
In April I wrote about a model too dangerous to release. Anthropic had built something that found thousands of unknown security flaws in every major operating system. They assembled a $100 million coalition, restricted access to fifty partners, and said the responsible thing to do was keep it locked away. That post ended with “this is just the beginning.”
In June, Anthropic released that model. Same weights. Same architecture. Same brain that found a 28-year-old bug in OpenBSD for fifty bucks. They renamed it Claude Fable 5, wrapped it in a layer of safety classifiers, and published it on the API — within reach of anyone with a credit card. The model too dangerous to release became a model you can just talk to.
How does a model go from “too dangerous for anyone” to “available everywhere” between April and June? That’s the question this post takes apart: what actually changed, what the model can do, and what it means for those of us building with these tools.
What Changed
The short answer: the model didn’t change. The harness did — the system of controls wrapped around it. Think of the difference between a Formula 1 engine sitting loose on a workbench and that same engine inside a car with brakes, a seatbelt, and airbags.
Three things happened between April and June. First, Project Glasswing expanded. The coalition of defenders that got access to the restricted model grew from fifty partners to roughly two hundred organizations across more than fifteen countries: power companies, water utilities, hospitals, hardware makers. The infrastructure you depend on every day without thinking about it. In that window they found more than ten thousand serious security flaws. Ten thousand. The model doing exactly what it was built to do: finding the holes before someone with bad intentions does.
Second, Anthropic built the safety layer. The centerpiece is a set of classifiers: filters that screen every query before it gets answered and flag the delicate territory — hacking systems, biology, chemistry, or attempts to copy the model to train another one. When none of them fire, Fable 5 answers at full power. When one does, the answer comes from Claude Opus 4.8, the previous-generation model: still excellent, just one step down. It’s not a refusal — you don’t hit a wall or get an “I can’t help with that.” It’s the engine shifting down a gear right at the dangerous curve. And to prove the layer holds, they offered bounties to outside experts for breaking it: over a thousand hours of jailbreak attempts — the art of tricking an AI into ignoring its own rules — and nobody found a universal way through.
Third — and this is where it all clicks — they measured how often those filters actually trip. Less than five percent of sessions. The rest of the time — more than ninety-five percent — you’re talking to the full model with nothing in between. The leash exists, but you almost never feel it.
But when the leash matters, it really matters. There’s a test called ExploitBench that measures exactly what made Mythos terrifying: its ability to hack. Mythos 5 — the unfiltered version that Glasswing defenders get — scores 78 out of 100. Fable 5, the same model with the filters on, scores zero. Same weights. Same brain. On that one subject, the filters take it from best in the world to nothing. The whole design summed up in two numbers: full power at everything, except the one thing that can be used as a weapon.
Even the names tell the story. Anthropic explains in a footnote that Fable comes from the Latin fabula — “that which is told” — a close cousin of the Greek mythos. The same story, told two ways. Mythos 5, unfiltered, for the cyberdefenders. Fable 5, filtered, for everyone else. CyberScoop dubbed it “Mythos on a leash,” and honestly, that’s the most accurate two-word summary I’ve seen.
April and June, side by side:
| April — Mythos Preview | June — Fable 5 | |
|---|---|---|
| Who can use it | ~50 vetted partners | Anyone with an API key |
| Price (per million tokens) | $25 in / $125 out | $10 in / $50 out |
| Project Glasswing | 12 founding partners + 40 orgs | ~200 organizations in 15+ countries |
| Hacking capability | Full, behind vetting | Behind filters — reserved for Mythos 5 |
Every row moves in the same direction: more access, lower cost, and tighter control over the one capability that scared everyone.
What It Can Do
You don’t need another wall of benchmarks. What’s worth your time is what companies reported when they got early access.
Stripe took a fifty-million-line Ruby codebase and ran a full migration in one day. Their team estimated that same migration would have taken over two months by hand. Cursor’s CEO said Fable 5 opened “a class of long-horizon problems that were out of reach for earlier models.” One of Anthropic’s early-access partners reported that on frontier physics research, Fable 5 got in 36 hours nearly to where GPT-5.5 landed after four days — using a third of the reasoning tokens.
If you write software, there’s one benchmark worth knowing: SWE-bench Pro, which throws hard, multi-step software problems at models. Fable 5 scores 80.3%. Opus 4.8 gets 69.2%. GPT-5.5 lands at 58.6%. That’s not an incremental lead. That’s a gap where the model is solving problems the others can’t.
That gap is easiest to see in a chart. FrontierCode is an exam built from the 50 hardest programming problems out of a bank of 150 — hard enough that every model still fails more than it succeeds. The test lets each model spend more or less effort thinking, and measures what that spending buys:
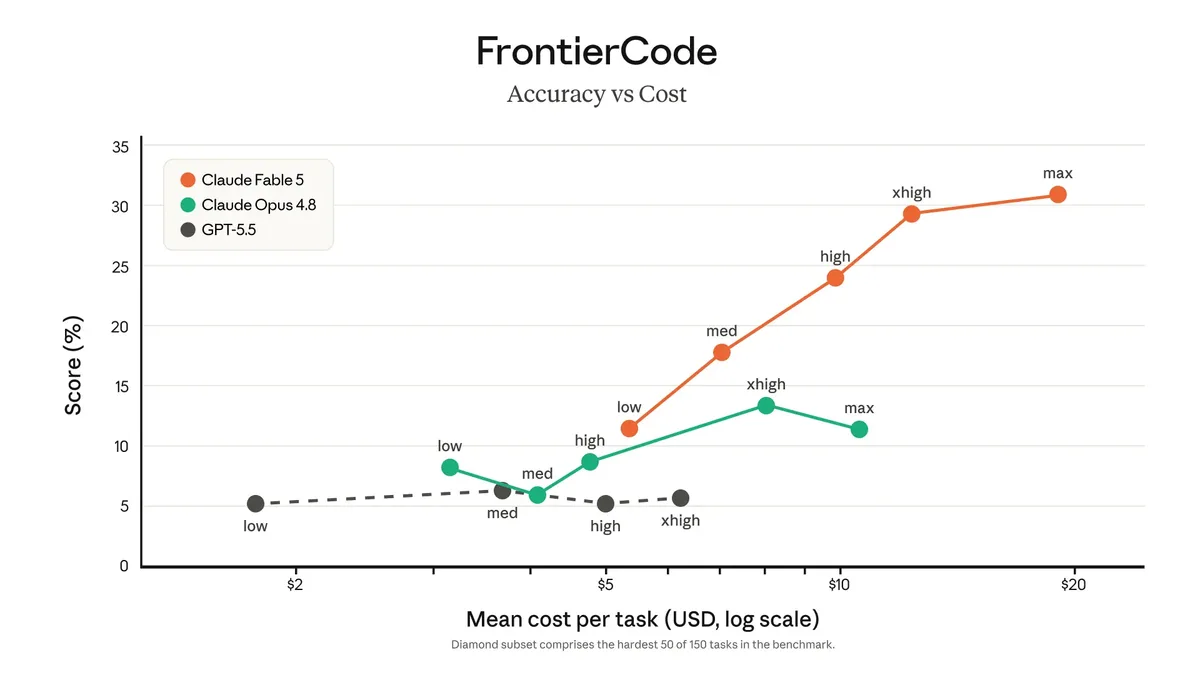
Look at the three curves. GPT-5.5 (gray) doesn’t move: spend whatever you want, it hovers around 5%. Opus 4.8 (green) improves up to a point and plateaus near 13% — it goes no further, no matter how much you give it. Fable 5 (orange) is the only one still climbing: every extra dollar of effort turns into more problems solved, all the way up to 31%. That’s what a higher ceiling looks like: it’s not that it’s cheaper — it’s that it’s the only one where giving it more still pays off.
And it’s not just code. Anthropic’s biology partners used it to speed up parts of drug design roughly tenfold, and in one genomics project it built a custom machine-learning model that outperformed a published Science result while being a hundred times smaller. My favorite demo is more modest than any of that: asked for a 3D-printable design, it built the CAD editor first, then designed the part in it. The tool didn’t exist, so it made the tool.
And then there’s the Pokémon thing. Earlier Claude models couldn’t beat Pokémon FireRed even with an elaborate helper system giving them maps, navigation tools, and extra game state. Fable 5 beat the game with nothing but raw screenshots — a minimal, vision-only setup. It feels like a toy benchmark until you realize what it actually tests: sustained autonomous reasoning over hundreds of sequential decisions, with no scaffold to lean on.
That last part is the one to pay attention to. It’s not that the model is smarter at any single step — it’s that it stays coherent over longer horizons without drifting. If you’ve ever watched an agent lose the thread halfway through a task, you know exactly what that’s worth.
The Working Horizon
The obvious question is what changes compared to Opus 4.8, which could already work on its own for hours — and did it well. The difference isn’t stamina, it’s capability. The longer and messier a task gets, the more it demands from the model: every decision depends on the ones before it, and small errors compound. Opus finishes the marathon on flat ground. Fable 5 runs it in the mountains: bigger plans, messier problems, hundreds of chained decisions — and it reaches the end with the goal intact.
That changes the size of what you can delegate. Work that used to be split into pieces — an entire refactor, a migration, a full test suite — now gets handed over whole and picked up finished at the end of the day. The difference isn’t how many hours it works. It’s how big a problem it can hold in its head from start to finish.
What This Actually Means
Strip away the launch noise and one idea is left standing.
The same model is the weapon and the tool. The intelligence that found thousands of zero-days is the same intelligence migrating a fifty-million-line codebase. The brain that could chain four separate vulnerabilities into a full system takeover is the same brain that stays coherent across hundreds of coding decisions. Security capabilities and general capabilities are not separate things. They’re the same thing — deep autonomous reasoning — pointed in different directions.
The only difference between the model too dangerous to release and the model anyone can use is the system wrapped around it. Not the weights. Not the training. The harness.
That validates something I keep coming back to in my writing about working with agents. The model isn’t where the value lives anymore. The system around the model is. Anthropic just proved it at the grandest scale imaginable: you can take the most dangerous model ever built and make it safe for general use by building a better harness. The model didn’t change. Everything around it did.
The Business Move
There’s also a business story here, and the timing tells it on its own. Anthropic confidentially filed their IPO prospectus the same week they expanded Glasswing. A week after that, they released the model to the public. They priced it at $10 per million input tokens and $50 per million output — less than half what Mythos Preview cost. It launched on AWS Bedrock, GitHub Copilot, Vertex AI, and Microsoft Foundry from day one — and even Claude subscription plans got it included at no extra cost during the launch window.
That’s not cautious distribution. That’s maximum reach on day one. They went from “nobody can have this” in April to “everyone can have this, on every platform” in June. The safety layer didn’t just solve a technical problem. It solved a business problem.
And there’s a harder question underneath: what does it mean that you can now rent the most capable model ever built for ten dollars per million tokens? The asymmetry that made Mythos scary — an AI finding critical vulnerabilities for fifty dollars — doesn’t go away because the model changed its name. It just means the same asymmetry now applies to every problem, not just security. The cost of solving hard problems with the most capable AI model available dropped by more than half between April and June.
What Comes Next
Honestly? Nobody knows. Anyone selling you a confident prediction here is guessing.
What we do know: in April, a model that was too powerful to release existed behind a locked door. In June, that model was running on my machine. The gap between “frontier capability” and “generally available” compressed from years to months. If Fable 5 is what happens when you build a safety layer around Mythos Preview, what happens when the next Mythos-class model arrives and the safety layer is already built?
The pace hasn’t slowed down. If anything, this release proves it’s faster than the timeline I mapped out when I first wrote about the silent revolution. The revolution keeps getting louder.
Let’s keep building. Carefully, still — but the door is open.
Update — June 12, 2026: The US Government Pulls the Plug
I wrote above that “the door is open.” Three days after the public launch, the US government closed it.
On June 12, 2026, Anthropic disabled both Fable 5 and Mythos 5 for every customer after receiving an export control directive from the US government. The order required suspending access for any foreign national — inside or outside the United States, including Anthropic’s own non-US employees. Because Anthropic couldn’t guarantee it could block every non-US national from the models, it switched both off entirely rather than try to segment access by nationality. Every other Claude model — Opus 4.8 included — stayed online.
This is, as far as anyone can tell, the first time the US has used export control authority to pull a specific frontier AI model on national security grounds. The reported trigger was a foreign company with access to Mythos and suspected ties that raised national security flags. The government’s stated concern was a possible way to bypass — “jailbreak” — Fable 5’s cyber safeguards: the exact safety layer this whole post is about. Anthropic says it reviewed the demonstration and found a narrow, non-universal trick that surfaced a few already-known, minor vulnerabilities — and disagreed that a finding that narrow justifies recalling a model already deployed to hundreds of millions of people.
The irony is hard to miss. The whole argument of this post is that the harness — not the weights — is what makes a dangerous model safe to ship. The government’s move is, in its own way, a vote of no confidence in exactly that harness. The leash held against a thousand hours of bounty-funded jailbreak attempts; it took a government directive, not a broken filter, to take the model off the table.
As of this writing, Anthropic says it considers this a misunderstanding and is working to restore access, and an executive told press in Seoul the company is confident the models will return “in the coming days.” Whether they come back unchanged, with a tighter harness, or under new access rules is the part nobody can answer yet. I’ll update this post again when there’s something solid to report.
The door was open for three days. What happens next is the real story.
Resources
- Claude Fable 5 and Claude Mythos 5 — Anthropic — Official launch announcement with benchmarks, safeguards, and availability details
- Expanding Project Glasswing — Anthropic — June 2026 expansion adding ~150 organizations across power, water, healthcare, and hardware in 15+ countries
- Claude Fable 5 on AWS — AWS News Blog — Bedrock availability and integration details
- Claude Fable 5 for GitHub Copilot — GitHub Changelog — Copilot integration and data retention policy
- Anthropic’s new model is Mythos on a leash — CyberScoop — Security analysis of the safeguard architecture
- Claude Fable 5 & Mythos 5: The Frontier, Split in Two — Digital Applied — Detailed benchmark comparison across frontier models
- Claude API Models Overview — Anthropic Docs — Technical specs, pricing, and API identifiers
- Statement on the US government directive to suspend Fable 5 and Mythos 5 access — Anthropic — June 12, 2026 statement on the suspension and Anthropic’s response
- Anthropic Suspends Access to Fable 5 and Mythos 5 Following US Export Control Directive — National Law Review — Legal analysis of the first export-control action against a specific frontier model
- Anthropic disables Fable and Mythos after US bars foreign access — Fortune — Reporting on the directive, who is affected, and the national-security rationale

Sergio Alexander Florez Galeano
CTO & Co-founder at DailyBot
Colombian software engineer and entrepreneur (DailyBot, YC S21). I write about AI agents, developer tools, startups, and the craft of software engineering — and I build this site in the open at XergioAleX.com.
Stay in the loop
Get notified when I publish something new. No spam, unsubscribe anytime.
No spam. Unsubscribe anytime.