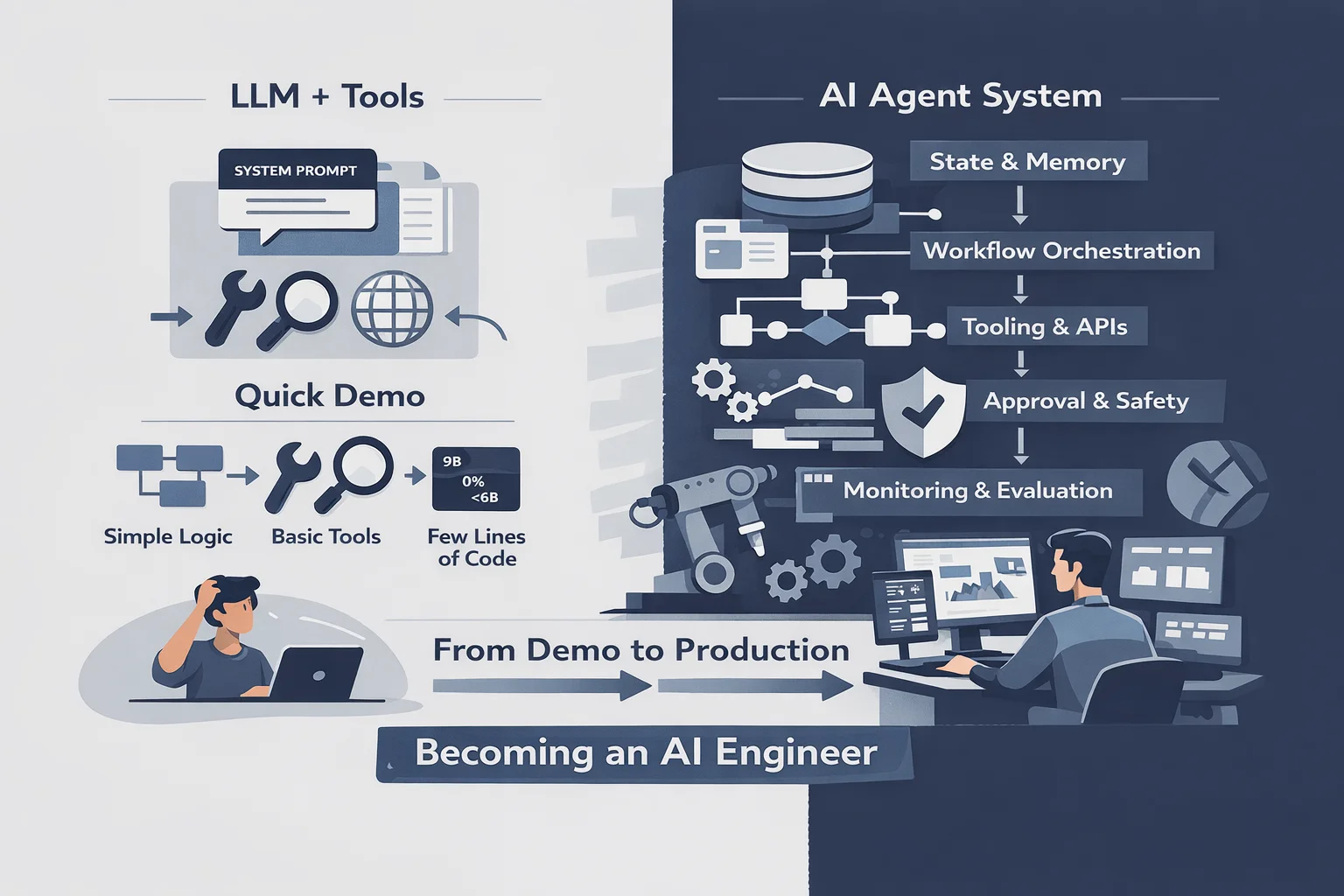
When you think about building an AI agent today, the picture in your head is probably something like this: take an LLM, give it a system prompt, wire up a few functions it can call, put everything in a loop. The model reasons, picks a tool, gets a result, reasons again. A few lines of Python. Done.
That mental model isn’t wrong, exactly. An agent does need a model, and it does need tools. But calling that an agent is like calling a web application “a server that returns HTML.” Technically true. Practically useless as a design principle. The moment you try to build something that survives real usage — real users, real failures, real stakes — that simple picture collapses.
The quickstarts and demos reinforce this. They’re optimized for the “aha moment” — getting something working in five minutes. That’s fine for marketing. It’s actively misleading for engineering. The quickstart doesn’t show you what happens when the agent needs to remember something from three steps ago. It doesn’t show you what happens when a tool fails and the agent needs to decide whether to retry or escalate. It doesn’t show you how to know if the agent is actually working correctly, or just producing plausible-sounding output.
This is precisely why frameworks like LangChain and LangGraph exist — to handle the complexity that the quickstart version ignores. State management, multi-step orchestration, tool coordination, checkpointing. These frameworks are real engineering tools, and some of them are excellent. But here’s the thing I keep running into: the framework gives you better tools for implementing solutions. It doesn’t design the solutions for you. The architecture — the decisions about what to keep in state, how memory should work, which tools need safety gates — that’s still on you.
That realization — that building agents is less about learning a library and more about becoming a new kind of engineer — is what Building Agents is about.
Where the Simple Model Breaks
The gap between a simple agent and a reliable one is not incremental — it’s architectural. And it shows up fast. Take a common scenario: an agent that gathers research from multiple sources, synthesizes it, drafts a structured document, and flags what needs human review. Three tools, one clear goal, maybe 200 lines of orchestration code. Should be straightforward.
In practice, these systems tend to work about 60% of the time. The other 40% is a mix of failures that are hard to predict and harder to debug:
Context collapse. After three or four tool calls, the context window fills up with intermediate results and the model starts treating old observations as new ones. The agent loses track of where it is in the workflow — not because the tools failed, but because nobody designed the state to survive more than a few turns.
Tool misuse. The agent calls the right tool with the wrong parameters — not randomly wrong, but confidently wrong. It constructs a plausible interpretation of what the tool expects, and that interpretation happens to be incorrect. Usually a sign that the tool schemas are ambiguous, not that the model is broken.
Hallucination loops. The agent repeats the same search query with slightly different phrasing, each time getting slightly different results, none satisfying, until it times out or produces a confused summary that mixes facts from four different iterations. No loop detection, no exit condition — the system just spirals.
None of these are model failures. The model does exactly what you’d expect a language model to do given the inputs it receives. These are architecture failures. The system doesn’t have proper state management. The tool definitions don’t enforce parameter contracts. There’s no checkpoint mechanism, no way to inspect what’s actually happening inside a multi-step run.
Anthropic’s Building Effective Agents guide draws this line clearly: what separates a working demo from a working system is everything that happens between tool calls — the orchestration, the state transitions, the routing decisions. That “between” is where most agent systems fall apart.
What a Real Agent Actually Contains
Here’s the honest list. What a production agent system actually requires:

Model layer — Which model, which provider, how to handle rate limits and failures. Easier than it sounds until you need fallbacks.
Prompt engineering — Not just system prompts. The full context strategy: what goes in the static prompt, what’s injected dynamically, how to structure tool results, how to handle long conversations without degrading quality.
State management — Everything the agent knows at each step. Not just “the conversation history” but: current task, progress checkpoints, intermediate results, what’s been tried, what’s pending. This is its own design problem.
Short-term memory — What the agent remembers within a session. Not the same as the context window. You have to decide what to keep, what to compress, what to discard.
Long-term memory — What the agent remembers across sessions. Requires storage, retrieval, and decisions about what’s worth remembering. Most demos skip this entirely.
Knowledge retrieval (RAG) — How the agent accesses knowledge the model wasn’t trained on — company docs, internal policies, domain-specific data. Chunking strategy, embedding choice, retrieval method, reranking. A field with its own set of failure modes.
Tool ecosystem — Not just “functions the model can call” but: schema design, parameter validation, error handling, side effect management, permission boundaries. Each tool is a surface for failure.
Workflow orchestration — How multi-step tasks are structured, sequenced, branched, and rejoined. When to run in parallel, when to wait, when to bail.
Approval and safety layer — What requires human confirmation. What should never happen automatically. How to implement hard stops. Often an afterthought. Should be a first-class design concern.
Observability and tracing — Can you see what the agent actually did? Which tool calls were made, with what parameters, in what order, with what results? Without this, debugging is guessing.
Evaluation — How do you know if the agent is working correctly? Not just “did it produce output” but “did it produce the right output?” This is probably the most under-discussed layer in the entire field.
Each of these is a distinct engineering discipline. Most of them didn’t exist as a named field five years ago. All of them are required. You can skip some of them in a simple agent. You cannot skip any of them in a serious one.
This series will explore each of these layers — what they actually involve, where they break, and what it takes to get them right.
The Landscape Right Now
The ecosystem that’s grown up around agent building is — honestly — staggering. Not in a hype way. In a “this signals something real” way.
On the framework and SDK side: LangChain/LangGraph has become the default starting point for most teams building agents — the largest community, the most integrations, and probably the most explicit treatment of agent state available in open-source tooling. CrewAI focuses on multi-agent orchestration — multiple agents collaborating on tasks — and has found a strong following for that specific pattern. AutoGen/AG2, Microsoft’s approach, takes a conversational multi-agent model. Mastra is a TypeScript-first framework worth watching if you’re building in a JavaScript ecosystem. Vercel AI SDK goes web-native, streaming-first.
Then there are the first-party SDKs from the model providers themselves. Anthropic shipped the Claude Agent SDK. OpenAI launched their Agents SDK. Google released ADK (Agent Development Kit). When model providers start shipping opinionated frameworks for building with their own models, it means they’ve moved past “here’s the API” to “here’s how to actually build with this.”
And underneath everything, there’s the protocol layer. MCP — Model Context Protocol — hit 97 million monthly SDK downloads before being donated to the Agentic AI Foundation for open stewardship. Google’s A2A (Agent-to-Agent) protocol and OpenAI’s ACP are tackling agent interoperability. These are boring infrastructure moves. Boring infrastructure moves matter.
The observation I keep returning to: when Stripe, Coinbase, Google, Anthropic, Microsoft, and dozens of well-funded startups are all building agent infrastructure simultaneously, something real is happening. Not necessarily in the direction any individual company predicts, but real. This is not a fad that’s going to be footnoted in five years.
I have no idea which specific frameworks will win. That’s a separate question. What the ecosystem tells you is that the underlying problem — building reliable agent systems — is hard and important in equal measure. The infrastructure investment confirms the problem’s existence.
Why “AI Engineer” Is Starting to Mean Something
Swyx coined the term “AI Engineer” in 2023 in an essay on Latent Space. At the time it felt aspirational — a way of describing what some people were starting to do before the role had a name. Three years later it’s a job title in thousands of postings, with specific expectations attached.
Here’s what companies are actually hiring for: not “can you call the OpenAI API” — anyone can do that in minutes. They want: can you design state management for a multi-turn agent workflow? Can you implement a memory system that scales? Can you debug an agent that’s producing subtly wrong outputs? Can you build an evaluation pipeline that tells you whether a new model version is actually better? Can you design tool schemas that reduce misuse without over-constraining the model’s flexibility?
That’s a different skillset from ML Engineering, which is focused on training, fine-tuning, and evaluation at the model layer. It’s also different from traditional software engineering, though it draws heavily on it. The AI Engineer operates in the space between: they understand models well enough to work with them reliably, and they understand systems well enough to build infrastructure that makes models useful.
I think the role will keep crystallizing. Not because someone decided to invent a new role, but because the work demands it. When your system’s core intelligence is probabilistic and the rest of the system has to be reliable, you need engineers who can think in both registers simultaneously.
The Tension at the Heart of It All
Here’s what I find most interesting about building agents — and what I think most tutorials miss entirely.
We’ve spent thirty years building deterministic systems. Input → logic → output. The same inputs always produce the same outputs. Debugging means tracing the logic. Testing means covering the edge cases. Reliability means writing the logic correctly.
Agents break this. Part of the system’s intelligence is probabilistic — the same inputs might produce different outputs on different runs. The model reasons, and reasoning has variance. That’s not a bug. It’s the feature. The model’s ability to handle novel situations, to generalize, to produce useful outputs for inputs it’s never seen — all of that comes from the same probabilistic nature that makes it unpredictable.
But the reliability of the system still has to be engineered. Users don’t care that the underlying model is probabilistic. They care whether the agent does what it’s supposed to do, consistently, without making catastrophic mistakes.
So you end up with this tension: embrace the probabilism at the model layer, engineer the reliability everywhere else. Structured outputs to constrain what the model returns. Validation to check whether it makes sense. Retry logic for when it doesn’t. Approval gates for irreversible actions. Evaluation to verify the system is actually improving over time.
This tension defines every design decision in agent systems. How much do you trust the model? Where do you add guardrails? What do you hardcode versus what do you leave flexible? There’s no universal answer — it depends on the task, the stakes, the user. But thinking through these tradeoffs is, I’d argue, the core intellectual skill of the AI Engineer.
Civil engineers learned to build with wood, then steel, then concrete. Each material required new disciplines — new ways of thinking about load, failure, tolerances. LLMs are a new material for building software. The discipline is still being invented.
The Discovery That Keeps Repeating
There’s a pattern that almost everyone building agents goes through. It looks something like this:
“I’ll just use a framework” → “why does state keep getting weird?” → “okay I need proper state design” → “wait, memory is its own entire problem” → “these tool schemas are causing misuse” → “I have no idea if this is actually working correctly” → “I can’t debug this without traces.”
Each new capability reveals a new layer. Each layer has its own failure modes, its own design patterns, its own body of knowledge. You don’t see the next layer until the previous one forces you to look.
The debugging sessions are what change your perspective. An agent treats a task it already completed as if it were still pending — and the bug isn’t in any single line of code. It’s in the state schema. Two different parts of the workflow write to the same key with different assumptions about what the value represents. The model isn’t wrong. The state design is wrong. That kind of failure doesn’t appear in any quickstart tutorial. It only appears when the system is complex enough to have competing assumptions — which is to say, when it starts resembling a real system.
This is the moment most builders shift from “I’m learning a framework” to “I’m learning a craft.” The framework handles the plumbing. The craft is everything above it: the decisions about structure, boundaries, trust, and failure recovery that no library can make for you.
The companion series I’ve been writing — Working with Agents — explores what it’s like to work with agents day-to-day: the productivity shift, the workflow changes, what it does to how you think about work. This series is about what happens when you try to build them. It’s the layer underneath that experience.
Why Frameworks Are Not Enough
This is, I think, the most important thing I can tell you going into this series.
Frameworks solve syntax, not architecture. You can know LangGraph’s StateGraph API inside out and still build a terrible agent. The framework gives you tools. It does not make your design decisions.
The framework doesn’t teach you: how to design state for your specific workflow, when short-term memory is sufficient versus when you need persistent long-term storage, which tools should be read-only versus which ones have side effects that require approval gates, how to structure an evaluation set that would actually tell you if the agent is working correctly, what to do when the model confidently returns something plausible but wrong.
Django doesn’t teach you to build a good web app. Rails doesn’t teach you good database design. LangGraph doesn’t teach you good agent design. These tools implement patterns well. They don’t choose the patterns for you.
This doesn’t mean frameworks are bad — LangGraph’s explicit state model and LangSmith’s tracing have become standard tools for good reason. The LangChain community has produced more useful agent patterns than anywhere else in the ecosystem. These tools are necessary — but the design decisions that actually determine whether an agent works or not live above the framework layer. That’s what this series is about: Building Agents.
The Craft Analogy
I keep coming back to this.
Building agents is closer to learning a craft than learning a technology. In the same way that woodworking isn’t just “knowing what a chisel is” — it’s understanding grain, joint design, what happens when the wood moves with humidity, the specific feel of a cut going right versus going wrong. You can read about grain patterns for a year and still produce furniture that cracks. The knowledge lives in the hands and in the accumulated experience of failures.
Architecture works the same way. You can know all the principles — load-bearing, materials science, structural systems — and still design a building with a flaw that only reveals itself when the wind hits from a specific direction at a specific season. The discipline is built from pattern recognition accumulated through encounter with real systems.
Agents are like this. The conceptual models are necessary but insufficient. The moment you build something with real state requirements and real tool interactions, edge cases appear that no tutorial anticipated. Your memory system retrieves the wrong context at a critical step and you have to decide: add more retrieval logic, or simplify the schema? Your tool fails partway through a multi-step operation and the agent needs to decide whether it completed or not — and your state management either captures enough to recover, or it doesn’t. These are judgment calls. Judgment comes from experience.
This is why I’m writing the series as stories, not specifications. Craft knowledge lives in stories, not in documentation. The documentation tells you what functions exist. The stories tell you when to use them and what happens when you don’t.
Where This Goes
An agent that works once is a demo. An agent that works reliably is architecture. The distance between the two is everything this series is about.
If you’ve ever built an agent that worked in testing and fell apart in production — or if you’re about to start building one and want to skip some of the pain — the next chapters will go deep into each layer: state, memory, retrieval, tools, reliability, observability. Not as theory, but as engineering problems that have real solutions and real tradeoffs.
The mental model most people carry — LLM plus tools, a few lines of code — isn’t wrong as a starting point. But it’s a starting point for a journey that turns out to be much longer and more interesting than it looks from the outside.
Resources
- Anthropic: Building Effective Agents — Foundational guide to agent design patterns from Anthropic; the clearest single reference for thinking about agent architecture
- Andrew Ng: Agentic Design Patterns — The canonical taxonomy: reflection, tool use, planning, multi-agent; useful mental models for structuring agent behavior
- Lilian Weng: LLM Powered Autonomous Agents — A deep academic survey of agent architectures that holds up well as a reference even years after publication
- Chip Huyen: Building A Generative AI Platform — Engineering discipline framing for AI systems; how production AI infrastructure actually works
- Swyx: Rise of the AI Engineer — The essay that coined the role and defined the skillset; still the best single articulation of what separates AI engineering from adjacent disciplines
- LangGraph Documentation — The most explicit framework treatment of state and agent orchestration available in open source
- Harrison Chase: What is a Cognitive Architecture? — The concept of agent systems as cognitive architectures; a useful reframe that connects agent design to how systems reason
- Model Context Protocol (MCP) — The open standard for connecting AI to tools and data sources; now stewarded by the Agentic AI Foundation
- Claude Agent SDK — Anthropic’s first-party SDK for building agent systems with Claude
- OpenAI Agents SDK — OpenAI’s agent framework, with good documentation on handoffs and guardrails
- Simon Willison: Agentic Engineering Patterns — Practical patterns for building with coding agents; the most grounded and honest perspective on what actually works
- Hamel Husain: Your AI Product Needs Evals — Practical approaches to building evaluation pipelines for LLM-based systems; the layer most people skip

Stay in the loop
Get notified when I publish something new. No spam, unsubscribe anytime.
No spam. Unsubscribe anytime.