POO en Acción: Construyendo un Solucionador de Sudoku y una Agenda de Contactos con Java Swing

Hay un momento en que programar deja de ser “cosas que funcionan” y se convierte en “sistemas que tienen sentido”. Para mí, ese momento llegó en Programación Orientada a Objetos — no cuando aprendí qué es una clase, ni qué hace la herencia, sino cuando descubrí que existen soluciones con nombre para problemas comunes. Que alguien, décadas atrás, se sentó a identificar patrones recurrentes en cómo se construía el buen software, les puso nombre, y los dejó escritos.
Ese fue el cambio. No “así funciona Java”. Más bien: “estos son los planos que usan los ingenieros para resolver problemas difíciles, y vamos a construir algo real con ellos.”
Cuando tomé este curso, ya no era nuevo en la programación. Había pasado un semestre mirando paréntesis en DrScheme, otro semestre peleando con punteros en C. Sabía cómo hacer que las cosas funcionaran. Pero la POO era diferente — se trataba de arquitectura. De pensar en patrones antes de escribir una sola línea de código.
El curso que me enseñó a pensar en patrones
El curso de Programación Orientada a Objetos en la universidad no era solo sobre clases y herencia. Eso era el vocabulario. El tema real eran los patrones de diseño — el patrón Observer, MVC, Factory, Singleton. La idea de que cuando te encontrabas con un tipo particular de problema, probablemente ya existía un enfoque bien documentado y probado para resolverlo. Solo tenías que reconocer el problema.
El profesor fue claro sobre lo que esperaba de nosotros: no programas que funcionaran, sino programas que estuvieran bien diseñados. Programas donde pudieras mirar la estructura y entender de inmediato el razonamiento detrás de cada separación de responsabilidades. Programas donde cambiar una parte no rompiera todo lo demás.
Dos proyectos de este curso se destacan por encima de todo. Son los que sigo recordando cuando pienso en dónde la arquitectura de software realmente me hizo clic.
El proyecto del Sudoku
El plato fuerte. El profesor nos dio el enunciado: construir un solucionador de Sudoku con interfaz gráfica. Los requisitos sonaban engañosamente simples — hasta que leías la letra pequeña.
Requisitos: arquitectura MVC. Patrón Observer para la propagación de restricciones. Algoritmo de backtracking para resolver. Java Swing para la UI.
Esto no era “construye un juego de Sudoku”. Era “construye un juego de Sudoku de la manera correcta, usando patrones que acabas de aprender, en un lenguaje con el que todavía te estás familiarizando, con una UI que se vea bien de verdad.”
El primer día, abrí un proyecto Java nuevo y me quedé mirando el archivo en blanco por unos buenos veinte minutos. La tentación de simplemente empezar a escribir — un arreglo del tablero, unos ciclos, pegar una cuadrícula en la pantalla — era real. Pero sabía que ese enfoque se iba a derrumbar en el momento en que intentara integrar el patrón Observer después. Así que me obligué a diseñar primero.
Diseñando la arquitectura MVC
La primera decisión fue dónde iba a vivir cada cosa. MVC — Model, View, Controller — significa que la capa de datos y la capa de presentación están completamente separadas. El Model no tiene idea de cómo se van a mostrar los datos. El View no tiene idea de cómo funcionan los datos internamente. Se comunican a través de interfaces definidas.
Para el solucionador de Sudoku, la separación quedó así:
SudokuSrc/
Model.java # Tablero de Sudoku, celdas, lógica del solver
Watch.java # GUI con Java Swing + manejo de eventos
board.txt # Archivo de puzzle estándar
board_Escargot.txtModel.java — tenía todo lo relacionado con el puzzle de Sudoku en sí. Una matriz 9x9 de objetos Cell. Cada Cell tenía un conjunto de valores candidatos (los enteros del 1 al 9 que la celda todavía podía contener legalmente). El Model manejaba la propagación de restricciones, el solving, la clonación de estados del tablero, la carga de puzzles desde archivos. Cero código de UI. Cero imports de Swing. El Model podía correr de manera headless y no sabía ni le importaba si existía alguna interfaz.
Watch.java — tenía el JFrame de Java Swing, la cuadrícula de JPanels, todos los event listeners, los botones, el renderizado de colores. Sabía todo sobre cómo se veía el puzzle, pero delegaba toda la lógica al Model.
Esa separación suena obvia cuando la escribes. En la práctica, cuando eres estudiante y solo quieres que algo funcione, requiere disciplina real. Cada vez que empezaba a escribir algo en Watch.java y pensaba “esto necesita verificar si la celda está resuelta”, tenía que parar, poner esa lógica en Model.java, y exponerla a través de un método. El límite es fácil de difuminar. Mantenerlo limpio es una decisión que tomas continuamente.
El patrón Observer — la parte que realmente me impresionó
Aquí es donde el diseño se volvió elegante.
Cada Cell en el Model extendía Observable e implementaba Observer. Cuando el tablero se inicializaba, cada celda se registraba como observadora de todas las demás celdas en su misma fila, la misma columna, y el mismo cuadrante 3x3. El 99% de los solucionadores de Sudoku funcionan por fuerza bruta — prueba un número, verifica si es válido, continúa. Este enfoque era diferente.
Cuando una celda se resolvía — cuando su valor quedaba definitivamente establecido — notificaba a todos sus observadores:
// Cell extends Observable implements Observer, Iterable<Integer>
public void setValue(int value) {
candidates.clear();
candidates.add(value);
setChanged();
notifyObservers(value); // Tell all related cells
}
// When a related cell is notified, remove that value from candidates
public void update(Observable o, Object arg) {
int value = (Integer) arg;
candidates.remove(value);
if (candidates.size() == 1) {
// Only one candidate left — auto-solve! (cascade)
setValue(candidates.get(0));
}
}Mira ese método update. Cuando una celda se entera de que una de sus celdas relacionadas fue resuelta, elimina ese valor de sus propios candidatos. Si al eliminar ese valor queda solo un candidato, se auto-resuelve — lo que dispara su propio setChanged() y notifyObservers(), que se propaga a sus celdas relacionadas, que pueden reducir sus candidatos, que pueden disparar más auto-resoluciones.
Las fichas caen solas. Establece una celda, y la propagación de restricciones se expande por todo el tablero sin ningún código explícito del solver que la dirija. Simplemente ocurre, a través del sistema de eventos.
Este fue el momento en que los patrones de diseño dejaron de ser teoría de libro de texto para mí. El patrón Observer no era solo “suscribirse a eventos”. Estaba habilitando toda una clase de computación — propagación de restricciones — a través de una estructura que era intuitiva, autocontenida, y no requería que el tablero orquestara nada. Las celdas se manejaban solas.
El algoritmo de backtracking
La propagación basada en Observer maneja completamente los puzzles de Sudoku fáciles. Para puzzles de dificultad media y alta, llegas a puntos donde cada celda sin resolver todavía tiene múltiples candidatos, y ninguna propagación puede romper el empate. Ahí es donde entra el backtracking.
public boolean backtracking() {
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
if (!board[i][j].isSolved()) {
for (int candidate : board[i][j]) {
Model copy = board.clone();
copy.setValue(i, j, candidate);
if (copy.backtracking()) {
// Solution found — copy result back
this.cloneFrom(copy);
return true;
}
}
return false; // Dead end — backtrack
}
}
}
return true; // All cells solved
}La clave aquí es que antes de probar cada candidato, el estado del tablero se clona. Si ese candidato lleva a un callejón sin salida, el clon se descarta y el estado original queda intacto. Este es el patrón Clone embebido dentro del backtracking — manejo limpio del estado que hace que la recursión sea predecible.
Y lo más importante: el backtracking no arranca desde cero. Para cuando necesita entrar en acción, la propagación con Observer ya hizo el trabajo fácil — todas las celdas que podían deducirse lógicamente a partir de restricciones ya están resueltas. El backtracking solo tiene que navegar las decisiones genuinamente ambiguas, que son muchas menos de lo que serían con un enfoque de fuerza bruta puro. Los dos mecanismos se complementan a la perfección.
La interfaz en Java Swing
La capa visual se construyó alrededor de una cuadrícula 9x9 de objetos JPanel, cada uno de 60x60 píxeles. La interfaz tenía algunas características que la hacían sentir como una aplicación real, no como una tarea universitaria:
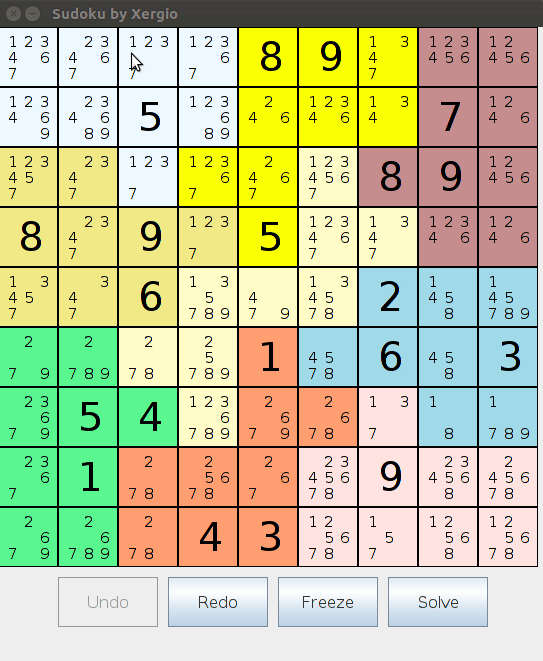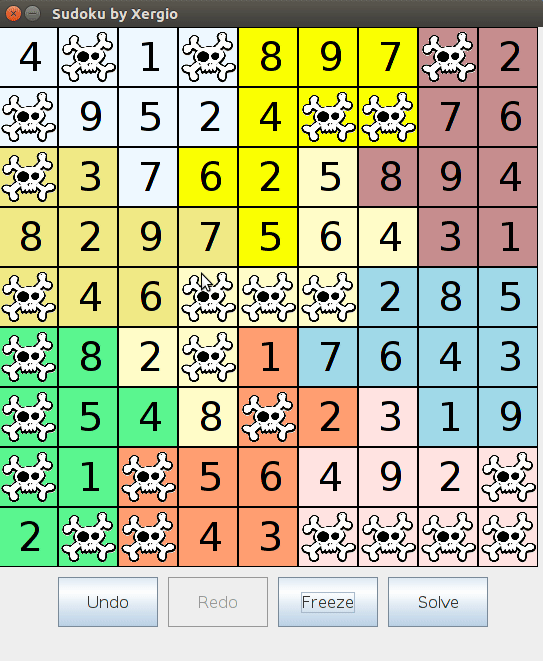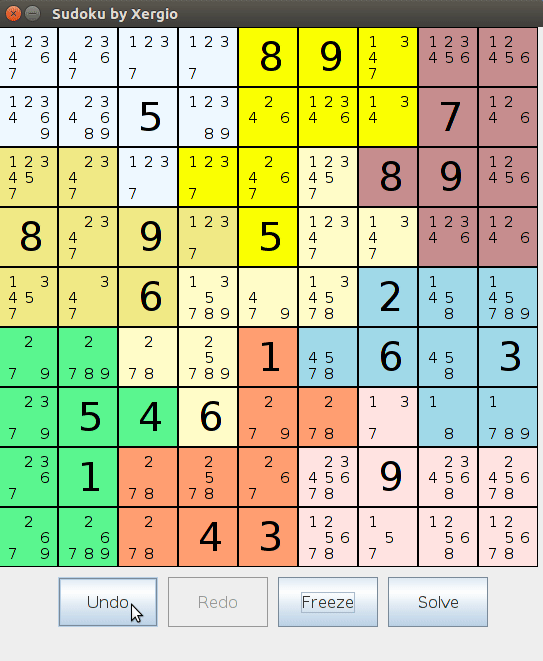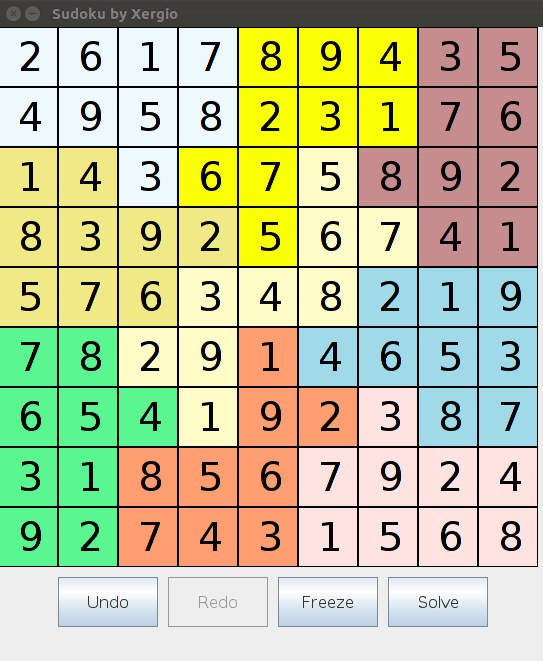
Regiones con código de colores. Los nueve cuadrantes 3x3 se renderizaban cada uno en un color distinto, haciendo que las regiones estructurales del tablero fueran inmediatamente legibles de un vistazo. Nunca tenías que trazar mentalmente los límites del cuadrante — simplemente estaban ahí.
Visualización de candidatos. Cada celda sin resolver mostraba una mini-cuadrícula 3x3 con sus candidatos restantes. En lugar de un espacio en blanco donde tenías que recordar qué todavía era posible, el tablero te mostraba exactamente qué valores seguían en juego para cada celda. Hacer clic en cualquier candidato de la mini-cuadrícula establecía esa celda en ese valor.
Deshacer/Rehacer. Dos objetos Stack<Model> rastreaban el historial completo del tablero. Cada movimiento clonaba el estado actual sobre la pila de deshacer antes de confirmar. Deshacer sacaba de la pila de deshacer y empujaba a la pila de rehacer. Historial de múltiples pasos, en ambas direcciones. Era sencillo de implementar dado que el Model ya era clonable — una buena recompensa por la disciplina arquitectónica.
Estado de error. Si el tablero llegaba a una configuración irresoluble — una celda sin candidatos restantes — aparecía un ícono de calavera. (calavera.gif. Sí, en serio. Estaba muy orgulloso de ese detalle.)
Botón de resolver. Ejecuta el algoritmo completo de backtracking sobre el estado actual del tablero y rellena la solución. Ver cómo funcionaba con un puzzle difícil era genuinamente satisfactorio.
Cargando puzzles desde archivos
Los tableros se guardaban en archivos de texto con un formato ingenioso de dos partes. Las primeras nueve líneas describían el diseño de regiones — a qué cuadrante 3x3 pertenecía cada celda, codificado como una cuadrícula de caracteres. Las líneas restantes daban los valores de pista iniciales como pares posición-valor.
Esto significaba que podías codificar cualquier tablero de Sudoku válido en un archivo de texto simple, y la aplicación podía cargarlo en tiempo de ejecución. El repositorio incluía varios tableros: puzzles estándar para principiantes e intermedios, y el famoso Escargot — uno de los puzzles de Sudoku más difíciles jamás publicados, diseñado en 2006 con solo 22 pistas iniciales específicamente para derrotar algoritmos simples.
El Escargot era la prueba. La propagación sola no puede resolverlo — ni de cerca. El backtracking tiene que profundizar mucho. Ver al solver trabajar a través de él e imprimir la solución era el tipo de recompensa que hace que dos semanas de implementación valgan la pena.
El proyecto complementario: una agenda de contactos
El solucionador de Sudoku fue el proyecto del que estaba más orgulloso del curso de POO. Pero no fue el único.
A principios del semestre, antes del proyecto del Sudoku, construimos una aplicación de escritorio para gestión de contactos. Más simple, pero un ejercicio limpio en los fundamentos: encapsulamiento, separación de responsabilidades, programación orientada a eventos, y persistencia en archivos.
La arquitectura era sencilla y deliberadamente limpia:
Persona.java — el modelo de datos del contacto. Nombre, número de teléfono, dirección de correo electrónico. Con validación por regex integrada en los setters: los nombres debían comenzar con mayúscula, los números de teléfono debían ser numéricos, los correos debían coincidir con un formato válido. Validación a nivel del modelo, no dispersa por toda la UI.
Agenda.java — el gestor de contactos. Una LinkedList de objetos Persona. Operaciones CRUD: agregar, eliminar, actualizar, buscar por nombre o teléfono. Verificación de duplicados antes de insertar. Toda la lógica de negocio en un solo lugar, completamente separada de la presentación.
Validator.java — utilidades centralizadas de regex. Una clase separada solo para validación, porque esos patrones se reutilizarían y tenerlos junto al modelo mezclaría responsabilidades.
Watch.java — la interfaz en Java Swing, construida con el diseñador de formularios de NetBeans. Campos de entrada para cada atributo del contacto, un JTable para mostrar la lista de contactos, diálogos de confirmación antes de operaciones destructivas, tooltips de ayuda en línea en los campos del formulario. Event listeners conectados a los métodos de la Agenda.
Persistencia en archivos mediante contactos.txt. Los contactos se serializaban como líneas delimitadas por espacios al guardar, y se parseaban de vuelta con BufferedReader y StringTokenizer al inicio. No es lo más glamoroso, pero funcionaba, y los contactos sobrevivían al cerrar y reabrir la aplicación — lo que, para un estudiante de segundo año, se sentía como magia de persistencia real.
La agenda no tenía el patrón Observer ni backtracking ni ninguna de las cosas ingeniosas que hacían interesante al solucionador de Sudoku. Lo que tenía era claridad. Cada clase tenía un solo trabajo. El modelo de datos no sabía que existía la pantalla. La UI no implementaba ninguna lógica. La validación estaba centralizada. Era la aplicación directa de los principios que el curso enseñaba — y construirla primero hizo que la arquitectura del Sudoku se sintiera como una escalada natural, no como un salto.
Lo que realmente aprendí
Esta es la versión honesta: pude haber escrito un solucionador de Sudoku sin el patrón Observer. Habría sido un gran ciclo anidado, un arreglo de enteros, y mucha lógica hardcodeada. Probablemente habría funcionado. Definitivamente habría sido más rápido de escribir.
Pero habría sido un desastre. Cambiar cualquier cosa sobre la lógica de restricciones habría requerido tocar todo. Agregar una función — digamos, resaltar celdas afectadas por un movimiento — habría significado inyectar código de presentación dentro de la lógica del solver. La separación MVC se habría derrumbado. Todo se habría convertido en uno de esos programas que te da miedo tocar porque no sabes qué va a romperse.
Los patrones no eran un overhead. Eran lo que hacía que el software fuera manejable. El mismo Model que ejecuta el algoritmo de backtracking podría extraerse y usarse en un backend web, o conectarse a un framework de UI diferente, o probarse de manera aislada sin nunca levantar una ventana de Swing. Eso no es un accidente — es el resultado directo de la decisión arquitectónica de mantener el Model ajeno al View.
El patrón Observer tampoco era solo un casillero de tarea. Genuinamente resolvió un problema que de otra manera habría resuelto mal. La propagación de restricciones implementada como un ciclo explícito en el solver habría sido torpe y acoplada. Implementada a través de eventos, era elegante y automática — las celdas imponían restricciones entre sí, y el solver solo tenía que lidiar con el estado que quedaba.
Estos patrones siguieron apareciendo después de la universidad. Cada framework web con el que he trabajado desde entonces usa alguna forma de MVC. Cada sistema reactivo — ya sea la reactividad de Vue, el estado de React, o los stores de Svelte — es una variante de la idea del Observer. La sintaxis específica cambia. El patrón subyacente no. Aprenderlo a través de un solucionador de Sudoku en Java Swing resultó ser una de las cosas más útiles que hice en esos años.
Mirando hacia atrás
Estamos en 2018 y todavía pienso en esos dos proyectos cuando estoy diseñando algo nuevo y buscando un patrón. No porque Java Swing sea relevante — no lo es, para nada de lo que estoy construyendo ahora — sino porque los problemas que esos patrones resolvieron son universales. Gestión de estado. Propagación de eventos. Separación de responsabilidades. Aparecen en todo sistema no trivial.
Si Programación 1 con Scheme me enseñó a pensar recursivamente, y Programación 2 con C me enseñó qué estaba haciendo realmente la máquina, entonces POO me enseñó a pensar arquitectónicamente. A preguntarme, antes de escribir cualquier código: ¿cuáles son las piezas, qué sabe cada pieza sobre sí misma, y cómo se hablan entre ellas?
Empezar con patrones de diseño se sentía académico en su momento — mucho UML y vocabulario antes de cualquier código real. Pero los proyectos lo hicieron concreto. El solucionador de Sudoku no solo demostró el patrón Observer; me mostró por qué el patrón Observer existe — qué problema fue inventado para resolver, y cuánto más limpio es el resultado cuando lo usas versus cuando no.
Si tienes curiosidad sobre dónde comenzó este recorrido universitario — con un tipo muy diferente de desafío — te invito a leer sobre mi primer curso de programación con DrRacket, donde los paréntesis y la recursión me enseñaron a pensar sobre la computación desde cero.
A seguir construyendo.