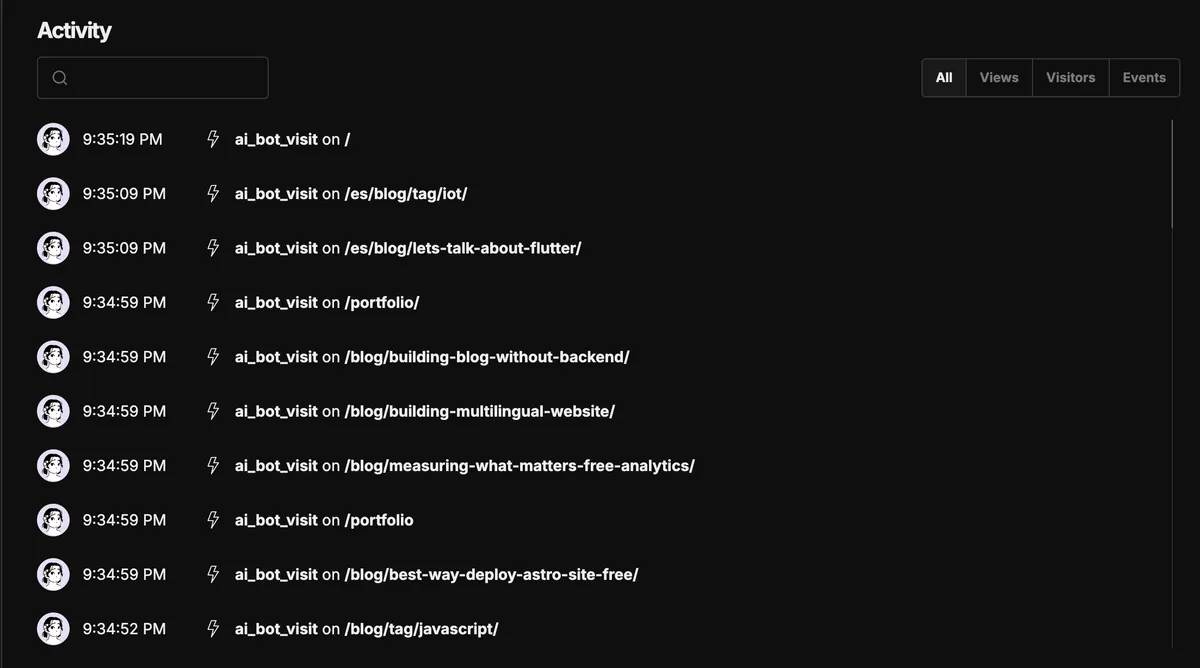
Así se ve el feed de actividad — cada evento ai_bot_visit con la página que el bot rastreó:
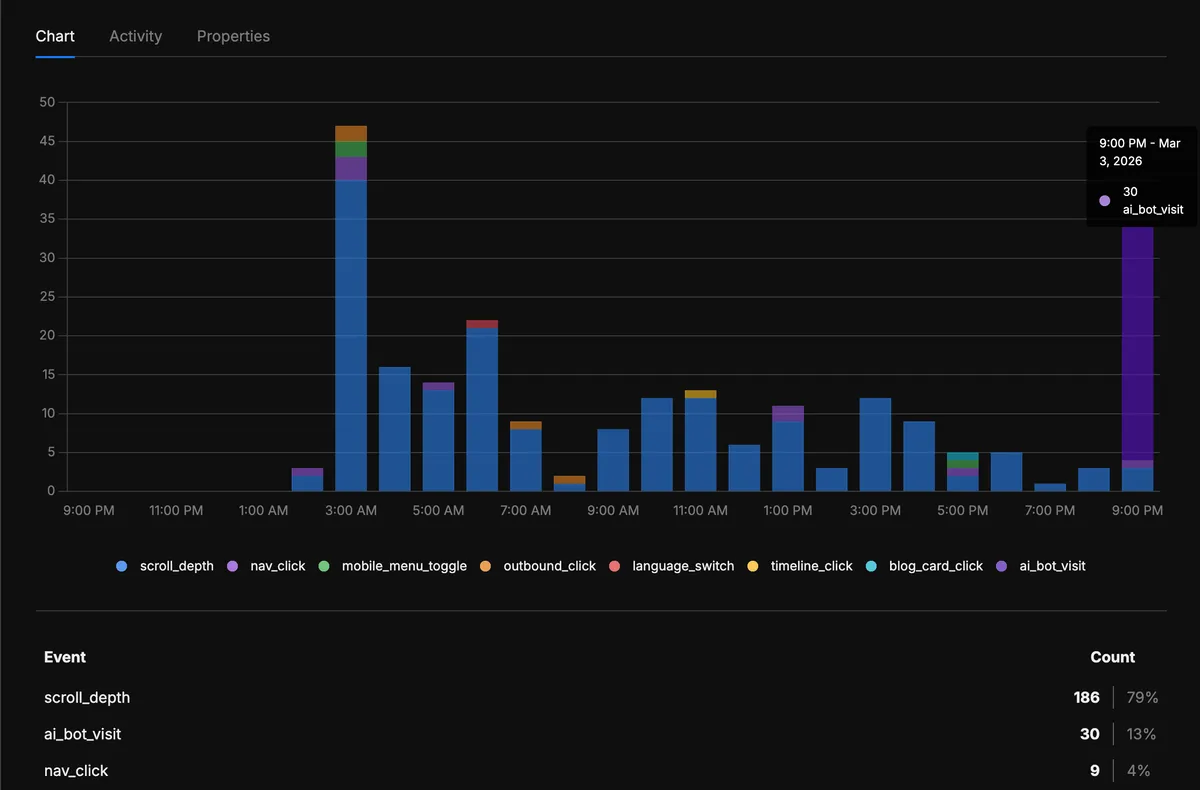
Y en el gráfico de eventos, los ai_bot_visit empiezan a aparecer junto al resto de analíticas del sitio — mismo dashboard, misma línea de tiempo:
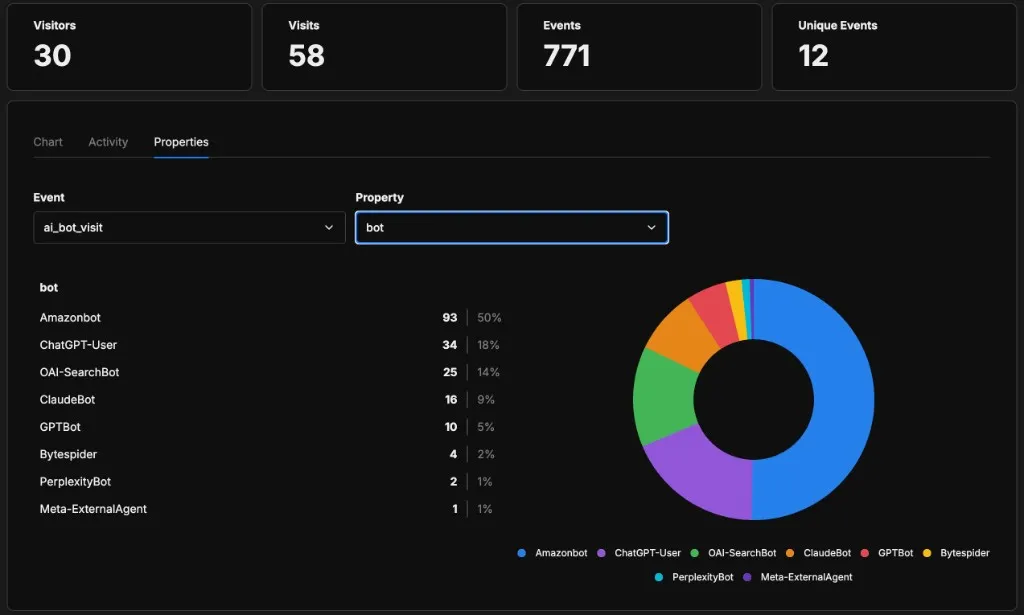
Como cada evento lleva la propiedad bot, puedo desglosar el tráfico por crawler. Filtrando por la propiedad bot en ai_bot_visit me da esto — una imagen clara de quién está entrando realmente por la puerta:
Con analíticas del lado del cliente nada de esto existía. Con un archivo de middleware, ahora sí.
Atrapando a los Que Aún No Conozco
Estaba bastante contento con el sistema hasta que me di cuenta de algo obvio que había pasado por alto: esta cosa solo rastrea bots que ya conozco. Doce nombres en una lista. Si mañana alguna empresa nueva de IA lanza un crawler llamado DeepLoQueSeaBot, pasa derecho por detectAiBot(), recibe un null, y se esfuma. Había construido un fix para un punto ciego que tenía su propio punto ciego.
Había cinco o seis crawlers de IA cuando armé la primera versión de robots.txt. Ahora hay doce. Para cuando leas esto, quién sabe. La lista siempre va a ir por detrás.
El fix fue bastante simple — después de que el chequeo de bots conocidos falla, buscar señales genéricas de bot en el User-Agent. Si la cadena contiene bot, crawler, spider, scraper, o fetcher, probablemente no es el Chrome de alguien:
const BOT_KEYWORD_PATTERN = /bot[\/\s;)]/i;
const SPIDER_CRAWLER_PATTERN = /crawler|spider|scraper|fetcher|agent[\/\s;)]/i;
function isUnknownBot(userAgent: string): boolean {
if (!userAgent || userAgent.length < 5) return false;
if (IGNORED_BOTS_PATTERN.test(userAgent)) return false;
return BOT_KEYWORD_PATTERN.test(userAgent)
|| SPIDER_CRAWLER_PATTERN.test(userAgent);
}Tuve que agregar una lista de cosas obvias que ignorar — Googlebot, Bingbot, YandexBot, monitores de uptime como UptimeRobot y Pingdom. Esos no son lo que busco, y loguearlos ahogaría la señal en ruido.
Los bots desconocidos tienen su propio evento: unknown_bot_visit, separado de ai_bot_visit. La cadena completa de User-Agent va en las propiedades del evento — quiero ver exactamente qué apareció, no solo que algo lo hizo. El middleware agarra un nombre legible del primer token:
function extractBotName(userAgent: string): string {
const match = userAgent.match(/^([^\s\/]+)/);
const name = match ? match[1] : userAgent;
return name.slice(0, 60);
}Entonces el manejador de solicitudes ahora tiene dos caminos:
export async function onRequest(context: EventContext): Promise<Response> {
const userAgent = context.request.headers.get('user-agent') || '';
const botName = detectAiBot(userAgent);
if (botName) {
// Bot de IA conocido → rastrear como ai_bot_visit
// ...
return context.next();
}
// Chequear bots desconocidos
if (isUnknownBot(userAgent)) {
const name = extractBotName(userAgent);
// Rastrear como unknown_bot_visit con User-Agent completo adjunto
// ...
}
return context.next();
}Ahora cuando algo nuevo aparezca rastreando el sitio, lo voy a ver en Umami bajo unknown_bot_visit. Si resulta ser un crawler de IA que vale la pena rastrear formalmente, lo promuevo: una línea a AI_BOT_PATTERNS, una línea a robots.txt. Eso es todo. La primera versión solo podía ver lo que le dije que buscara. Esta también me puede decir qué me estoy perdiendo.
Mi hipótesis era que los posts del blog dominarían el tráfico de bots — el texto largo es lo que más scrapean los modelos de lenguaje. También esperaba que llms.txt recibiera visitas de crawlers haciendo un inventario rápido. Si es así, los datos lo van a mostrar.
A seguir construyendo.
Recursos

Sergio Alexander Florez Galeano
CTO y Cofundador en DailyBot
Ingeniero de software y emprendedor colombiano (DailyBot, YC S21). Escribo sobre agentes de IA, herramientas para desarrolladores, startups y el arte de la ingeniería de software, y construyo este sitio a la vista de todos en XergioAleX.com.
Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.