
La parte más importante de un agente de IA no es el modelo. Sé cómo suena — llevamos dos años midiendo el progreso por el lanzamiento de turno — pero los equipos que más lejos han llevado los agentes están llegando a la misma conclusión desde lados distintos: lo que separa un agente confiable de uno decepcionante casi nunca es la inteligencia que tiene adentro. Es el sistema que tiene alrededor.
Ese sistema ya tiene nombre: harness engineering (la ingeniería del arnés que envuelve al agente). Si el prompt engineering fue la habilidad de la era de los chatbots, esta es la de la era de los agentes: ya no se trata de pedirle mejor las cosas al modelo, sino de construir el entorno que revisa lo que hace, atrapa lo que rompe y convierte cada error en un arreglo permanente.
Agent = Model + Harness
La forma más limpia que he visto de plantearlo viene de Vivek Trivedy — product lead de LangChain, la empresa detrás de uno de los frameworks más usados para construir aplicaciones y agentes con LLMs — en un texto llamado The Anatomy of an Agent Harness: “Agent = Model + Harness” (Agente = Modelo + Harness). El modelo es la inteligencia. El harness es todo lo demás — y “todo lo demás” hace más trabajo del que suena. Su definición vale la pena citarla exacta: “A harness is every piece of code, configuration, and execution logic that isn’t the model itself” (“un harness es cada pieza de código, configuración y lógica de ejecución que no es el modelo en sí”).
El system prompt (las instrucciones base del agente). Las herramientas que el agente puede llamar. Las skills que puede leer. La orquestación que decide cuándo lanzar un subagente o pasar el control. Los hooks que corren un linter antes de aceptar un cambio. Todo eso es harness. El modelo está en medio de todo eso como un motor está dentro de un carro — esencial, y también no es la parte que te mantiene en la vía.

Lo que hace que el encuadre aterrice no es el diagrama, es la evidencia. LangChain reportó que “improved our coding agent Top 30 to Top 5 on Terminal Bench 2.0 by only changing the harness” (“subimos nuestro agente de código del Top 30 al Top 5 en Terminal Bench 2.0 cambiando solo el harness”). El mismo modelo. No hicieron fine-tuning de nada, no esperaron un lanzamiento más inteligente. Reconstruyeron el andamiaje alrededor de un modelo fijo y saltaron veinticinco puestos en un benchmark. Si pasaste los últimos dos años asumiendo que el progreso llega con el próximo modelo, ese resultado reacomoda algo.
Y lo reacomoda en una dirección contraintuitiva: en un agente de producción, el modelo resulta ser la parte más pequeña. La mayor parte de lo que determina si el agente es útil vive por fuera de él.
“Cambiar el harness” suena vago hasta que enumeras lo que de verdad está sobre la mesa. Puedes reescribir el system prompt para que el agente razone en otro orden. Puedes darle un conjunto de herramientas más afilado, o quitarle las que insiste en usar mal. Puedes cambiar cómo está organizado el repositorio para que el agente encuentre el archivo correcto en vez de inventarse uno. Puedes agregar un hook que corra la batería de tests después de cada edición y rechace los cambios que rompan algo. Puedes partir un trabajo en piezas más pequeñas para que el agente nunca cargue en la cabeza más de lo que puede sostener. Nada de eso toca el modelo. Todo eso cambia lo que el agente hace. Ese menú — largo, mundano, completamente bajo tu control — es la superficie sobre la que trabaja la harness engineering.
Y uno de los componentes que Trivedy lista, justo al lado de las herramientas y la orquestación, son las skills. Ese es el puente con lo que escribí sobre las skills en esta serie. Una skill le enseña al agente una capacidad que no tenía. El harness es el sistema más grande que decide cuándo se ejecuta esa capacidad, si el agente tenía permiso de ejecutarla, y si el resultado es lo bastante bueno para conservarlo. Las skills son un componente dentro del harness. El harness es el marco del que cuelgan las skills.
Por qué la palabra apareció en 2026
El término viene de Mitchell Hashimoto — la persona detrás de Terraform y de buena parte de HashiCorp — que lo nombró en febrero de 2026 en un ensayo sobre su propia adopción, lenta y testaruda, de la IA. Uno de los pasos que describe es “engineer the harness” (“ingeniar el harness”), y su definición es la idea entera comprimida en una frase: “anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again” (“cada vez que encuentras que un agente comete un error, te tomas el tiempo de ingeniar una solución para que el agente nunca vuelva a cometer ese error”).
Eso es todo. Esa es la disciplina. No un framework, no un producto — un hábito. Cada error se vuelve un arreglo permanente, para que el mismo error no pueda volver.
Quiero ser preciso con lo que Hashimoto inventó y lo que no, porque el crédito importa y es fácil exagerarlo. Él nombró la práctica. La cosa en sí — un andamiaje envuelto alrededor de un modelo — ya estaba en uso y ya se llamaba harness; Anthropic, por ejemplo, describía el Claude Agent SDK como “a general-purpose agent harness” (“un harness de agente de propósito general”) en 2025. Así que esto no es un invento nuevo con fecha de lanzamiento. Es una actividad vieja que por fin recibió un nombre, y el nombre pegó porque mucha gente lo necesitaba al mismo tiempo.
La razón por la que lo necesitaban al mismo tiempo es la parte más interesante. Durante dos años el cuello de botella fue el modelo: no era lo bastante bueno, así que esperabas el siguiente. En algún punto del último tramo eso dejó de ser cierto. Los modelos se volvieron lo bastante buenos como para que el factor limitante se moviera. La pregunta dejó de ser ¿puede escribir el código? y pasó a ser ¿puedo confiar en que escriba el código, una y otra vez, sin que yo vigile cada línea?. Esa segunda pregunta no es un problema de modelo. Es un problema de ingeniería sobre el entorno en el que pones el modelo — y los problemas de ingeniería reciben disciplinas, y las disciplinas reciben nombres.
Guides y sensors
El desglose más útil de cómo funciona de verdad un harness viene del artículo de Martin Fowler, que lo parte en dos mitades. Están las guides (guías) — controles que actúan antes de que el agente haga algo, para desviarlo de la mala jugada desde el principio. Y están los sensors (sensores) — controles que actúan después, para atrapar lo que salió mal y devolverlo de vuelta para que el agente se corrija. Feedforward y feedback. Dirigir hacia adelante, revisar hacia atrás.
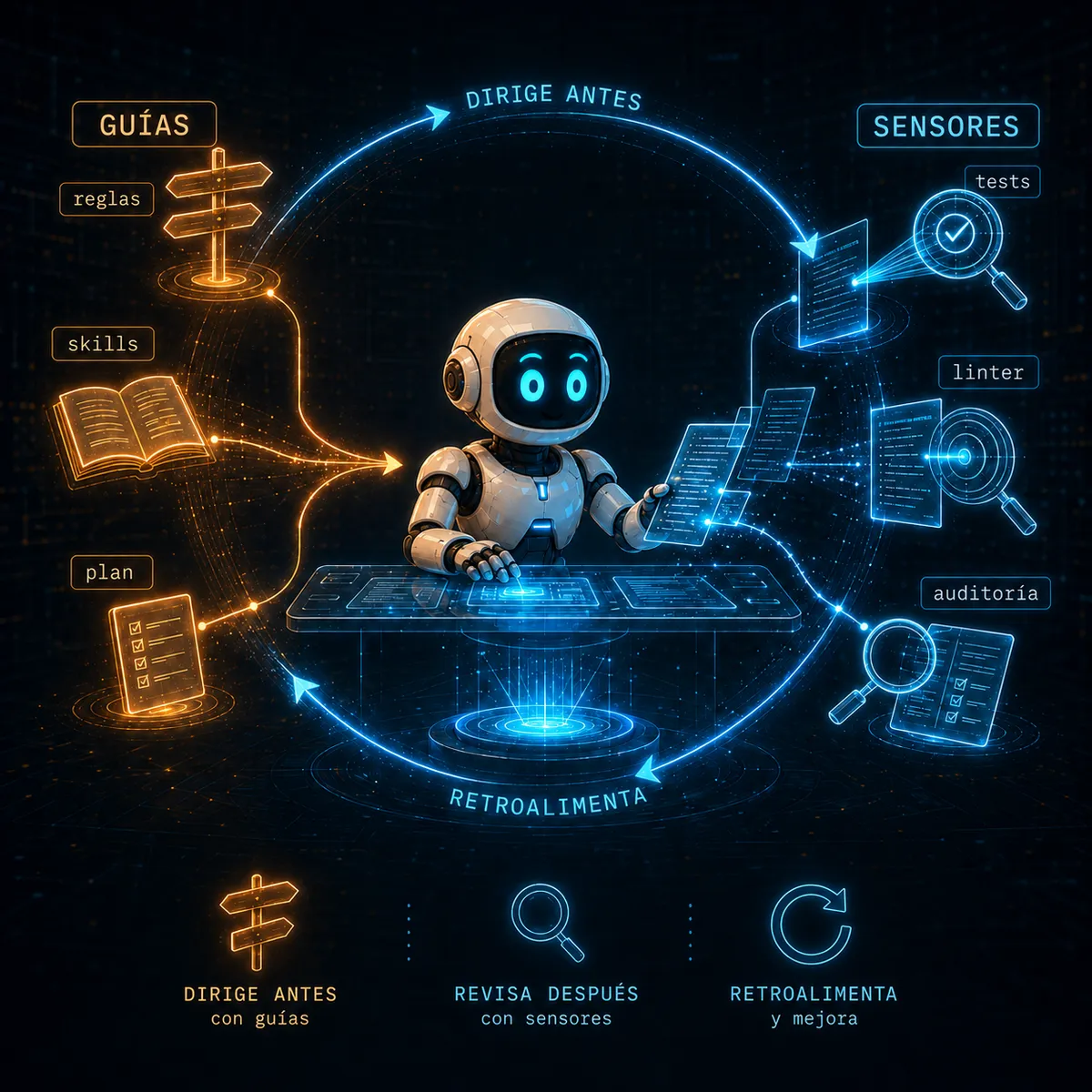
Fowler traza además una línea a la que vuelvo seguido, entre dos tipos de revisión. Algunas son computacionales — deterministas y rápidas, del tipo que una máquina zanja con un sí o un no: un test pasa o falla, un tipo cuadra o no, un linter está contento o no lo está, un grep encuentra una tilde faltante o no la encuentra. Otras son inferenciales — semánticas y más lentas, donde le pides a otro modelo que juzgue si un texto está en la voz correcta o si un cambio es de verdad seguro. Quieres que las revisiones computacionales hagan todo lo que puedan, porque son baratas y nunca se cansan; reservas las inferenciales para los juicios que una expresión regular no puede hacer.
Todo esto puede sonar académico hasta que lo aterrizas en un repositorio real — por ejemplo, el de este blog. Las guías son las cosas que escribí para que el agente las lea antes de actuar: el AGENTS.md del proyecto con sus reglas obligatorias, las skills que codifican cómo hacer un trabajo específico, el plan que obliga al agente a tomar una tarea a la vez en lugar de correr a través de diez. Los sensores son todo lo que corre después: el build, el chequeo de tipos, el linter, el grep de tildes, la auditoría que lee el post entero contra una lista antes de dejarlo acercarse a la publicación. Nada de eso hace al agente más inteligente. Todo eso hace que los errores del agente sean más baratos de atrapar e imposibles de publicar.
Los humanos dirigen, los agentes ejecutan
Si quieres ver hasta dónde llega esto cuando alguien lo empuja al límite, el reporte más claro que he leído es el de OpenAI, escrito por Ryan Lopopolo. Su tesis son cuatro palabras: “Humans steer. Agents execute.” (“Los humanos dirigen. Los agentes ejecutan.”).
Los números detrás de esa tesis: un producto interno en beta, construido a lo largo de cinco meses, con — esta es la afirmación, dicha sin rodeos — cero líneas de código escritas a mano. “Every line of code,” escribe, “application logic, tests, CI configuration, documentation, observability, and internal tooling, has been written by Codex” (“cada línea de código — lógica de la aplicación, tests, configuración de CI, documentación, observabilidad y herramientas internas — fue escrita por Codex”). Un equipo que empezó con tres ingenieros y creció a siete entregó alrededor de 1.500 pull requests, unos 3,5 por ingeniero al día, sumando cerca de un millón de líneas. Su propio estimado es que tomó algo así como una décima parte del tiempo que habría tomado escribirlo a mano.
Podría sostener esos números con pinzas — es un equipo, un producto interno, su propio estimado, una empresa con un interés evidente en el resultado. Pero no me hace falta tomarle la palabra a OpenAI, porque tengo la versión a mi escala: este mismo repositorio. El blog donde estás leyendo esto acumula casi 1.500 commits — la gran mayoría escritos en los últimos pocos meses — y todos han sido obra de agentes de IA. Yo no escribo el código: dirijo — decido qué se construye, reviso lo que importa — y mantengo el harness afinado para que el resultado de los agentes sea confiable y de calidad. Y lo que he comprobado es lo mismo que reporta Lopopolo: cuando dejas de escribir el código, tu tiempo se va al harness — el repositorio organizado para que un agente lo pueda navegar, los invariantes forzados de forma central para que un agente no pueda romper la arquitectura en silencio, las puertas de merge livianas para que el progreso no se atasque. La disciplina aparece en el andamiaje y no en el código. El trabajo no desapareció. Se movió una capa hacia arriba.
Es el mismo movimiento en los dos extremos del dial — hasta la cifra rima: sus 1.500 pull requests, los casi 1.500 commits de este blog. El instinto es idéntico a cualquier escala: no te vuelvas mejor corrigiendo al agente, vuélvete mejor construyendo el sistema que hace que corregirlo sea innecesario.
Las specs son las reglas que el harness hace cumplir
Hay una idea hermana que aparece en las mismas conversaciones — el spec-driven development (desarrollo dirigido por especificaciones) — y es fácil confundirla con una tendencia rival. No lo es. Es la otra mitad de lo mismo. Loiane Groner plantea bien la relación: “specs define the target state; the harness defines the control system” (“las especificaciones definen el estado objetivo; el harness define el sistema de control”). O, todavía más directo: “Specs-driven development is what makes harness engineering practical. Without it, there is nothing concrete for the harness to enforce” (“el desarrollo dirigido por especificaciones es lo que hace práctica la harness engineering; sin él, no hay nada concreto que el harness pueda hacer cumplir”).
Un harness sin spec es un termostato sin temperatura puesta — un sistema de control que regula hacia nada. La spec es lo que escribes para que el harness tenga un objetivo contra el cual sostener el trabajo. Dices qué significa correcto — las metas, los contratos, los criterios de aceptación — y el trabajo del harness pasa a ser demostrar, una y otra vez, que la salida del agente sigue cayendo dentro de esas líneas. La spec dice dónde; el harness te mantiene ahí.
Por esto también el conjunto encaja como una serie y no como un montón de palabras de moda. Dirigir agentes es el rol humano que empecé describiendo en esta serie. Las skills son las capacidades que el agente recoge. Las specs son cómo escribes lo que quieres. Y el harness es la máquina que hace todo eso lo bastante confiable como para de verdad apoyarte en ello.
Un harness se construye una cicatriz a la vez
Nada de lo que existe en el harness de este blog se planeó como un sistema. Cada pieza es una cicatriz — el residuo de alguna vez específica en que un agente hizo algo que yo no quería, y decidí que una vez era suficiente. Hasta las correcciones que doy en una sesión se vuelven reglas escritas que la siguiente lee antes de empezar. La corrección deja de ser algo que tengo que acordarme de dar y se vuelve algo que el sistema da en mi nombre.
La razón por la que todo esto importa es que cambia hacia dónde va tu atención. Una vez que el modelo deja de ser el cuello de botella, sacarle más a tus agentes deja de tratarse de perseguir el próximo lanzamiento y empieza a tratarse del sistema que construyes alrededor del que ya tienes. Ese es un tipo de trabajo que la mayoría ya sabemos hacer — es solo ingeniería, la disciplina sin glamour de hacer que una cosa sea confiable — apuntada a un objetivo nuevo.
Y no busca sacar al humano del medio. Fowler tiene una frase sobre esto que me parece exactamente correcta: un buen harness “should not necessarily aim to fully eliminate human input, but to direct it to where our input is most important” (“no debería buscar necesariamente eliminar del todo la intervención humana, sino dirigirla hacia donde nuestra intervención es más importante”). Esa es la versión honesta de la promesa. No cero criterio — criterio gastado donde cuenta.
Sigo construyendo.
Recursos
- My AI Adoption Journey — el ensayo de Mitchell Hashimoto donde la “harness engineering” recibe su nombre
- The Anatomy of an Agent Harness — Vivek Trivedy (LangChain) sobre
Agent = Model + Harnessy el resultado de Terminal Bench - Harness engineering: leveraging Codex in an agent-first world — el reporte de campo de Ryan Lopopolo desde OpenAI
- Harness engineering for coding agent users — Martin Fowler sobre guides, sensors y revisiones computacionales vs inferenciales
- Harness Engineering: the missing layer in specs-driven AI development — Loiane Groner sobre cómo encajan las specs y los harnesses
- Las skills y los planes de este blog — el harness usado como ejemplo a lo largo del post

Sergio Alexander Florez Galeano
CTO y Cofundador en DailyBot
Ingeniero de software y emprendedor colombiano (DailyBot, YC S21). Escribo sobre agentes de IA, herramientas para desarrolladores, startups y el arte de la ingeniería de software, y construyo este sitio a la vista de todos en XergioAleX.com.
Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.