
The web didn’t break overnight. It shifted.
In 2012, Google started answering some queries directly in the search results page — Knowledge Graph panels. In 2014, Featured Snippets appeared. Each step moved the answer slightly closer to the user and slightly further from your site. Then in May 2023, Google launched the Search Generative Experience — later renamed to AI Overviews — and the shift accelerated past the point where you could ignore it.
The question used to be: “How do I rank?” Now there’s a second question that matters just as much: “How do I get cited?”
This post covers both the shift and the first practical response to it — two foundations that every site should have in place before worrying about anything more sophisticated.
The Shift
Traditional search volume is declining, AI answer engines are absorbing millions of queries per day, and most of those interactions never produce a click. The numbers are no longer projections — they’re current reality.
Everything we know as SEO — keywords, backlinks, meta tags, page speed, mobile-friendly design — was built around one model: get your link higher on a list of results. That model is breaking.
US desktop searches per user are already down 20% year over year. And the problem isn’t just that people search less — it’s what happens when they do. AI Overviews appear in half of US searches, and when they do, 83% end without a click. The user gets the answer right there. The list of links below — the list we spent years optimizing for — doesn’t get touched.
And that’s just Google. Hundreds of millions of people no longer even go through a search engine — they ask ChatGPT, Perplexity, or Claude directly and get a synthesized answer with citations. SEO isn’t dead, but it’s no longer enough on its own.
And this isn’t just hitting small sites. In January 2026, Adam Wathan — creator of Tailwind CSS — revealed he had to lay off 75% of his engineering team due to what he called the “brutal impact” of AI on his business. The headline sounds dramatic until you see the numbers: the engineering team was 4 people — he laid off 3, leaving 1. Documentation traffic had dropped 40% over two years, and revenue was down 80%. The paradox: Tailwind as a framework was growing faster than ever. But developers had stopped visiting the site — Cursor, GitHub Copilot, and ChatGPT were answering their questions right in the editor. The funnel that converted documentation visits into paid product sales simply broke. It all blew up when Wathan closed a GitHub PR that proposed making the docs more LLM-friendly, arguing that making it easier for models to read the docs just meant less traffic and less revenue. The thread accumulated hundreds of comments, the repo went private temporarily, and the story hit Hacker News with over 1,100 points. As Wathan said on his podcast: “Tailwind is growing faster than it ever has and is bigger than it ever has been, and our revenue is down close to 80%.” The story had a happy ending — Vercel, Google, and other companies stepped in to sponsor the project, and Tailwind survived. But the business model that sustained it no longer exists, and whatever comes next will have to look very different. It’s perhaps the most visible example of what this shift looks like in practice.
AEO Didn’t Come Out of Nowhere
Before getting into the practical foundations, it’s worth knowing this already has research behind it.
A Princeton University paper published at KDD 2024 demonstrated that specific optimization strategies can boost visibility in generative engine responses by up to 40%. They call it GEO (Generative Engine Optimization), others call it LLMO — SEMrush and Ahrefs already have comprehensive guides on the topic under different names. In the end, they’re all talking about the same thing: optimizing for engines that give answers instead of links.
The first two foundations any site can put in place are simpler than they look.
The Answer Engines
Not all AI answer engines work the same way. Understanding how Google AI Overviews, ChatGPT, Claude, and Perplexity crawl and retrieve content is the first step to making your site visible to them — and it starts with your robots.txt.
To optimize for answer engines, it helps to understand how they actually work. Not all of them operate the same way. I spent more time digging into crawler docs than I expected — the differences matter.
Google AI Overviews don’t use a separate crawler. If Googlebot has already indexed your page, you’re eligible. What’s interesting is their “query fan-out” technique — when building an answer, the system fires multiple related sub-queries. A page ranking position 40 for a related topic can end up cited in the primary answer. The content that works best are specific, self-contained answer blocks — paragraphs that answer a concrete question without depending on surrounding context. Some analyses suggest the ideal range is between 134 and 167 words per block.
ChatGPT runs three separate crawlers, each independently controllable: GPTBot for training, OAI-SearchBot for its search index, and ChatGPT-User for real-time browsing. You can block training while allowing search — they’re separate decisions. Most people don’t realize this.
Claude also has three bots — ClaudeBot, Claude-SearchBot, and Claude-User. Its web search is powered by Brave Search. All three respect robots.txt, including Crawl-delay.
Perplexity uses PerplexityBot for indexing (explicitly not for model training) and Perplexity-User for real-time queries. It favors factual density, recency, and clean HTML structure. Its top cited domains? Reddit, YouTube, and Gartner — not exactly a traditional SEO leaderboard.
Allowing AI crawlers in robots.txt is the foundation — and a surprisingly active decision. This site explicitly allows 13 crawlers:
# AI/LLM Crawlers - Explicitly allowed
User-agent: GPTBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: anthropic-ai
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
# ... plus Bytespider, CCBot, Applebot-Extended, Amazonbot, Meta-ExternalAgent, cohere-aiI chose to allow everything — both training and search crawlers. For a personal site, visibility matters more than opting out of data usage I can’t control anyway. A commercial site might think differently — blocking GPTBot for training while allowing OAI-SearchBot for citations. The point is that these are independent decisions now, and “do nothing” is also a decision.
One thing worth noting: Apple is building its own AI search system. “World Knowledge Answers” is expected in iOS 26.4, powered partly by Google’s Gemini models. Their Applebot-Extended crawler is already evaluating content for AI training. By the time it launches, sites that already allow Applebot will be in the index. Sites that don’t won’t.
The First Foundation: Giving AI a Menu
Getting on the allowlist means AI bots can visit. But showing up and being understood are different things — a lesson I learned more slowly than I should have. A crawler that lands on a page full of Tailwind classes, SVG icons, and navigation markup has to dig through a lot of noise to find the actual content.
That’s where llms.txt comes in.
The llms.txt specification was proposed by Jeremy Howard in September 2024. The premise is simple: instead of making a language model crawl your entire site to understand what’s there, you hand it a structured index — a Markdown file at /llms.txt that gives AI systems a curated summary of your site. What it covers, how it’s organized, where to find things. About 10-30 lines and takes a few minutes to write.
Adoption is still early — Semrush reports only about 951 domains had published an llms.txt file as of mid-2025. Early adopters are mostly developer-facing: Anthropic, Cloudflare, Vercel, Supabase.
In June 2025, Google’s John Mueller said “no AI system currently uses llms.txt.” But since then, Cloudflare launched Markdown for Agents and the ecosystem moved fast — tools like Cursor, Claude, and other code agents already consume Markdown files as a primary context source. llms.txt fits exactly in that direction.
I think of it like sitemap.xml for the AI era: the cost is a few lines of Markdown, and if the pattern consolidates — which all signs suggest it will — the information is already there.
Here’s what this site’s looks like:
# XergioAleX.com
> Personal website and technical blog by Sergio Alexander Florez Galeano
> (XergioAleX): CTO & Co-founder at DailyBot (Y Combinator S21).
## Core Sections
- Home: /
- Blog: /blog/
- About: /about/
- Portfolio: /portfolio/
...
## Blog Tags
- tech — Software development tutorials and technical articles
- ai — Artificial intelligence and machine learning content
...
## Blog Series
- Building XergioAleX.com (8 chapters)
- Trading Journey (3 chapters)
## Crawling Guidance
- All public content is intended for indexing by search engines and LLM systems.
- Structured data (JSON-LD) is embedded on all pages for machine consumption.
## Detailed Version
For comprehensive content descriptions, see: /llms-full.txtThere’s also a llms-full.txt — 130 lines with detailed page descriptions, topic areas, and the full tech stack. No AI crawler consumes it automatically yet — but developers already use it manually as context in tools like Cursor, and platforms like Mintlify generate it by default for all their hosted documentation. The pattern is gaining traction even if search engines haven’t formally adopted it yet.
The Second Foundation: Speaking Their Vocabulary
This is where AEO gets concrete — and, honestly, a little tedious.
Structured data is E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness — encoded in a format machines can parse directly. Pages with schema markup have 2.8x higher AI citation rates. Google, Microsoft, and OpenAI all use structured data in their generative AI features. Sites with structured data and FAQ blocks show measurably higher AI citation rates compared to those without.
The most important schema on this site is the Person type — it ships on every single page:
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Sergio Alexander Florez Galeano",
"alternateName": "XergioAleX",
"url": "https://xergioalex.com",
"image": "https://xergioalex.com/images/profile.png",
"description": "CTO & Cofounder of DailyBot (Y Combinator S21). Computer Science Engineer, MSc in Data Science, with 14+ years building digital products.",
"jobTitle": "CTO & Co-founder",
"worksFor": {
"@type": "Organization",
"name": "DailyBot",
"url": "https://dailybot.com"
},
"alumniOf": [
{ "@type": "Organization", "name": "Y Combinator" },
{ "@type": "CollegeOrUniversity", "name": "Universidad Tecnológica de Pereira" }
],
"knowsAbout": [
"Software Engineering", "Artificial Intelligence", "Web Development",
"DevOps", "Blockchain", "Algorithmic Trading", "Startup Building"
],
"sameAs": [
"https://github.com/xergioalex",
"https://www.linkedin.com/in/xergioalex/",
"https://x.com/XergioAleX",
"https://www.instagram.com/xergioalex"
]
}Every field serves a purpose. alumniOf with Y Combinator — institutional credibility. worksFor — current professional context. sameAs with four social profiles — identity verification across platforms. knowsAbout — topic authority signals. None of this is decorative. Each field is something an AI system can use when deciding whether to cite this site as a source.
Structured data took a considerable amount of time. It’s not exciting work — writing JSON schemas, validating them in the Schema.org Validator to verify the structure is correct, making sure each page has the right types.
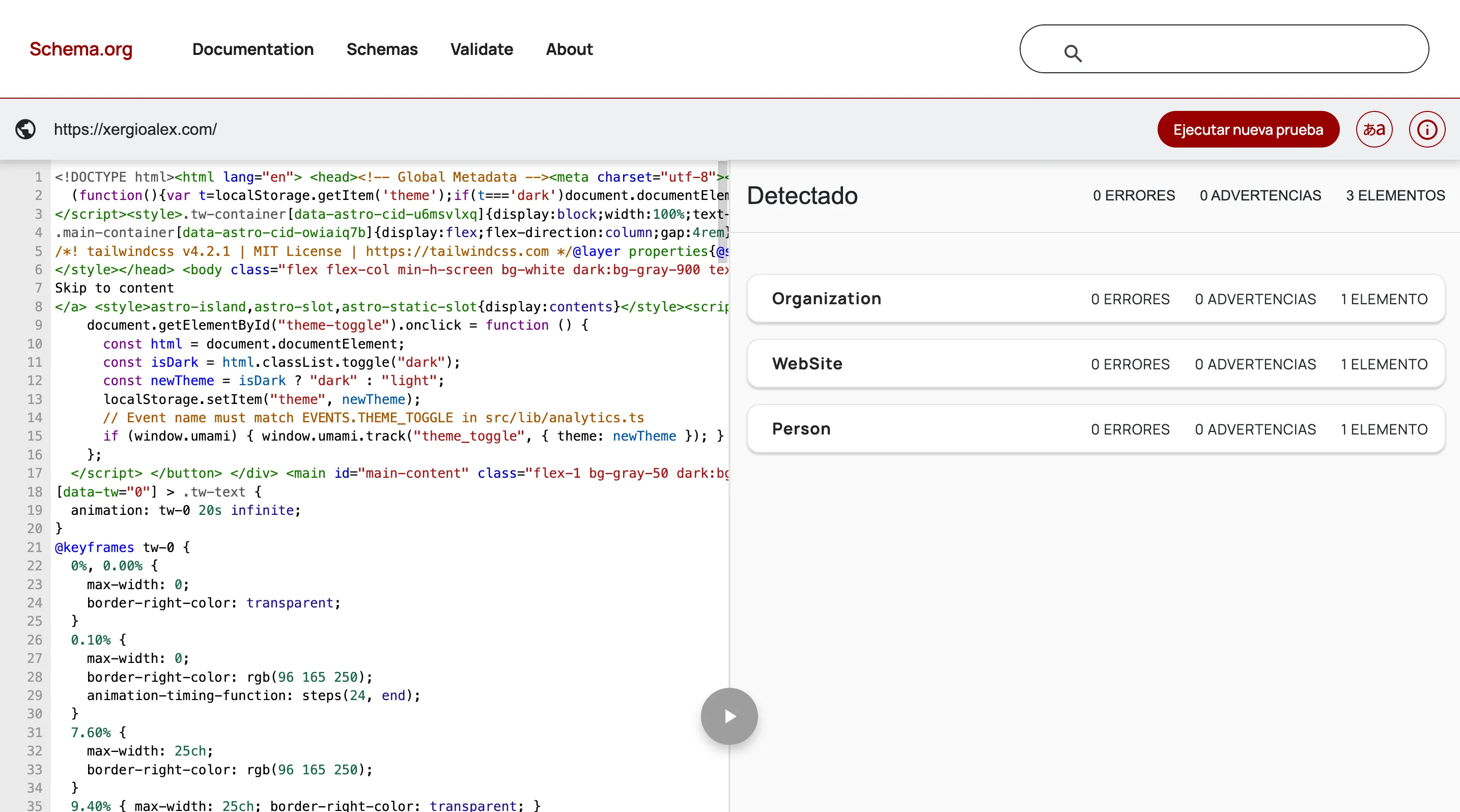
On a blog post it gets more interesting — on top of the base schemas, BlogPosting and BreadcrumbList show up:
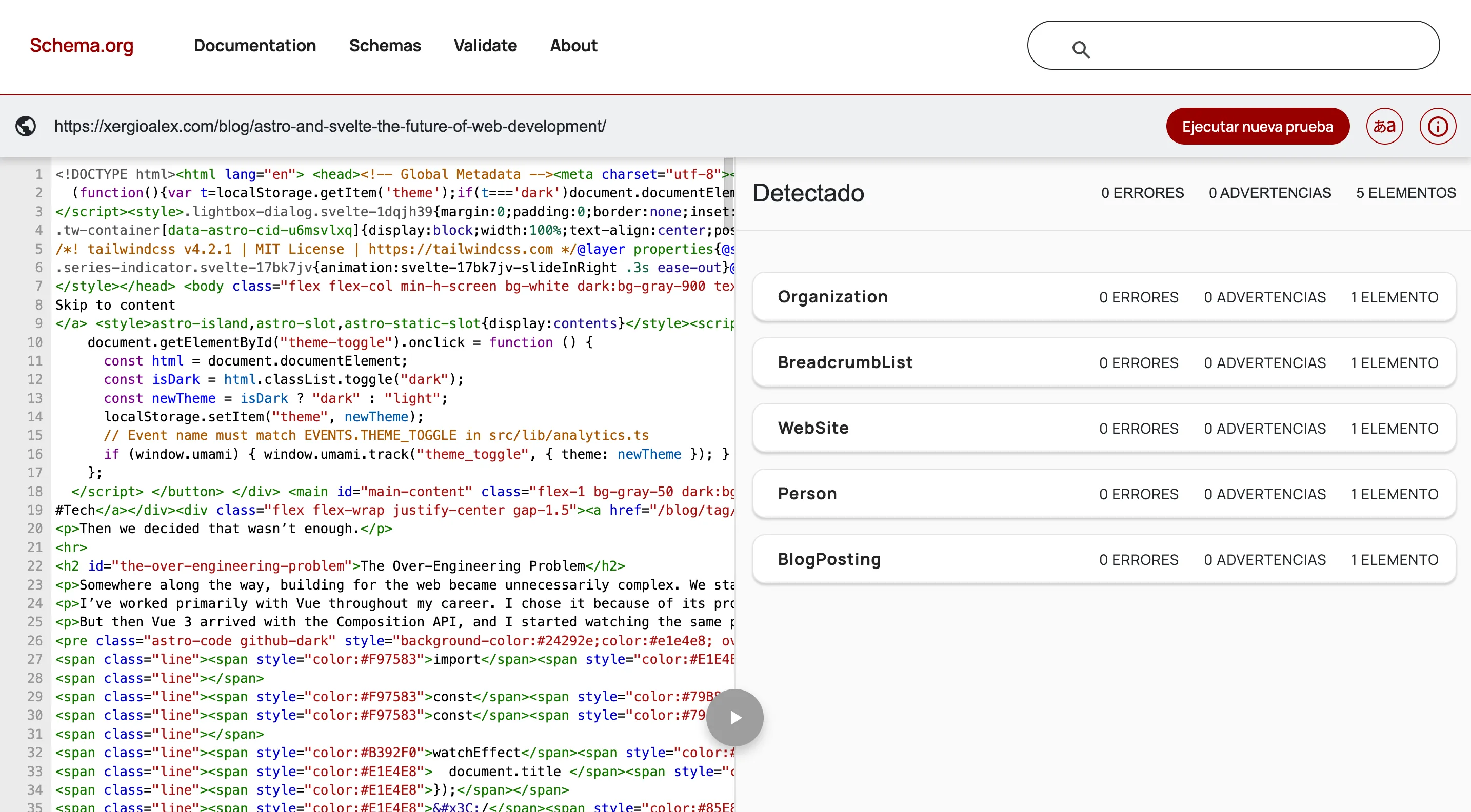
Expanding BlogPosting reveals everything AI can read without parsing HTML: title, description, image, publication and modification dates, keywords, word count — each field is an explicit signal that saves the model from having to infer it.
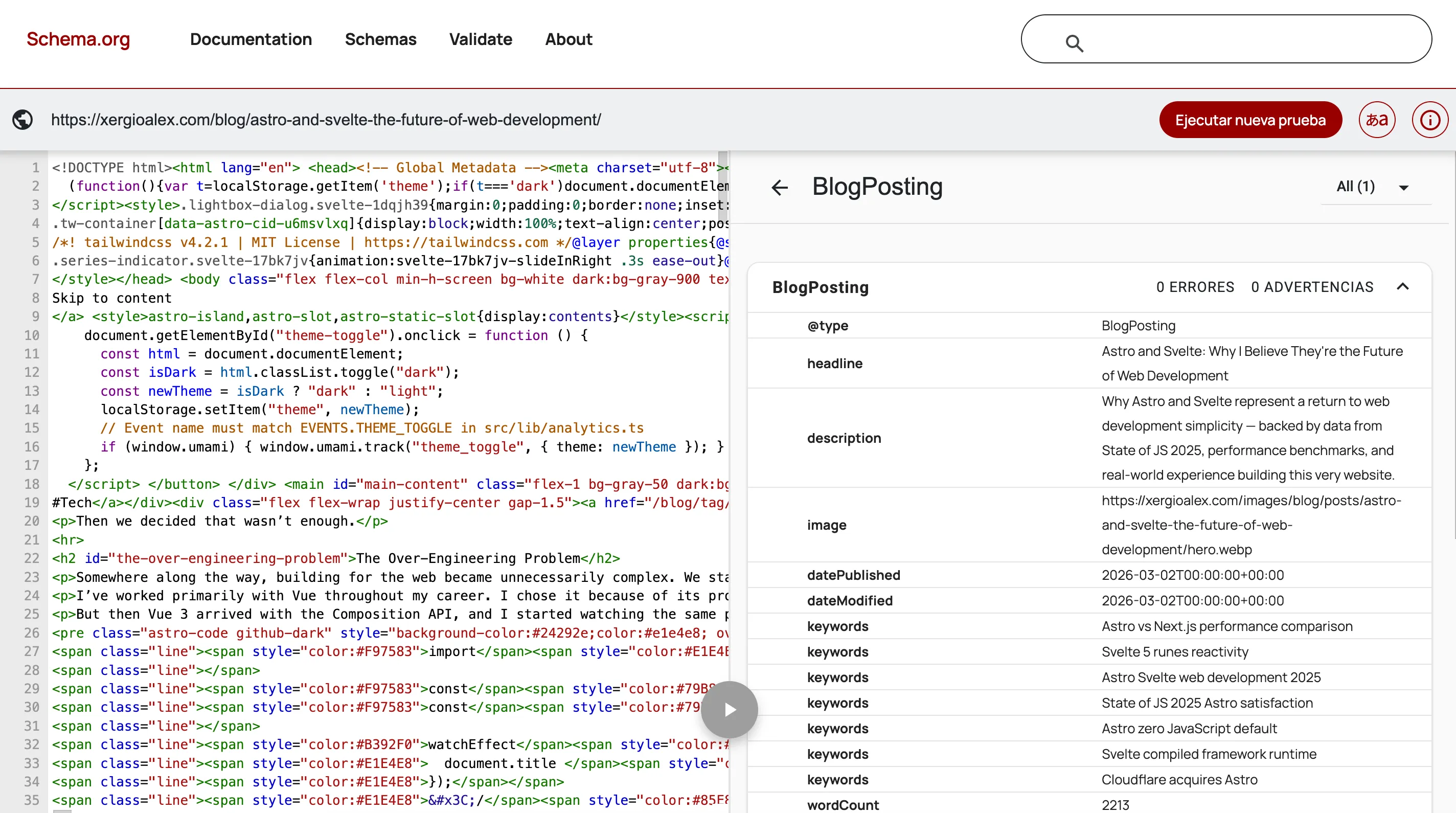 I spent an afternoon on the
I spent an afternoon on the BlogPosting schema alone, cross-referencing the schema.org spec to check which properties were actually used by AI systems versus which ones were just technically valid but ignored. Most of the first draft was wrong in small ways. Going back through documentation I’d already read once wasn’t fun.
But it’s the one optimization that directly communicates meaning to machines — not just content, but context. Who wrote this, why they’re qualified to write it, when it was last updated. That’s the layer that matters.
Beyond the Person schema, this site has 9 JSON-LD types in total: BlogPosting (with wordCount, timeRequired, dateModified, and nested author data), BreadcrumbList on every page, Organization for DailyBot, WebSite, CollectionPage, ContactPage, and ProfilePage.
What Comes Next
The foundations are in place: crawlers allowed, a menu in /llms.txt, structured data on every page. But crawlable and machine-readable are still just table stakes — they get you into the game. The more interesting frontier is giving AI agents a direct channel to your content, bypassing HTML parsing entirely with native Markdown endpoints.
That’s what the next chapter covers: Markdown for Agents: Making Your Content Speak AI’s Language. Let’s keep building.
Resources
Research & Data
- Princeton GEO Paper — Generative Engine Optimization (KDD 2024)
- Search Engine Land: US Desktop Searches Declining
- Demand Sage: AI Overviews Statistics
- Demand Sage: Perplexity AI Statistics
- DevClass: Tailwind Labs Lays Off 75% of Engineers Due to AI Impact
- GitHub: Tailwind CSS LLM-Friendly Docs Discussion
- AirOps: Schema Markup and AI Citation Rates
- BrightEdge: Schema and AI Overview Visibility
Definitions & Guides
- SEMrush: Answer Engine Optimization
- Ahrefs: Answer Engine Optimization
- Search Engine Land: AAO — Assistive Agent Optimization
- Ahrefs: Search Rankings vs AI Citations
Standards & Specifications
- llms.txt Official Specification
- Schema.org
- SEMrush: llms.txt Adoption Report
- Stackmatix: Structured Data in AI Search (Google, Microsoft, OpenAI)
- Google: Structured Data Introduction
Crawler Documentation
- OpenAI Crawlers
- Anthropic Crawlers
- Perplexity Crawlers
- Google: Succeeding in AI Search
- Apple World Knowledge Answers
Tools

Stay in the loop
Get notified when I publish something new. No spam, unsubscribe anytime.
No spam. Unsubscribe anytime.