Llegando al 100 en isitagentready.com: lo que tu web necesita en la era de los agentes

Hace unos días publiqué mi recap de la Agents Week 2026 de Cloudflare. De esa semana hubo una herramienta que encajaba tan bien con mi serie AEO: De Invisible a Citado que pedía capítulo propio: isitagentready.com. Convierte una pregunta vaga — “¿mi sitio está listo para ser descubierto por la IA?” — en un solo número de 0 a 100. Cuatro categorías, cada una con su spec, cada una con su chequeo pasa/no-pasa.
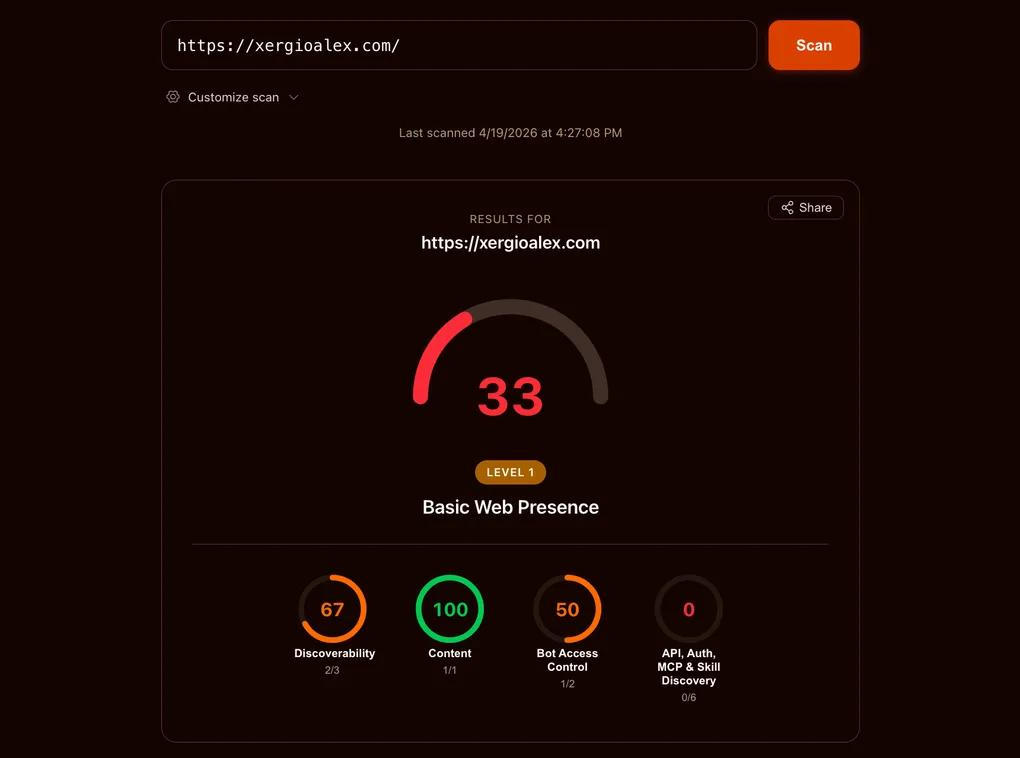
Escaneé mi sitio al primer intento y saqué 33/100.
Lo interesante de ese 33 no fue que faltara trabajo. Fue qué tan distinto era el trabajo que faltaba: no era SEO ni performance ni accesibilidad — era una capa nueva. Archivos .well-known/, headers que ningún humano va a leer, una API de navegador que apenas existe en draft. La era de los agentes no se anunció en una keynote; se anunció con un scorecard que de repente califica algo que no sabíamos que se calificaba.
Este capítulo es una guía práctica: para cada una de las cuatro categorías que mide el scorecard, qué requiere realmente el spec, y exactamente qué puse en mi sitio para ganar cada punto. Si tu sitio es de contenido, marketing o documentación, esta guía aplica casi sin ajustes.
Antes de entrar en materia, una nota sobre el 33: ya venía con ventaja. La categoría Content marcaba 100 desde el primer escaneo porque mi sitio ya había empezado a hablar el idioma de los agentes. Tres piezas estaban en su lugar:
-
Markdown para bots. En un post anterior, Markdown for Agents, configuré el sitio para que cuando un bot de IA pide una página con la cabecera
Accept: text/markdown, el servidor le entregue una versión limpia en Markdown en lugar del HTML enredado que solo un navegador necesita — Markdown es el formato que los modelos prefieren leer. Puedes probarlo contra esta misma página:curl -H "Accept: text/markdown" https://xergioalex.com/es/blog/aeo-reaching-100-isitagentready/ -
llms.txtyllms-full.txt. Dos archivos que funcionan como un mapa del sitio, pero pensados para agentes en vez de buscadores como Google. -
Detección de bots de IA. Un fragmento de código en
functions/_middleware.tsque corre en el servidor antes de cada respuesta, identifica bots de IA conocidos y deja registro de cada visita.
Lo que viene en el resto del post son las otras tres categorías: qué pide cada una, y exactamente qué armé para cubrirla.
Qué mide realmente el scorecard
Antes del trabajo, una orientación corta. isitagentready.com divide “listo para agentes” en cuatro categorías, cada una con sus propios chequeos:
- Content — ¿tu contenido está en una forma que los agentes de IA pueden parsear sin problema? (Endpoints Markdown, content negotiation, datos estructurados.)
- Discoverability — ¿un agente que haga un solo
HEAD /puede encontrar la superficie programática de tu sitio? (Link headers, metadata canónica.) - Bot Access Control — ¿les dijiste a los crawlers de IA qué pueden y qué no pueden hacer con tu contenido? (Señales en
robots.txt.) - APIs, Auth, MCP & Skill Discovery — ¿tu superficie programática está descrita en los archivos canónicos
.well-known/*, con metadata OAuth para discovery y MCP server cards? (Seis documentos JSON más una API de navegador.)
Cada categoría que mide isitagentready.com tiene un archivo SKILL.md asociado: un documento corto, definido por Cloudflare, que funciona como manual de una sola capacidad. Te dice qué chequea la herramienta, qué archivo o cabecera HTTP debe servir tu sitio, cuál es el ejemplo mínimo válido y qué errores son comunes. Es el contrato entre lo que tu sitio publica y lo que un agente espera encontrar.
Antes de escribir código, los ocho SKILL.md que cubren esas cuatro categorías fueron mi fuente de verdad. Cada artefacto del post coincide byte por byte con sus ejemplos.
Donde un spec pedía un campo que no aplica a mi caso, lo llené con honestidad y un _comment explicando la situación; donde aceptaba un JSON mínimo, envié el mínimo. Todo es reproducible.
Un aviso antes del trabajo. Desde que publiqué esto por primera vez, isitagentready.com agregó una quinta categoría — Commerce — que chequea si los agentes de IA pueden pagarle a tu sitio. Para un sitio de contenido que no vende nada marca not checked, que es lo correcto. Qué chequea, y por qué dejo ese círculo en gris, te lo cuento un poco más adelante.
El 33/100 de partida
Así se veía el desglose en la primera pasada:
| Categoría | Score | Qué faltaba |
|---|---|---|
| Content | 100 / 100 | Nada — los endpoints .md ya estaban vivos. |
| Discoverability | 67 / 100 | Header Link: en las respuestas de / y /es/. |
| Bot Access Control | 50 / 100 | Directiva Content-Signal en robots.txt. |
| APIs, Auth, MCP & Skills | 0 / 100 | Los seis documentos .well-known/* + WebMCP. |
La mayoría de sitios de contenido hoy estarían más o menos en el mismo punto. Ese es el punto del scorecard: define una nueva línea base, no una revisión de la vieja. El trabajo se divide en tres baldes — un par de edits de headers / robots, seis documentos JSON bajo .well-known/, y un pequeño componente de navegador.
Hora de ir categoría por categoría.
Content: ya en 100 (gracias a trabajo previo)
Content estaba en 100 desde el primer día gracias a trabajo anterior en la serie. Markdown for Agents montó una capa de content negotiation que sirve versiones limpias en Markdown de cada página a los crawlers de IA — y endpoints .md independientes en rutas predecibles. El chequeo de Content del scorecard busca exactamente esa estructura: si un crawler manda Accept: text/markdown, ¿el servidor responde con Markdown real en vez de una sopa de HTML que tiene que raspar?
Para xergioalex.com, la respuesta es sí. El middleware de Cloudflare Pages en functions/_middleware.ts observa los headers Accept entrantes; si un bot de IA pide Markdown, el middleware trae el archivo .md correspondiente del build output y lo devuelve con Content-Type: text/markdown; charset=utf-8. Cada página HTML tiene su contraparte .md — verificado por el script de paridad md:check que corre en CI.
Discoverability: una línea en _headers
El chequeo de Discoverability busca un header de respuesta HTTP Link: apuntando a una descripción legible por máquina de la superficie programática de tu sitio. RFC 8288 define el formato; RFC 9727 §3 registra api-catalog como tipo de relación válido. El SKILL.md acepta cualquiera de api-catalog, service-desc, service-doc, o describedby — escogí el más específico y lo apunté al API catalog que vamos a construir más adelante.
En Cloudflare Pages, los headers de respuesta viven en public/_headers:
/
Link: </.well-known/api-catalog>; rel="api-catalog"
/es/
Link: </.well-known/api-catalog>; rel="api-catalog"Literalmente ese es todo el fix. Discoverability subió de 67/100 a 100/100. Tanto la homepage en inglés como la de español emiten el header en cada respuesta.
Un detalle que me costó un minuto: Cloudflare Pages aplica las reglas de _headers en el edge, no en el build de Astro. Los headers no aparecen en un npm run dev local. Verifiqué buildeando local con npm run build, corriendo wrangler pages dev dist, e inspeccionando la respuesta con curl -sI http://localhost:8788/ — ahí sí salen.
Dos líneas de config, un archivo, listo.
APIs, Auth, MCP & Skill Discovery: seis documentos JSON + un bridge de navegador
Esta es la categoría donde 0 se convierte en 100 de un solo golpe — seis de mis ocho artefactos viven aquí, más el bridge WebMCP. El scorecard chequea:
/.well-known/api-catalog— un linkset listando tus APIs con enlaces a sus specs OpenAPI y docs humanas./.well-known/oauth-authorization-server— metadata del authorization server OAuth./.well-known/oauth-protected-resource— qué recursos están protegidos y por qué authorization servers./.well-known/mcp/server-card.json— el MCP server card anunciando las capacidades de tu sitio./.well-known/agent-skills/index.json— un índice de las agent skills que tu sitio publica, cada una con un digest SHA-256.- Una superficie WebMCP a nivel navegador — agentes corriendo en el browser del usuario pueden llamar
navigator.modelContext.registerTool()para encontrar las tools que expones.
La decisión honesta sobre OAuth
Antes de construir nada, tenía una pregunta de diseño que resolver. xergioalex.com es un sitio de contenido estático. Tiene endpoints JSON de solo lectura — /api/posts.json, /api/series/{lang}, y similares — pero ningún recurso protegido, ningún auth de usuario, ningún bearer token. Los chequeos OAuth del scorecard igual quieren seis campos obligatorios en /.well-known/oauth-authorization-server y dos en /.well-known/oauth-protected-resource. ¿Qué pones en esos campos cuando no tienes nada que proteger?
Tres opciones sobre la mesa:
- Stub honesto — publicar los campos obligatorios con endpoints en rutas reservadas pero no funcionales. Agregar un campo
_commentexplicando la situación. - Apuntar a un issuer upstream real — solo honesto si el sitio realmente usa uno. No lo hace.
- Saltarse — aceptar la deducción del scorecard, no llegar al 100/100.
Escogí la opción 1. El spec pide presencia de los campos, no función de los endpoints. Un agente que lea la metadata de discovery puede ver, en el mismo documento, que el authorization endpoint es una ruta reservada que no acepta flujos OAuth reales todavía. El campo _comment lo deja explícito:
{
"_comment": "xergioalex.com has no protected APIs today. This document is published for agent-readiness compliance per RFC 8414 / OIDC Discovery 1.0. Endpoints are reserved paths; they do not currently accept real OAuth flows.",
"issuer": "https://xergioalex.com",
"authorization_endpoint": "https://xergioalex.com/oauth/authorize",
"token_endpoint": "https://xergioalex.com/oauth/token",
"jwks_uri": "https://xergioalex.com/.well-known/jwks.json",
"grant_types_supported": ["authorization_code"],
"response_types_supported": ["code"]
}Para /.well-known/oauth-protected-resource, la forma honesta es una autoreferencia: este recurso está gobernado por el authorization server (stub) del mismo sitio. Es una tautología, pero una verdadera, y RFC 9728 lo permite.
Traducción: la honestidad le gana al teatro. Documentos que apuntan a nada pero te dicen que apuntan a nada son mejores que documentos que mienten. Un agente puede razonar sobre eso.
El API catalog
RFC 9727 define el API catalog como un documento application/linkset+json — JSON con un Content-Type específico — en /.well-known/api-catalog. Cada entrada del linkset se ancla en una URL base y carga links[] con dos valores de rel requeridos: service-desc (spec legible por máquina, usualmente OpenAPI) y service-doc (documentación humana).
El sitio no tenía un spec OpenAPI, así que escribí uno mínimo en public/openapi.json — un documento 3.1 cubriendo /api/posts.json, /api/posts-en.json, /api/posts-es.json, /api/series/{lang}, y /api/timeline/{lang}. Más corto que un proyecto de fin de semana; los schemas se apoyan en type: array y type: object sin modelar cada campo exhaustivamente.
El catalog en sí apunta service-desc a ese archivo OpenAPI y service-doc a llms.txt (ya enviado desde el trabajo previo de Markdown for Agents):
{
"linkset": [
{
"anchor": "https://xergioalex.com/api/",
"links": [
{ "rel": "service-desc", "href": "https://xergioalex.com/openapi.json", "type": "application/json" },
{ "rel": "service-doc", "href": "https://xergioalex.com/llms.txt", "type": "text/plain" }
]
}
]
}El archivo vive en public/.well-known/api-catalog — sin extensión, a propósito. El Content-Type es application/linkset+json, no el default application/json, así que agregué un override en public/_headers:
/.well-known/api-catalog
Content-Type: application/linkset+json
Cache-Control: public, max-age=300, must-revalidateEste detalle me costó un rebuild. La primera versión se sirvió como application/json y me sorprendió que el scorecard la rechazara. El SKILL.md literalmente dice “NOT application/json” en la sección de trampas. Se me pasó. Lee tus specs.
MCP server card y el índice de skills
El MCP Server Card (SEP-1649) vive en /.well-known/mcp/server-card.json. La estructura son cuatro campos: serverInfo.name, serverInfo.version, transport.endpoint, y capabilities[]. El array capabilities toma valores string de tools, resources, prompts — strings planos, no un objeto anidado como había dibujado en el primer draft.
El índice de Agent Skills Discovery es donde se pone interesante. El RFC v0.2.0 de Cloudflare define /.well-known/agent-skills/index.json como un documento con un identificador $schema (opaco — no tiene que resolver) y un array skills[]. Cada entrada nombra una skill, enlaza a un archivo SKILL.md, e incluye un digest SHA-256 — una huella del archivo, misma idea que un hash de commit de Git — de los bytes servidos de ese archivo.
Pude haber escrito mis propios SKILL.md. Por ahora estoy en modo pointer: mi índice referencia los ocho SKILL.md canónicos de Cloudflare en isitagentready.com/.well-known/agent-skills/<skill>/SKILL.md, con el digest calculado desde los bytes servidos por Cloudflare al momento de generación. Un script pequeño en scripts/generate-agent-skills-index.mjs trae cada URL, la hashea, y escribe el índice:
async function sha256OfUrl(url) {
const res = await fetch(url);
const bytes = new Uint8Array(await res.arrayBuffer());
const hex = createHash('sha256').update(bytes).digest('hex');
return `sha256:${hex}`;
}La primera pasada produjo el digest equivocado. Había hasheado la representación local en memoria de la respuesta — pero el spec quiere los bytes como se sirven. Fix: un cambio de una sola línea, usar arrayBuffer() en vez de hacer un round-trip por text() a través de un string. El índice ahora tiene ocho entradas, cada una con un digest real que coincide con lo que sirve el CDN de Cloudflare.
El generador corre en prebuild, conectado en package.json:
"prebuild": "npm run generate:agent-skills-index",
"generate:agent-skills-index": "node scripts/generate-agent-skills-index.mjs"Cada build futuro regenera el índice desde los bytes vivos de Cloudflare. Si Cloudflare actualiza un SKILL.md, el digest se actualiza en el próximo deploy.
WebMCP: la superficie del navegador
El último chequeo de esta categoría es el único que no es un archivo estático. WebMCP es una API del navegador — navigator.modelContext.provideContext() — y el scorecard carga la página en un browser sin cabeza para ver si tu sitio publica alguna tool al cargar.
Cada tool necesita name, description, un inputSchema que sea JSON Schema válido, y un callback execute. El spec moderno las recibe todas de golpe vía provideContext({ tools }); una variante antigua las acepta una por una vía registerTool(tool, { signal }). El scanner hace timeout si ninguna de las dos llamadas ocurre dentro de su sesión de browser, así que el bridge tiene que hidratar temprano.
Escribí un componente Svelte 5 en src/components/agent/WebMCPBridge.svelte. No renderiza nada visible. Monta en client:load — hidratar al cargar la página, no en idle, para ganarle al timeout del scanner — feature-detecta la API, y publica tres tools de solo lectura que mapean a endpoints que el sitio ya expone. Los navegadores modernos toman el camino de provideContext; los shims legacy caen a registerTool con una señal de AbortController para poder revocar el registro cuando el componente se desmonte:
const tools = [
{
name: 'search_blog',
description: 'Search xergioalex.com blog posts by keyword.',
inputSchema: {
type: 'object',
properties: { q: { type: 'string' }, lang: { type: 'string', enum: ['en', 'es'] } },
required: ['q'],
},
execute: async ({ q, lang: l }) => { /* fetch /api/posts-{lang}.json, filter, return top 20 */ },
},
// list_series, open_post...
];
if (typeof mc.provideContext === 'function') {
mc.provideContext({ tools });
} else if (typeof mc.registerTool === 'function') {
for (const tool of tools) mc.registerTool(tool, { signal });
}Tres tools, todas de solo lectura: search_blog, list_series, open_post. Sin escrituras, sin acciones destructivas, nada cross-origin. El wiring es un import más un elemento dentro de MainLayout.astro. Cada página que use el layout — efectivamente todo el sitio público — ahora carga el bridge.
Bot Access Control: la directiva Content-Signal en robots.txt
El chequeo de Bot Access Control busca que tu sitio diga algo sobre cómo los crawlers de IA pueden usar tu contenido. La señal vive en robots.txt y se llama Content-Signal — un IETF draft que extiende el tradicional Allow/Disallow con tres ejes específicos de IA: ai-train, search, y ai-input. El scanner solo califica que la directiva exista y que la sintaxis sea válida; los valores son tu decisión.
Esta es la directiva que escogí:
User-agent: *
Allow: /
Disallow: /api/
Content-Signal: ai-train=yes, search=yes, ai-input=yesRazonamiento: los tres ejes son independientes. ai-train controla si tu contenido entra en los corpus de entrenamiento de futuros LLM base, search controla la indexación clásica en buscadores, y ai-input controla si tu contenido puede ser traído y citado en respuestas de IA en tiempo real (ChatGPT Search, Perplexity, Google AI Overviews, Claude Search). Para un blog técnico personal cuya moneda es ser leído, citado y referenciado, decir no en cualquiera de los tres es cambiar descubribilidad por protección que no necesito. yes en los tres ejes no es el default neutral — es la posición coherente para contenido cuyo trabajo es ser encontrado.
El contraargumento obvio: para publishers cuyo modelo de ingresos depende de gatillar contenido — medios, investigación bajo paywall, bases de datos por suscripción — ai-train=no y ai-input=no sí tienen sentido. El punto de que la directiva tenga tres ejes es justo ese: que distintos publishers puedan expresar políticas distintas sin que todo colapse en un único allow/disallow.
Nota técnica: el audit robots-txt de Lighthouse no reconoce Content-Signal todavía y la marca como directiva inválida, lo que rompe el SEO score. Para no perder ese punto sin sacrificar la directiva, agregué un middleware en functions/_middleware.ts que la quita solo cuando el escaneo viene de Lighthouse (UA con Chrome-Lighthouse o PageSpeed). El resto de los clientes — Googlebot, GPTBot, ClaudeBot, isitagentready, los demás crawlers — recibe el archivo completo. Cuando Lighthouse actualice su parser, el middleware se vuelve código muerto.
Cómo se ve el 100
Aquí está el snapshot final.
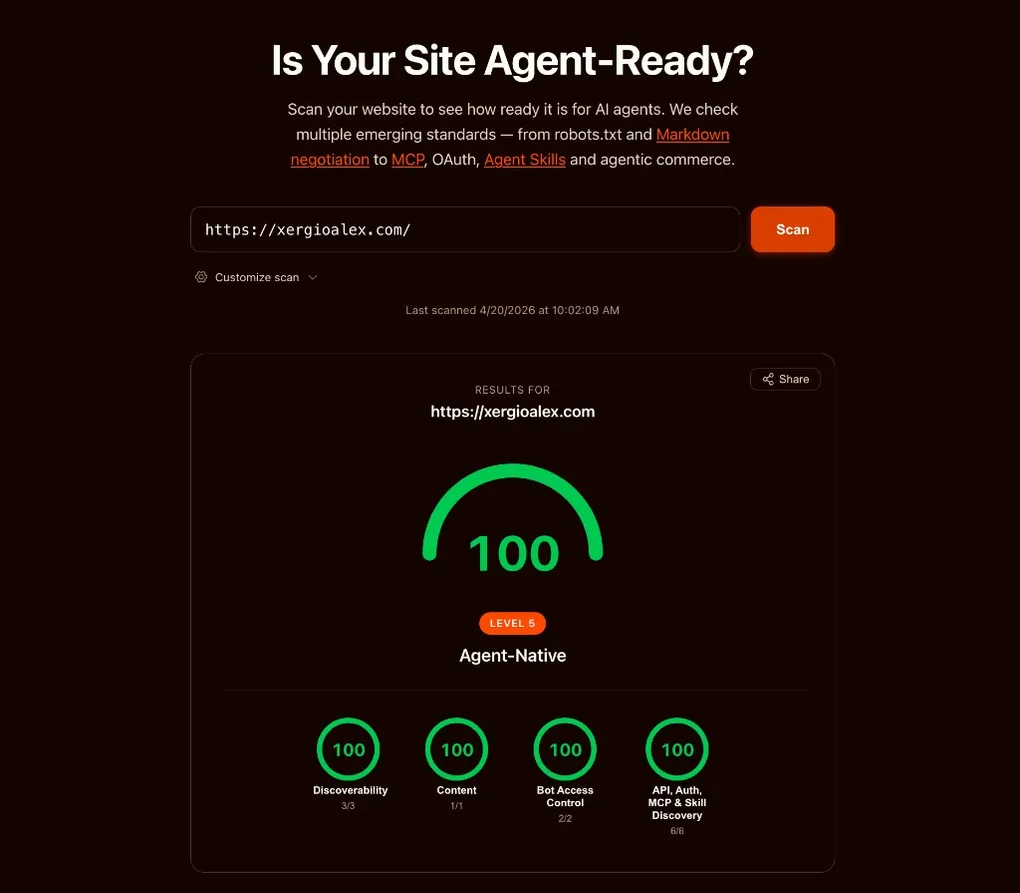
Apila los ocho artefactos, los dos caminos del middleware, y el bridge WebMCP. Cualquier agente de IA que le pegue a xergioalex.com ve, en orden:
- Una respuesta HTML con un header
Link: </.well-known/api-catalog>; rel="api-catalog". - Un cuerpo HTML cuyo gemelo en markdown está a un
Accept: text/markdown(o a una URL.md) de distancia. - Un
robots.txtdeclarandoContent-Signal: ai-train=yes, search=yes, ai-input=yes(con un middleware que oculta esa línea para Lighthouse hasta que actualice su parser). - Un API catalog apuntando a un spec OpenAPI 3.1 real y a docs legibles por humanos.
- Un documento de metadata OAuth authorization-server — honesto, anotado, estructuralmente compatible.
- Un documento OAuth protected-resource — una autoreferencia válida.
- Un MCP server card declarando que el sitio soporta
toolsyresources. - Un índice agent-skills con ocho entradas y digests SHA-256, regenerado en cada build contra los bytes vivos de Cloudflare.
- Una página de navegador que llama
navigator.modelContext.provideContext({ tools })al cargar con tres tools de solo lectura — o que cae aregisterTooluno por uno si la API moderna no está disponible.
Eso es una superficie de protocolo real. Nada de esto era posible hace unas semanas — ninguno de los drafts de arriba existía como spec enviado todavía. Todo se armó encima de una preocupación sobre la que venía escribiendo hace meses: que la medición del AEO iba años atrás de la optimización del AEO. Hoy, ya no.
La quinta categoría: commerce agent-native
Envié los ocho artefactos, vi el scorecard llegar a 100, y seguí. Unos días después, a isitagentready.com le creció una quinta categoría: Commerce. Cuatro chequeos nuevos, cuatro SKILL.md nuevos, una pregunta nueva — ¿un agente de IA puede pagarle a tu sitio?
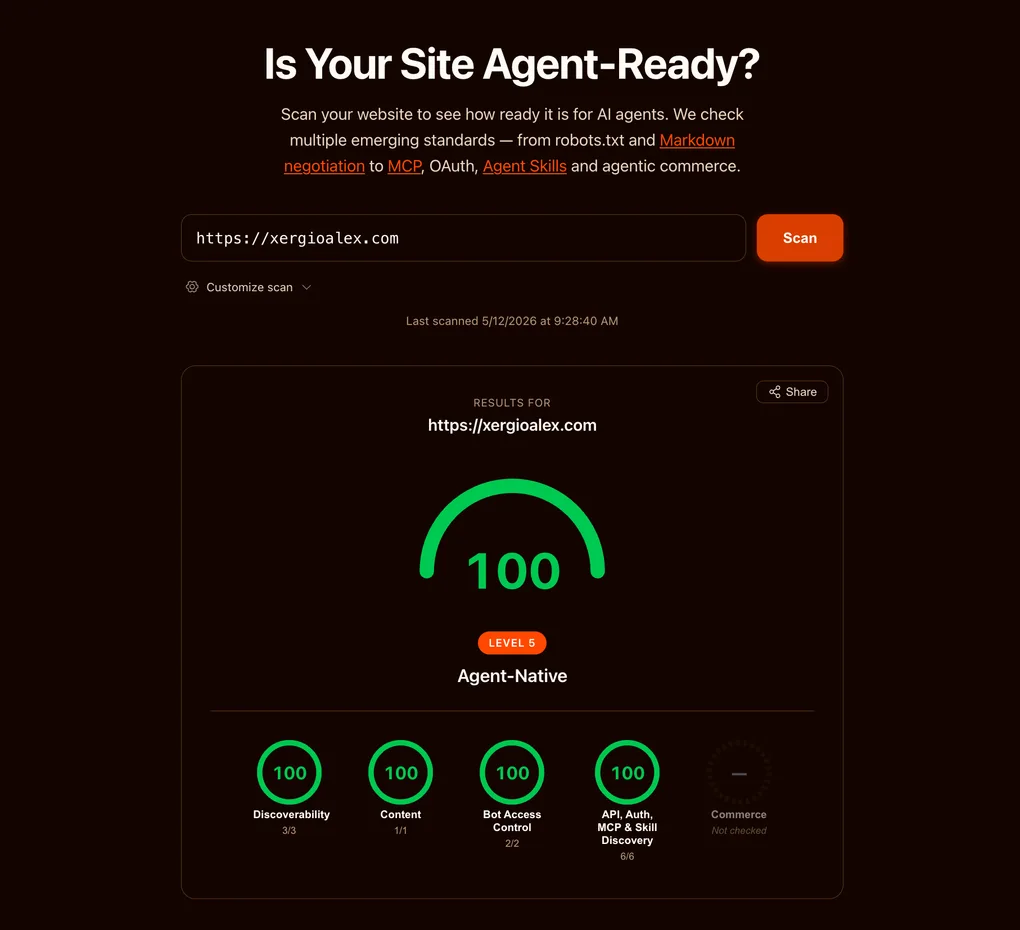
Mi score no se movió. Sigue diciendo 100. La categoría nueva se sienta al final de la fila, en gris, con la etiqueta “not checked” — y cada uno de sus cuatro sub-chequeos da el mismo diagnóstico: not a commerce site. Eso no es una deducción. El scorecard trata Commerce como condicional: solo la califica si eres un comercio, y un sitio de contenido no lo es. Así que, en sentido estricto, acá no hay nada que hacer.
Pero “nada que hacer” y “nada que pudiera hacer” no son lo mismo. Podría enviar los cuatro artefactos de todos modos y poner ese círculo gris en verde. Veamos qué es cada uno — y por qué lo dejo sin validar para este sitio.
Los cuatro chequeos de commerce
1. x402 — HTTP 402, por fin usado para algo. x402 es el revival de Coinbase del código de estado 402 Payment Required, dormido hace años. Le agregas un middleware de pago (@x402/express, @x402/hono, o @x402/next) a tus rutas, configuras una facilitator URL y una wallet address, y las rutas protegidas empiezan a responder con HTTP 402 más los requisitos de pago legibles por máquina. Un agente lee el 402, paga vía el facilitator, reintenta, obtiene el recurso — sin humano en el medio. El scanner pasa cuando checks.commerce.x402.status es pass. Cómo funciona este protocolo, y por qué importa, lo explico en detalle en La Economía de los Agentes — x402 es una de sus piezas centrales.
2. MPP — pistas de pago dentro de tu doc OpenAPI. Machine Payment Protocol reusa un artefacto que ya envío: /openapi.json. Le pegas una extensión x-payment-info a cada operación pagable, declarando intent (charge o session), method (tempo, stripe, lightning, o card), y amount. Forma mínima:
"x-payment-info": { "intent": "charge", "method": "stripe", "amount": 2999 }Hay un SDK — mppx para TypeScript, pympp para Python — y middleware para Hono, Express, Next.js, y Elysia. El scanner pasa cuando /openapi.json responde 200 y al menos una operación carga un x-payment-info válido.
3. UCP — un perfil de commerce en /.well-known/ucp. Universal Commerce Protocol quiere un documento JSON en /.well-known/ucp con cuatro claves obligatorias — protocol_version, services, capabilities, endpoints — y cualquier URL de spec o schema que referencie tiene que resolver de verdad. El scanner pasa cuando checks.commerce.ucp.status es pass.
4. ACP — metadata de discovery en /.well-known/acp.json. Agentic Commerce Protocol quiere un documento de discovery en la raíz del origen: protocol.name igual a "acp", un protocol.version, un api_base_url absoluto, un array transports no vacío, y un array capabilities.services no vacío. Forma mínima:
{
"protocol": { "name": "acp", "version": "1.0" },
"api_base_url": "https://api.example.com",
"transports": ["http"],
"capabilities": { "services": ["payment"] }
}Por los estándares de este post, eso es una tarde: dos archivos JSON estáticos bajo .well-known/, un bloque de extensión en un archivo que ya sirvo, un middleware. El costo no es el trabajo — es lo que cada documento afirma.
Esos cuatro documentos tienen algo en común: la existencia de cada uno es una declaración de que el sitio es un comercio — solo tienen sentido si efectivamente vendes algo. Servir /.well-known/acp.json es anunciar “soy un comercio agentic-commerce; acá está mi API base URL”; levantar x402 es apuntar a una wallet real lista para cobrar. Y no hay _comment que rescate eso: “documento de comercio ACP, pero el sitio no es un comercio” no es una salvedad honesta — es una contradicción en la misma frase. Todo este post tiene una lección recurrente, la honestidad le gana al teatro, y la categoría Commerce es donde deja de ser un aparte y se vuelve la decisión entera: la respuesta honesta acá no es 100 — es no aplica.
Y eso es lo que hace distinta a esta quinta categoría: el scorecard la trata como condicional, no obligatoria. Not checked no es failed — es la herramienta reconociendo que “no tener” y “no aplicar” son cosas distintas. Pocos sistemas de medición hacen esa distinción; la mayoría leen cada casilla vacía como una deuda pendiente. Este la hace, y eso habla bien de él. El día que xergioalex.com venda algo — un curso pago, un tier de API con medición, acceso patrocinado a una herramienta — esos cuatro artefactos pasan de teatro a verdad y enviaré los que apliquen. Hasta entonces, el estado listo-para-agentes de un sitio de contenido es exactamente lo que muestra la captura: cuatro categorías al máximo, una dejada en blanco a propósito — y eso es la respuesta completa, no una parcial.
El lector número uno de la web
Todo este capítulo — los ocho artefactos, el scorecard en 100 — es un sitio poniéndose al día con un cambio que ya ocurrió: el lector número uno de la web ya casi no es una persona con un navegador. Es un agente. No hojea diez resultados ni hace clic en un enlace azul — pregunta, lee lo que encuentre, arma una respuesta y se la entrega a alguien que nunca va a ver tu página. Los capítulos anteriores de esta serie tienen los números detrás de eso: el tráfico de búsqueda erosionándose, sitios que perdieron casi todo lo orgánico. Ese cambio ya está aquí; el scorecard solo lo puso en un número.
Y la buena noticia es que ponerse al día es barato. Las bases para que un agente te lea bien son un puñado de archivos de texto y dos líneas de configuración — una tarde de trabajo. Si quieres empezar en tu propio sitio, los SKILL.md en isitagentready.com/.well-known/agent-skills/ son el mejor punto de partida, y la guía de campo de .well-known/ abre cada documento uno por uno: qué es, por qué existe, cómo se ve el mínimo válido.
No te obsesiones con el número en sí. isitagentready.com es la vara de medir de un solo equipo, y las definiciones se mueven: a esta le creció una categoría a mitad de la serie, Lighthouse reescribirá su parser en algún momento, mañana sale otra herramienta con otra rúbrica. El 100 de hoy puede ser un 80 en un año sin que yo toque una línea. Lo que perdura no es el score — son los archivos debajo, atados a estándares abiertos y no a la herramienta que los califica. Aunque todo scorecard desaparezca mañana, siguen ahí haciendo su trabajo para cualquier agente que respete los estándares.
Lo caro es la otra opción: quedarte ilegible mientras el terreno se mueve. No se siente como una caída — se siente como un sitio que, despacio, deja de aparecer en las respuestas, sin que nadie te avise. La era de los agentes no va a esperar a que estés listo. Yo prefiero estar del lado de los que ya hablan su idioma.
Sigo construyendo.
Recursos
- Introducing the Agent Readiness score
- isitagentready.com
- RFC 8288 — Link headers
- RFC 9727 — API Catalog
- RFC 9728 — OAuth Protected Resource Metadata
- RFC 8414 — OAuth Authorization Server Metadata
- RFC 9309 — Robots Exclusion Protocol
- Content Signals draft (IETF)
- contentsignals.org
- Cloudflare Agent Skills Discovery RFC
- MCP Server Card — SEP-1649 / PR #2127
- WebMCP
- Cloudflare Pages
_headersdocs - x402 — pagos HTTP agent-native
- x402 en GitHub (Coinbase)
- MPP — Machine Payment Protocol
- UCP — Universal Commerce Protocol
- ACP — Agentic Commerce Protocol

Sergio Alexander Florez Galeano
CTO y Cofundador en DailyBot
Ingeniero de software y emprendedor colombiano (DailyBot, YC S21). Escribo sobre agentes de IA, herramientas para desarrolladores, startups y el arte de la ingeniería de software, y construyo este sitio a la vista de todos en XergioAleX.com.
Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.