
La parte más difícil del AEO es la medición. Google Analytics no ve los bots de IA. No ejecutan JavaScript. Desde la perspectiva de las analíticas del lado del cliente, cada visita de un crawler de IA es completamente invisible — un agujero negro al que va tu mejor contenido y del que no sabes nada de lo que pasa después.
Pasé bastante tiempo tratando de entender qué significa siquiera “funcionar” en el contexto del AEO. Con el SEO tradicional tienes rankings, CTR, impresiones. Con el AEO tienes… intuición. Alguien te dice que te encontró en ChatGPT. Buscas tu propio nombre en Perplexity y a veces apareces, a veces no. El ecosistema de medición está años por detrás del ecosistema de optimización, y esa brecha es frustrante para todos — no solo para mí.
Este capítulo trata de cerrar esa brecha tanto como es posible actualmente, y es honesto sobre cuánto camino falta recorrer todavía.
Rastrear el Tráfico de Bots IA
El único lugar donde puedes interceptar los crawlers de IA es del lado del servidor, antes de que salga la respuesta. Las analíticas del lado del cliente nunca los ven — no ejecutan JavaScript, así que herramientas como Google Analytics ni saben que existen.
El enfoque que construí para este sitio es un middleware de Cloudflare Pages que corre en el edge con cada solicitud. Verifica el header User-Agent contra una lista de patrones de bots de IA conocidos — GPTBot, ChatGPT-User, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, OAI-SearchBot, Amazonbot, Meta-ExternalAgent, Bytespider, y algunos otros. Cuando hay coincidencia, dispara un evento ai_bot_visit a Umami (mi plataforma de analíticas) con el nombre del bot, la ruta de la página y el método HTTP. Los visitantes humanos pasan sin costo adicional — son apenas una docena de pruebas regex que toman microsegundos.
La decisión de diseño clave es usar context.waitUntil() para diferir la llamada de analíticas. El bot recibe su respuesta inmediatamente; el evento se dispara en segundo plano. Los fallos de analíticas nunca bloquean la entrega de la página — un catch vacío asegura que una caída de Umami no rompa el sitio.
Pero no todos los crawlers se anuncian claramente. Una segunda capa captura bots no reconocidos — cualquier cosa con “crawler”, “spider”, “scraper” o “agent” en el User-Agent que no sea un buscador conocido como Googlebot o Bingbot. Estos disparan un evento unknown_bot_visit que incluye el string completo de User-Agent, para que después pueda inspeccionar el dashboard y decidir si alguno merece ser promovido a la lista de conocidos.
Escribí sobre la implementación completa en Rastreando lo Invisible: Cómo Construí Analíticas para Bots de IA. Así se ven los datos de las últimas 24 horas:
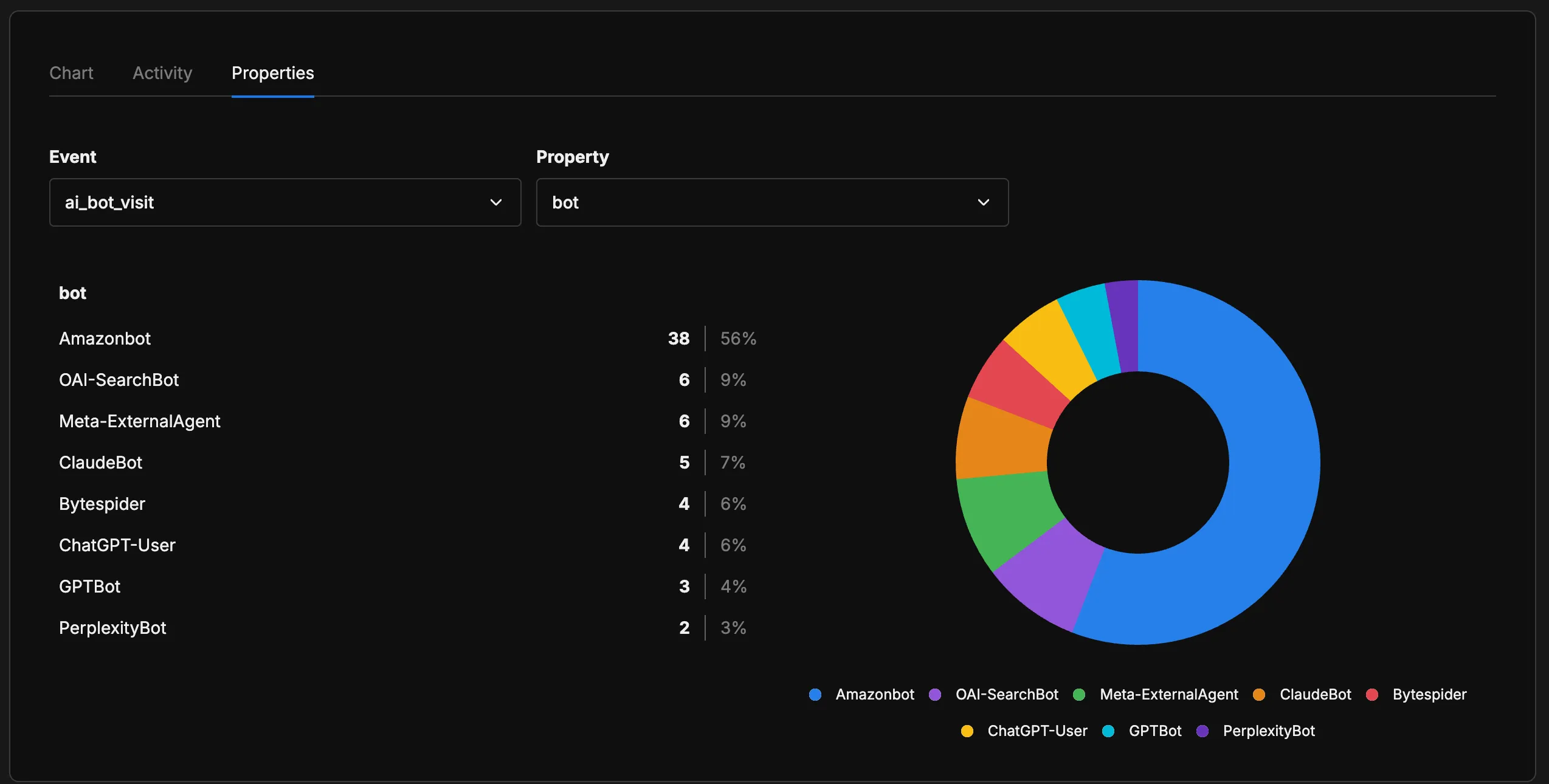
La distribución me sorprendió. Amazonbot domina con el 56% de todas las visitas de bots de IA — no es lo que esperaba cuando configuré esto por primera vez. Los bots de OpenAI (OAI-SearchBot + ChatGPT-User + GPTBot) suman alrededor del 19%, Meta-ExternalAgent se ubica en el 9%, y ClaudeBot en el 7%. PerplexityBot es el más pequeño con el 3%, lo cual es interesante considerando cuánto ha crecido Perplexity como producto.
El dashboard de bots desconocidos cuenta una historia diferente:
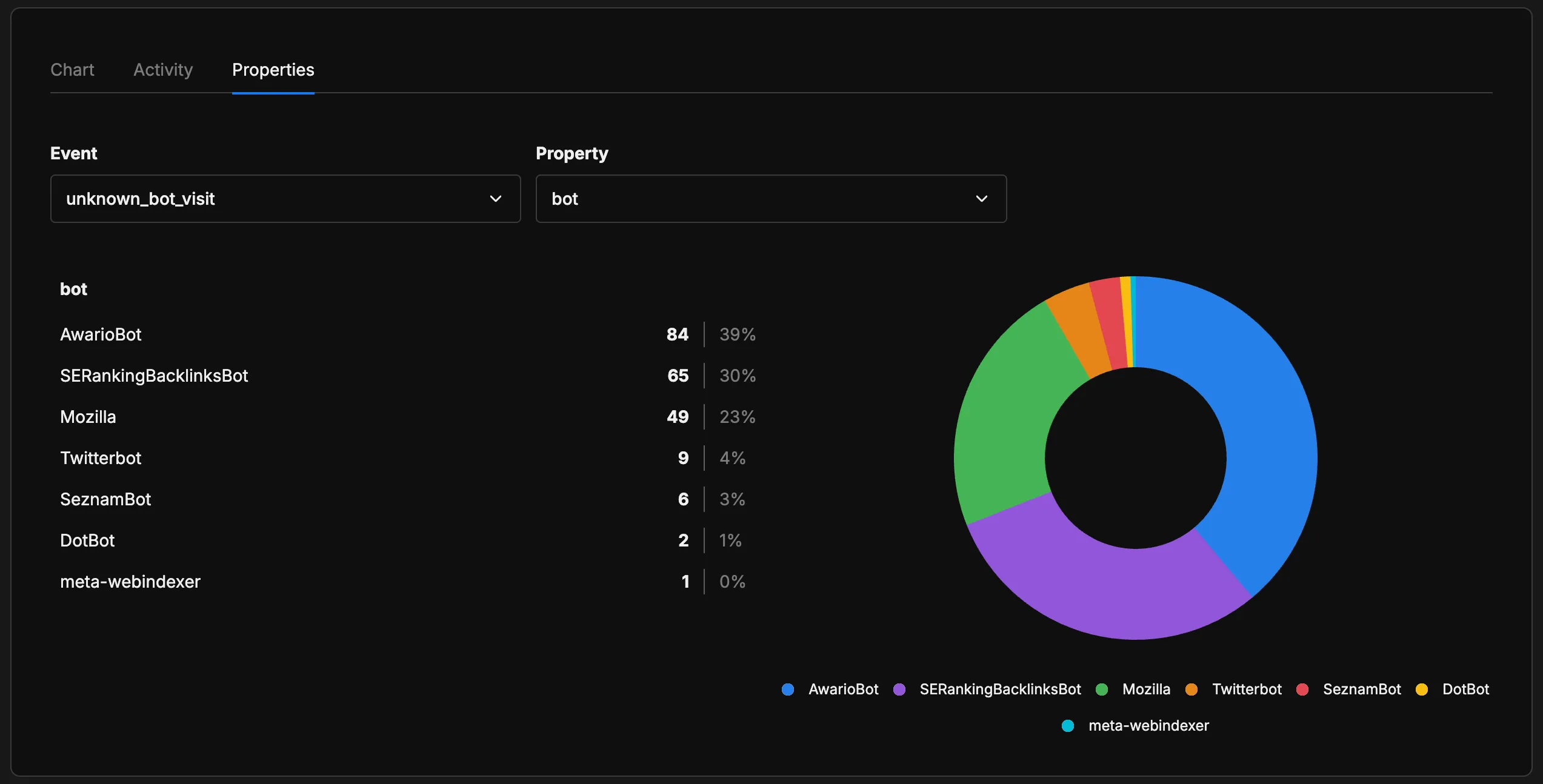
La mayoría de estos son herramientas SEO (AwarioBot, SERankingBacklinksBot) o crawlers de redes sociales (Twitterbot), no sistemas de IA. El 23% etiquetado como “Mozilla” tiene más sentido cuando ves los strings completos de User-Agent:
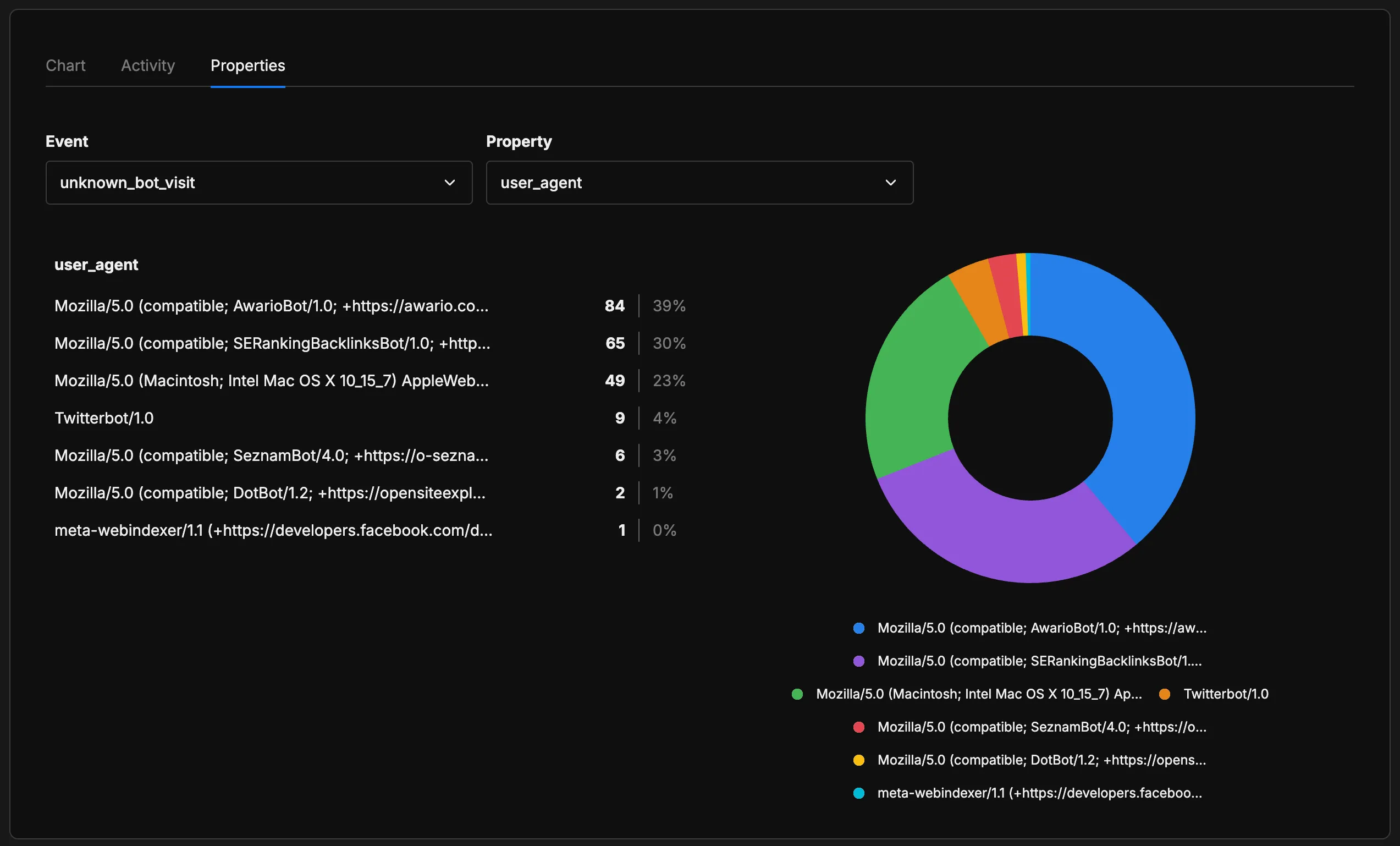
Esas entradas de “Mozilla” están usando Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit... — un string completo de User-Agent de Safari en escritorio. Son scrapers automatizados disfrazándose de navegadores reales. Exactamente el tipo de bot que es imposible de clasificar sin un análisis más profundo. Esta capa es útil como mecanismo de descubrimiento: cuando aparezca un nuevo crawler de IA, lo voy a ver acá primero.
Lo que obtienes de todo esto es imperfecto pero real: qué bots están rastreando, qué páginas visitan, con qué frecuencia. Esa es la base. Todo lo demás en la medición de AEO se construye sobre esta señal — o le falta completamente.
Rastrear Solicitudes de Markdown
El mismo middleware rastrea una segunda señal: cuando los agentes solicitan contenido Markdown — vía headers Accept: text/markdown o URLs .md directas. En mi implementación, cada solicitud de Markdown dispara un evento markdown_request a Umami con:
| Campo | Descripción |
|---|---|
bot | Nombre del bot conocido (GPTBot, ClaudeBot, etc.) o "unknown" |
path | La ruta solicitada |
source | content_negotiation o direct_url |
user_agent | Primeros 200 caracteres del string User-Agent |
El campo source es el más interesante. Si los agentes empiezan a enviar headers Accept: text/markdown — la manera “correcta” de solicitar Markdown for Agents — aparece como content_negotiation. Si simplemente están accediendo a URLs .md que encontraron en algún lugar, aparece como direct_url. La proporción te dice algo sobre cuánto conocen los agentes la convención.
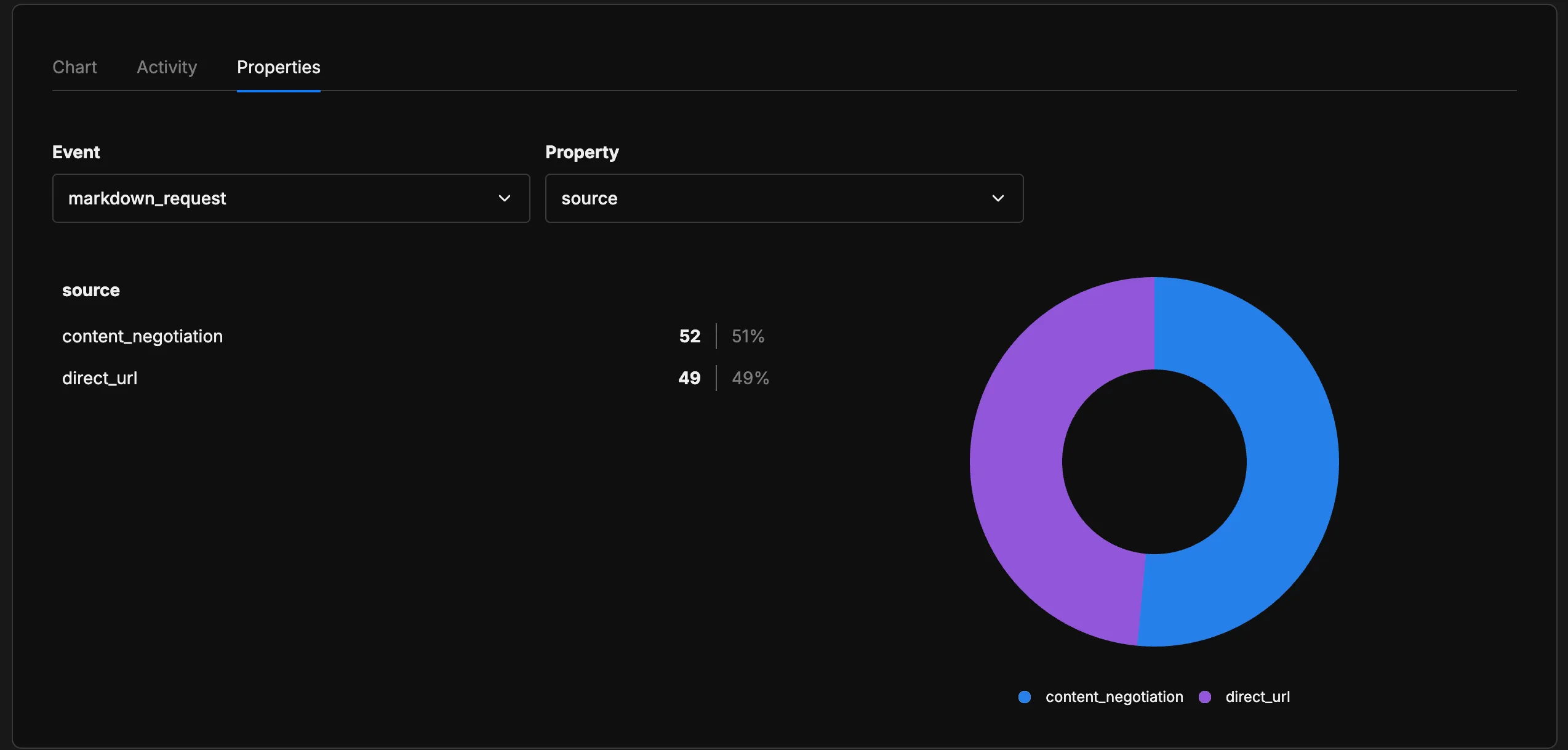
Los datos apenas están empezando a llegar — implementé esto recientemente y todavía es pronto para sacar conclusiones. Pero a futuro, esta señal me va a permitir entender si el estándar realmente se está empezando a adoptar y qué tanto los bots de IA están pidiendo contenido Markdown en mi sitio.
El Panorama de la Medición
Este es el estado de la industria: una herramienta nativa útil, algunas opciones de terceros, y mucho trabajo manual de suposición.
El informe de Rendimiento de IA de Bing es lo más concreto disponible. Obtienes citas totales, qué páginas son referenciadas, y las “consultas de fundamentación” — las frases que usó la IA cuando recuperó tu contenido. Cubre Microsoft Copilot y los resúmenes de Bing AI específicamente. No es un panorama global, pero son datos reales de una plataforma real, lo que lo hace más útil que la mayoría de las alternativas disponibles ahora mismo.
Google no tiene nada comparable para AI Overviews. Google Search Console ya incluye datos de AI Mode, pero todo queda agrupado dentro del tipo de búsqueda “Web” regular — no hay un filtro separado para ver cuánto tráfico viene de superficies generadas por IA versus los resultados orgánicos tradicionales. Si eso es una opacidad intencional o simplemente no está listo, no podría decirlo — pero es una brecha significativa dado que Google genera la mayor cantidad de AI Overviews. La plataforma con mayor presencia te da la menor visibilidad.
Para todo lo demás, investigando encontré un par de opciones que no he probado personalmente pero que se ven prometedoras: Otterly.ai para monitoreo de citas entre plataformas y el AEO Grader gratuito de HubSpot para una auditoría puntuada contra las mejores prácticas de AEO. Más allá de esas, quedan las pruebas manuales — correr tus consultas objetivo en ChatGPT y Perplexity y verificar si apareces.
Las pruebas manuales son más útiles de lo que parecen, pero con una advertencia importante. Según la investigación de AirOps, solo el 30% de las marcas se mantienen visibles de una respuesta de IA a la siguiente, y solo el 20% en cinco ejecuciones consecutivas. Una verificación puntual el martes no significa nada para el jueves.
Esta es la parte más débil del ecosistema AEO ahora mismo. Podemos optimizar contenido. Podemos rastrear crawlers. Pero medir “¿con qué frecuencia me cita la IA?” con alguna confianza estadística sigue siendo básicamente un problema sin resolver. El rastreo de bots del lado del servidor es el mejor proxy disponible — al menos puedes confirmar que los bots están llegando y qué páginas les interesan. Lo que no puedes confirmar es si esas visitas de crawleo se están convirtiendo en citas.
La Auditoría
No hay herramientas de auditoría AEO estandarizadas como SEMrush o Lighthouse para SEO y rendimiento. Tienes que construir el checklist tú mismo, o tomarlo prestado de algún lado. Como no encontré nada que cubriera todo lo que me importaba, armé mi propio framework alrededor de cuatro dimensiones — básicamente las cuatro preguntas que me hacía sobre cada página de este sitio:
| Dimensión | Qué Mide |
|---|---|
| Descubribilidad | ¿Pueden los crawlers de IA encontrar y acceder al contenido? (robots.txt, llms.txt, permisos de rastreo) |
| Extraíbilidad | ¿Pueden los sistemas de IA analizar significado estructurado? (schema markup, HTML semántico, jerarquía de headings) |
| Confianza | ¿Lleva el contenido señales de credibilidad? (atribución de autor, timestamps, fuentes citadas) |
| Citabilidad | ¿Está el contenido estructurado para ser citable? (respuestas claras, lenguaje directo, densidad factual) |
Cada dimensión tiene su propio checklist. El puntaje en sí importa menos que lo que la auditoría revela en el proceso — cada brecha que encontré se convirtió en una tarea, y el trabajo documentado a lo largo de esta serie es el resultado de recorrer ese checklist sistemáticamente.
Dos cosas me sorprendieron cuando revisé esto sistemáticamente.
La actualidad no es solo contenido — son señales. Mencioné en el primer capítulo que los sistemas de IA favorecen el contenido fresco — y los datos lo respaldan: el contenido citado por IA es un 25.7% más reciente que los resultados tradicionales de Google, y en ChatGPT específicamente, el 76.4% de las páginas más citadas se actualizaron en los últimos 30 días. Lo que descubrí trabajando en este sitio es que no basta con actualizar el texto — necesitas pruebas visibles. Agregar timestamps de “última actualización” a cada post, mantener dateModified actualizado en el schema BlogPosting, y asegurarse de que el llms.txt refleje cambios recientes. El contenido puede ser idéntico, pero si las señales de actualidad están desactualizadas, los sistemas de IA lo tratan como desactualizado.
La calidad de la localización importa más que la cobertura. Tener este sitio en dos idiomas ya le da una ventaja de visibilidad — los sistemas de IA tratan cada versión de idioma de forma independiente. Pero las páginas traducidas automáticamente con frases torpes o sin contexto cultural puntúan más bajo en citabilidad. Las páginas que mejor rinden son las que se leen como si hubieran sido escritas nativamente, no traducidas. Esa es exactamente la razón por la que este sitio solo existe en inglés y español — los dos idiomas que realmente hablo y puedo auditar personalmente. Podría escalar a más idiomas con traducción por IA, pero no podría leer cada frase y darle forma hasta que suene bien. Recorro cada frase, reescribo lo que no se siente natural, y construyo la versión final yo mismo. Es un proceso que lleva tiempo, pero si quieres entregar contenido de calidad con una voz de autor real, es importante.
Hacia Dónde Va Esto
Voy a ser honesto: todavía estamos descubriendo esto. Todos. El grupo de trabajo IETF AIPREF está redactando especificaciones sobre cómo los sitios web expresan preferencias sobre el uso de su contenido por IA — entrenamiento, output, búsqueda, cada una como categoría separada. Hasta que eso llegue, dependemos de robots.txt, un archivo que precede a los grandes modelos de lenguaje por quince años. Funciona, pero nunca fue diseñado para esto.
Lo que sí sé es que los números son reales. Un análisis de 13 meses de Search Engine Land (febrero 2026) encontró que el tráfico de búsqueda por IA convierte a un 18% aproximadamente — la fuente de mayor conversión en su dataset. Vercel reportó que las referencias de ChatGPT llegaron al 10% de sus nuevos registros. Tally.so vio a ChatGPT convertirse en su principal fuente de referidos, a secas. Y del otro lado de la ecuación, las principales publicaciones tech están perdiendo hasta el 97% de su tráfico orgánico a medida que los AI Overviews se comen las consultas que antes dominaban.
¿Cuánto del tráfico de este sitio viene de citas de IA? Honestamente no lo sé. Esa es la brecha de medición de la que vengo hablando todo este capítulo. Los bots están visitando — eso lo puedo ver en el dashboard. Qué páginas les interesan — eso también es visible. Si esas visitas se convierten en citas que traen gente hasta acá — sigue siendo una caja negra.
Pero la infraestructura para servirlos bien existe hoy. Y el terreno debajo de la búsqueda se está moviendo, estemos listos o no.
Sigamos construyendo.
Recursos
Herramientas de Medición
- Rendimiento de IA en Bing Webmaster Tools — Seguimiento de citas en Microsoft Copilot y Bing AI
- Otterly.ai — Monitoreo de visibilidad de citas en múltiples plataformas de IA
- AEO Grader de HubSpot — Herramienta gratuita de auditoría y puntaje AEO
Investigación y Datos
- AirOps: Volatilidad de Citas de IA — Solo el 30% de las marcas se mantiene visible entre respuestas consecutivas de IA
- Search Engine Land: 13 Meses de Datos de Tráfico LLM — El tráfico de búsqueda por IA convierte a ~18%, la fuente de mayor conversión
- HubSpot: Tendencias de Adopción de AEO — Estrategia e implementación de AEO
- Caso de Estudio Vercel — ChatGPT crece hasta el 10% de los nuevos registros
Estándares
- Grupo de Trabajo IETF AIPREF — Especificaciones formales de permisos de contenido para IA en desarrollo
- Cloudflare: Markdown for Agents — Content negotiation en el edge

Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.