BSolutions: Administrando Múltiples Motores de Bases de Datos con Django y Docker

La pregunta que da origen a este proyecto es deceptivamente simple: ¿es posible que una sola aplicación hable con diez motores de bases de datos al mismo tiempo?
La respuesta corta es sí. La respuesta interesante es cómo — y por qué querrías hacerlo.
Este es el proyecto final de mi clase de Bases de Datos Avanzadas en la universidad. El enunciado pide demostrar administración multi-base de datos: conectar un sistema central a distintos motores, tanto relacionales como NoSQL, desde un mismo punto de control. El nombre del proyecto es BSolutions. La arquitectura corre sobre Docker. El núcleo es Django. Y los motores de bases de datos son diez.
El reto real
Antes de entrar en los detalles técnicos, vale la pena preguntarse: ¿para qué sirve esto en la vida real?
Hay escenarios concretos donde conectar una aplicación a múltiples motores de bases de datos tiene sentido. El más común es la migración de datos — cuando una empresa decide cambiar de PostgreSQL a MySQL, o de MySQL a MongoDB, necesita un período de transición donde ambos sistemas coexisten y se sincronizan. Una capa central que hable con ambos hace esa migración mucho más controlada.
Otro escenario es la persistencia políglota — la idea de que diferentes tipos de datos se almacenan mejor en diferentes motores. Los datos de sesiones de usuario van bien en Redis. Los grafos de relaciones sociales van mejor en Neo4j. Los documentos semi-estructurados encajan en MongoDB. Los datos transaccionales financieros necesitan la consistencia ACID de PostgreSQL. Una aplicación sofisticada puede aprovechar las fortalezas de cada motor en lugar de usar uno solo para todo.
Y está el escenario académico: aprender cómo se comporta cada motor, cómo difieren sus modelos de datos, cómo Django abstrae (y dónde no abstrae) esas diferencias. Eso es exactamente lo que este proyecto hace posible.
La arquitectura
El corazón del proyecto es un contenedor central corriendo Python con Django, Factory Boy para generación de datos de prueba, y uWSGI como servidor de aplicaciones. Ese contenedor central se conecta, a través de la red interna de Docker, a diez contenedores de bases de datos — cinco SQL y cinco NoSQL.
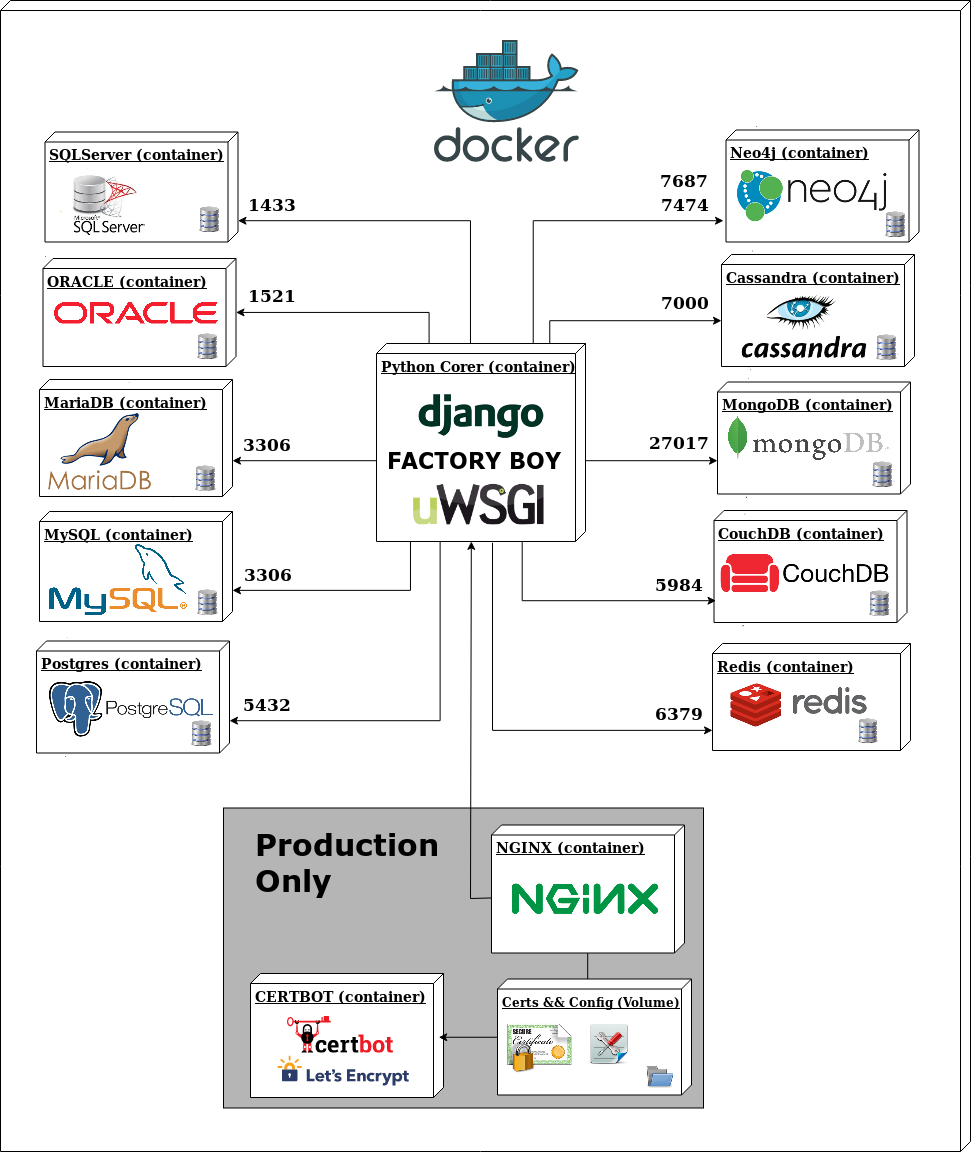
Lo que el diagrama muestra es una topología estrella: un core central y diez spokes que son las bases de datos. Cada base de datos vive en su propio contenedor aislado, expone su puerto nativo, y la aplicación Django sabe cómo hablar con cada una de ellas.
Encima de eso hay una capa de infraestructura de producción: Nginx como reverse proxy, Certbot para SSL con Let’s Encrypt, y un volumen compartido para certificados y configuraciones. Y una capa de tareas asíncronas: Celery Worker para procesar jobs en background, Celery Beat para tareas programadas, y Flower para monitorear el estado de Celery en tiempo real. PgAdmin completa el stack como herramienta de administración visual para PostgreSQL.
Las bases de datos SQL
Los cinco motores relacionales que el proyecto integra cubren el espectro de lo que se usa en la industria hoy:
PostgreSQL (puerto 5432) es el motor SQL más avanzado del ecosistema open source. Soporte nativo para JSON, arrays, tipos personalizados, transacciones ACID completas, y una comunidad enorme. Es el punto de referencia contra el que se comparan los demás.
MySQL (puerto 3306) sigue siendo el motor relacional más usado en el mundo por puro volumen histórico. Millones de aplicaciones web corren sobre MySQL — es el motor detrás de WordPress, Drupal, y una cantidad incontable de stacks LAMP. Incluirlo es casi obligatorio en cualquier proyecto que quiera ser representativo.
MariaDB (puerto 3306) nació como un fork de MySQL cuando Oracle compró Sun Microsystems y con ello MySQL. La comunidad detrás de MySQL creó MariaDB para mantener una alternativa completamente open source. Es compatible en protocolo con MySQL — comparte el mismo puerto, el mismo cliente, muchas de las mismas APIs — pero tiene un motor de almacenamiento distinto y algunas características que MySQL no tiene. Tener ambos en el mismo stack es una oportunidad interesante para ver qué los diferencia en la práctica.
Oracle Database (puerto 1521) es el motor empresarial por excelencia. Dominante en finanzas, gobierno, y corporaciones grandes. Costoso, pesado, y con una curva de aprendizaje considerable, pero con características de confiabilidad y escalabilidad que pocos motores igualan. Conectarlo desde Django requiere el cliente cx_Oracle y los drivers nativos de Oracle — nada trivial de configurar, especialmente dentro de un contenedor.
SQL Server (puerto 1433) es el motor relacional de Microsoft. Profundamente integrado con el ecosistema .NET y Azure, pero perfectamente usable desde Python con el driver pyodbc. Incluirlo en el stack representa la perspectiva de Microsoft en el mundo de las bases de datos relacionales.
Las bases de datos NoSQL
Los cinco motores no relacionales cubren paradigmas fundamentalmente distintos — no son intercambiables entre sí, y esa es exactamente la lección:
MongoDB (puerto 27017) es la base de datos de documentos más conocida. Los datos viven como documentos BSON — esencialmente JSON con tipos adicionales. No hay schema fijo: dos documentos en la misma colección pueden tener campos completamente distintos. Ideal para datos cuya estructura evoluciona, para prototipos rápidos, y para aplicaciones donde la flexibilidad importa más que la consistencia estricta.
Redis (puerto 6379) es fundamentalmente diferente a cualquier otro motor del stack. Es una base de datos en memoria, lo que la hace extremadamente rápida — submilisegundo para la mayoría de operaciones. Sus estructuras de datos nativas (strings, listas, sets, sorted sets, hashes) la hacen perfecta para caché, sesiones de usuario, colas de mensajes, rankings en tiempo real, y rate limiting. Redis no reemplaza una base de datos tradicional — la complementa.
CouchDB (puerto 5984) también es una base de datos de documentos, pero con una filosofía distinta a MongoDB. Su característica más interesante es la replicación multi-master: puedes tener múltiples instancias de CouchDB que se sincronizan entre sí, incluso con conflictos. Diseñada para escenarios offline-first donde los datos cambian en múltiples nodos desconectados y luego necesitan reconciliarse. También expone su API completamente a través de HTTP/JSON, lo que la hace accesible desde cualquier lenguaje sin un driver especializado.
Cassandra (puerto 7000) está diseñada para escala masiva y alta disponibilidad. Es una base de datos wide-column — los datos se organizan en filas con columnas, pero a diferencia de SQL, diferentes filas pueden tener diferentes columnas, y el esquema está optimizado para patrones de lectura específicos, no para relaciones generales. Cassandra brilla cuando necesitas escribir millones de eventos por segundo (logs, métricas, datos de IoT) con tolerancia a fallos de nodos individuales. Facebook, Netflix, y Apple la usan a escala.
Neo4j (puertos 7687 y 7474) es una base de datos de grafos. Los datos son nodos y relaciones — no tablas, no documentos, no columnas. Las relaciones son ciudadanos de primera clase, almacenadas explícitamente, no inferidas a través de JOINs. Esto la hace radicalmente más eficiente que SQL para preguntas del tipo “encuentra todos los amigos de amigos de esta persona” o “¿qué camino conecta estos dos nodos?”. Los grafos de conocimiento, las redes sociales, y los sistemas de recomendación son casos de uso naturales.
El setup con Docker
La razón por la que este proyecto es posible sin volverte loco es Docker.
Sin contenedores, correr diez motores de bases de datos en la misma máquina sería una pesadilla de configuración. PostgreSQL necesita sus librerías. Oracle necesita sus drivers nativos y tiene un proceso de instalación brutalmente complejo. Redis requiere su propia versión de glibc. Cassandra quiere una JVM específica. Cada motor tiene sus dependencias, sus archivos de configuración, sus puertos, y sus procesos de inicialización — y todos compiten por los mismos recursos del sistema.
Con Docker, cada motor corre en su propio contenedor aislado. PostgreSQL no sabe que Redis existe. Oracle no interfiere con MySQL. El contenedor de Django no tiene que lidiar con ninguna de esas dependencias directamente — solo necesita los drivers de cliente Python para conectarse a cada motor a través de la red interna de Docker.
El archivo docker-compose.yml define el stack completo: todos los contenedores, sus imágenes base, las variables de entorno para credenciales, los puertos que exponen, y los volúmenes para persistencia. Levantar todo el sistema desde cero es un solo comando.
Para hacer el flujo de trabajo aún más fluido, el proyecto incluye un script docker.sh que automatiza las operaciones más comunes: levantar el stack, detenerlo, limpiar volúmenes, ejecutar comandos dentro de contenedores específicos, correr las migraciones de Django, y acceder a shells interactivos de cada base de datos. No hay que recordar los comandos exactos de Docker — el script los encapsula en nombres semánticos.
Routing multi-base de datos en Django
La magia que conecta Django con diez bases de datos simultáneamente vive en dos lugares: settings.py y los database routers.
En settings.py, la variable DATABASES en un proyecto Django normalmente define una sola base de datos. Aquí define diez:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'bsolutions',
'USER': 'postgres',
'PASSWORD': os.environ.get('POSTGRES_PASSWORD'),
'HOST': 'postgres',
'PORT': '5432',
},
'mysql': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'bsolutions',
'USER': 'root',
'PASSWORD': os.environ.get('MYSQL_PASSWORD'),
'HOST': 'mysql',
'PORT': '3306',
},
'mongodb': {
'ENGINE': 'djongo',
'NAME': 'bsolutions',
'HOST': 'mongodb',
'PORT': 27017,
},
# ... y así sucesivamente para los 10 motores
}Cada clave en DATABASES es un alias que el proyecto usa para referirse a esa conexión. El hostname coincide con el nombre del servicio en docker-compose.yml — Docker resuelve esos nombres a las IPs internas de los contenedores automáticamente.
Los database routers son el mecanismo que le dice al ORM de Django qué base de datos usar para cada modelo o query. Sin un router, Django usa siempre 'default'. Con un router personalizado, puedes definir reglas: “este modelo siempre va a MongoDB”, “este otro siempre va a Redis”, “estas operaciones de lectura van a la réplica”.
class MultiDatabaseRouter:
def db_for_read(self, model, **hints):
if model._meta.app_label == 'mongodb_app':
return 'mongodb'
if model._meta.app_label == 'redis_app':
return 'redis'
return 'default'
def db_for_write(self, model, **hints):
return self.db_for_read(model)
def allow_migrate(self, db, app_label, model_name=None, **hints):
# Solo migrar modelos relacionales en sus respectivos motores
return TruePara los motores SQL, el ORM de Django funciona con sus abstracciones estándar — Model, QuerySet, migrations. Para los motores NoSQL, la historia es más compleja: Redis tiene su propio cliente Python (redis-py) con una API completamente diferente a la del ORM, y MongoDB se puede integrar a través de djongo o directamente con pymongo. Parte del valor del proyecto es precisamente tocar esos límites — ver dónde la abstracción de Django se sostiene y dónde hay que bajar al nivel del driver.
Factory Boy entra aquí como herramienta de generación de datos. En lugar de insertar datos de prueba manualmente en diez bases de datos, Factory Boy define factories que generan objetos con datos realistas (nombres, correos, fechas, números) y los persisten en el motor correspondiente. Es la misma idea que los fixtures de Django, pero más flexible y más expresiva.
Infraestructura de soporte
El stack tiene dos capas adicionales más allá del core de Django y las diez bases de datos.
Nginx actúa como reverse proxy frente a uWSGI. Recibe las peticiones HTTP del exterior, las enruta al servidor Django, y devuelve las respuestas. También sirve archivos estáticos directamente, sin pasar por Django — una optimización importante en producción. Certbot automatiza la obtención y renovación de certificados SSL de Let’s Encrypt, y un volumen compartido guarda esos certificados y las configuraciones de Nginx.
Celery maneja las tareas asíncronas. Celery Worker procesa los jobs que la aplicación encola — cosas que no deben bloquear el request/response cycle de HTTP, como enviar emails, procesar archivos grandes, o hacer operaciones pesadas en las bases de datos. Celery Beat es el scheduler — define tareas que se ejecutan en intervalos regulares, como limpieza de datos o sincronización entre bases de datos. Flower es el tablero de monitoreo de Celery: muestra en tiempo real qué workers están corriendo, qué tareas están en cola, cuáles fallaron, cuánto tardaron.
PgAdmin completa el stack como interfaz visual para PostgreSQL. En lugar de conectarse por línea de comandos para inspeccionar tablas, ejecutar queries, o ver el estado de la base de datos, PgAdmin provee un cliente web completo. Útil durante el desarrollo para verificar que las migraciones de Django se están aplicando correctamente y que los datos se están insertando donde deben.
Lo que este proyecto enseña
Hay algo que se vuelve obvio al construir esto: los motores de bases de datos no son intercambiables, y eso es precisamente el punto.
PostgreSQL y MySQL hacen esencialmente lo mismo — datos relacionales, transacciones, SQL estándar — pero difieren en detalles que importan en producción: tipos de datos soportados, comportamiento de las transacciones, capacidades de full-text search, rendimiento en cargas específicas. MariaDB y MySQL comparten el mismo protocolo pero tienen diferencias internas que se notan en casos de uso avanzados.
Los motores NoSQL son aún más distintos entre sí. Redis y MongoDB comparten la etiqueta “NoSQL” pero tienen modelos de datos completamente diferentes, casos de uso distintos, y garantías de consistencia que no se comparan directamente. Cassandra y Neo4j viven en planetas diferentes. La etiqueta NoSQL es más una negación — “no es SQL relacional” — que una descripción positiva de lo que son.
Forzarse a conectar los diez desde un mismo punto de control hace que esas diferencias sean concretas. No es teoría de libros de texto. Es el momento en que intentas escribir en Redis con el ORM de Django y el framework simplemente no puede ayudarte, y tienes que bajar a redis-py y pensar en términos de claves y valores. O cuando configuras Neo4j y te das cuenta de que el modelo de datos no tiene nada que ver con tablas — son nodos y aristas, y pensar en términos de SQL para consultarlos es el enfoque equivocado.
El proyecto tiene 238 commits. Eso refleja la realidad de un setup de esta complejidad: no todo funciona a la primera, los drivers tienen sus peculiaridades, las versiones de imágenes Docker importan, y hay mucho debugging involucrado. Pero ese proceso es parte del aprendizaje.
Recursos
- BSolutions — Código fuente en GitHub
- Documentación oficial de Django — Multiple Databases
- Docker Compose Documentation
- Factory Boy — generación de datos de prueba en Python
- Flower — monitoreo de Celery
A seguir construyendo.