
The hardest part of AEO is measurement. Google Analytics can’t see AI bots. They don’t execute JavaScript. From a client-side analytics perspective, every AI crawler visit is completely invisible — a black hole where your best content goes and you have no idea what happens next.
I spent a fair amount of time trying to figure out what “working” even looks like for AEO. With traditional SEO you have rankings, CTR, impressions. With AEO you have… vibes. Someone tells you they found you on ChatGPT. You search your own name in Perplexity and sometimes you’re there, sometimes you’re not. The measurement ecosystem is years behind the optimization ecosystem, and that gap is frustrating for everyone — not just me.
This chapter is about closing that gap as much as currently possible, and honest about how much remains unsolved.
Tracking AI Bot Traffic
The only place to catch AI crawlers is server-side, before the response goes out. Client-side analytics never sees them — they don’t execute JavaScript, so tools like Google Analytics have no idea they exist.
The approach I built for this site is a Cloudflare Pages middleware that runs at the edge on every request. It checks the User-Agent header against a list of known AI bot patterns — GPTBot, ChatGPT-User, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, OAI-SearchBot, Amazonbot, Meta-ExternalAgent, Bytespider, and a few others. When there’s a match, it fires an ai_bot_visit event to Umami (my analytics platform) with the bot name, page path, and HTTP method. Human visitors pass through with zero overhead — it’s just a dozen regex tests that take microseconds.
The key design decision is using context.waitUntil() to defer the analytics call. The bot gets its response immediately; the event fires in the background. Analytics failures never block page delivery — an empty catch ensures that a Umami outage doesn’t break the site.
But not every crawler announces itself clearly. A second layer catches unrecognized bots — anything with “crawler”, “spider”, “scraper”, or “agent” in the User-Agent that isn’t a known search engine like Googlebot or Bingbot. These fire an unknown_bot_visit event that includes the full User-Agent string, so I can inspect the dashboard later and decide if any of them deserve to be promoted to the known list.
I wrote about the full implementation story in Tracking the Invisible: How I Built AI Bot Analytics. Here’s what the data looks like from the last 24 hours:
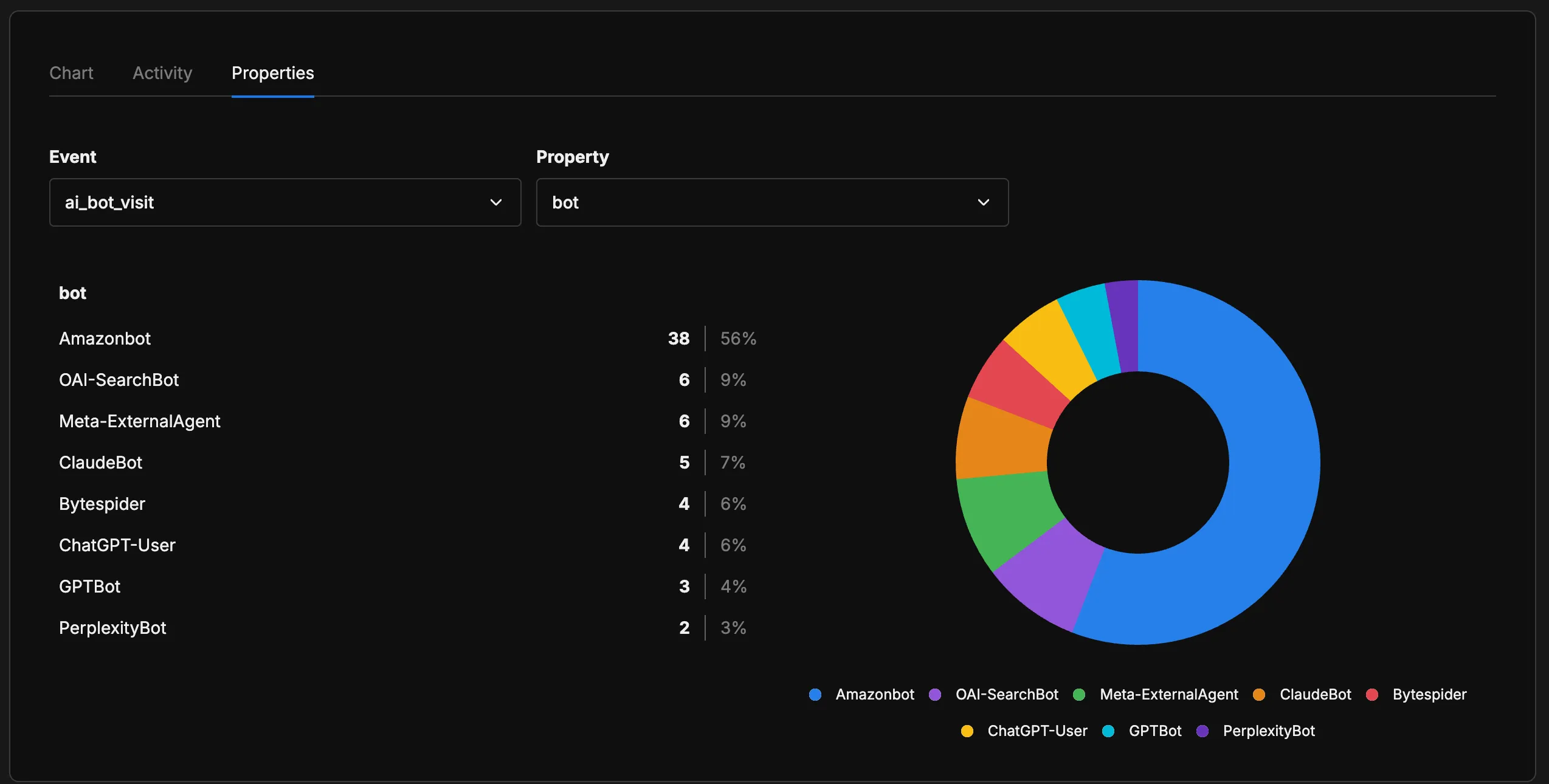
The distribution surprised me. Amazonbot dominates at 56% of all AI bot visits — not what I expected when I first set this up. OpenAI’s bots (OAI-SearchBot + ChatGPT-User + GPTBot) collectively account for about 19%, Meta-ExternalAgent sits at 9%, and ClaudeBot at 7%. PerplexityBot is the smallest at 3%, which is interesting given how much Perplexity has grown as a product.
The unknown bot dashboard tells a different story:
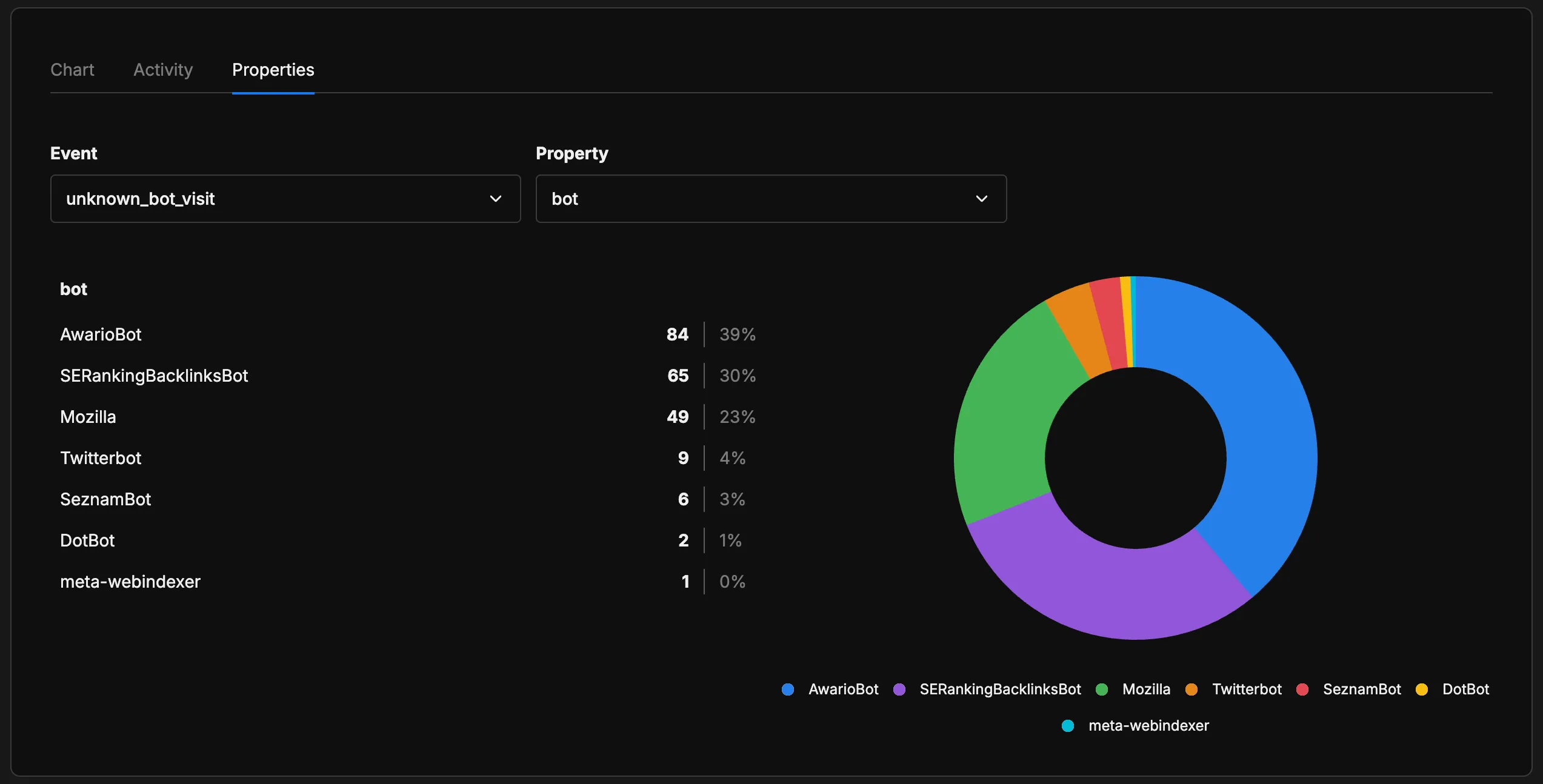
Most of these are SEO tools (AwarioBot, SERankingBacklinksBot) or social media crawlers (Twitterbot), not AI systems. The 23% labeled “Mozilla” makes more sense when you look at the full User-Agent strings:
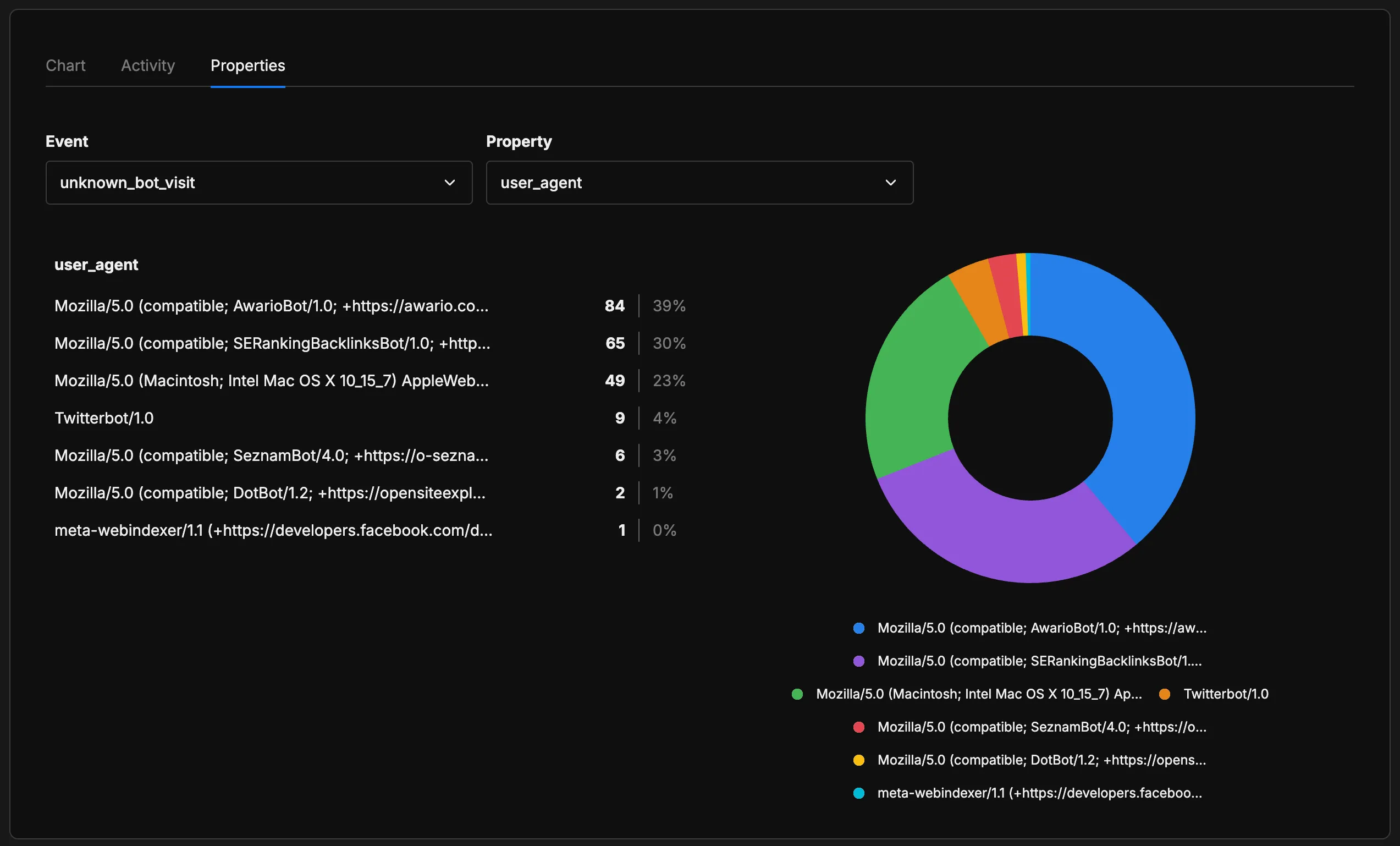
Those “Mozilla” entries are using Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit... — a full desktop Safari User-Agent string. Automated scrapers disguising themselves as real browsers. Exactly the kind of bot that’s impossible to classify without deeper analysis. This layer is useful as a discovery mechanism: when a new AI crawler appears, I’ll see it here first.
What you get from all of this is imperfect but real: which bots are crawling, which pages they visit, how often. That’s the baseline. Everything else in AEO measurement is built on top of this signal — or is missing it entirely.
Tracking Markdown Requests
The same middleware tracks a second signal: when agents request Markdown content — via Accept: text/markdown headers or direct .md URLs. In my implementation, every Markdown request fires a markdown_request event to Umami with:
| Field | Description |
|---|---|
bot |
Known bot name (GPTBot, ClaudeBot, etc.) or "unknown" |
path |
The requested path |
source |
content_negotiation or direct_url |
user_agent |
First 200 characters of the User-Agent string |
The source field is the most interesting one. If agents start sending Accept: text/markdown headers — the “proper” way to request Markdown for Agents — it shows up as content_negotiation. If they’re just hitting .md URLs they found somewhere, it appears as direct_url. The ratio tells you something about how aware agents are of the convention.
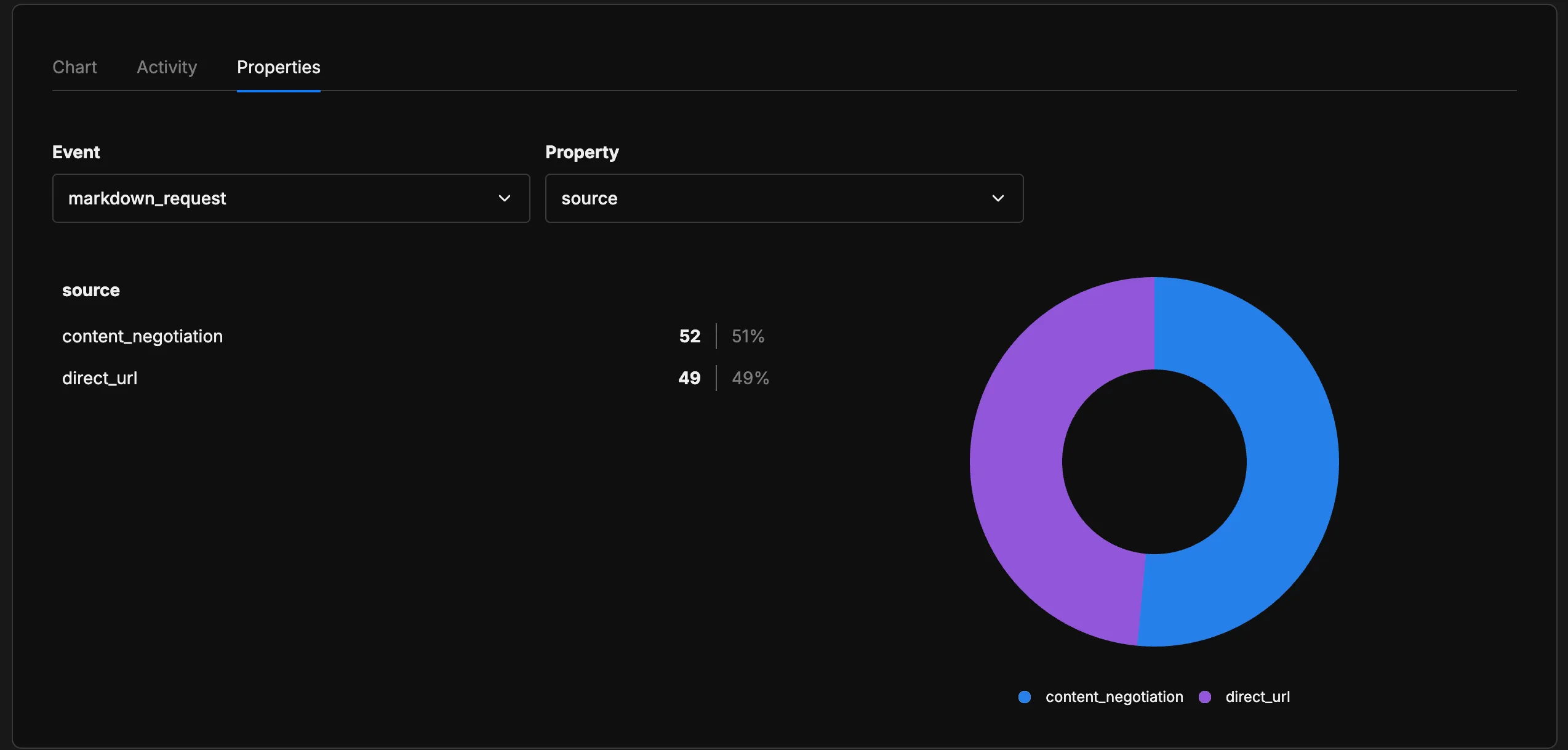
The data is just starting to come in — I implemented this recently and it’s still too early to draw conclusions. But going forward, this signal will let me understand whether the standard is actually gaining adoption and how much AI bots are requesting Markdown content on my site.
The Measurement Landscape
This is the state of the industry: one useful native tool, a few third-party options, and a lot of manual guesswork.
Bing’s AI Performance report is the most concrete thing available. You get total citations, which pages get referenced, and the “grounding queries” — the phrases the AI used when it retrieved your content. It covers Microsoft Copilot and Bing AI summaries specifically. Not a global picture, but actual data from an actual platform, which makes it more useful than most alternatives right now.
Google hasn’t shipped anything comparable for AI Overviews. Google Search Console now includes AI Mode data, but it all gets lumped into the regular “Web” search type — there’s no separate filter to see how much traffic comes from AI-generated surfaces versus traditional organic listings. Whether that’s intentional opacity or it’s just not ready, I couldn’t say — but it’s a significant gap given that Google generates the most AI Overviews. The platform with the biggest footprint gives you the least visibility.
For everything else, I found a couple of options during my research that I haven’t personally tested but look promising: Otterly.ai for cross-platform citation monitoring and HubSpot’s free AEO Grader for a scored audit against AEO best practices. Beyond those, there’s manual testing — running your target queries through ChatGPT and Perplexity and checking if you appear.
Manual testing is more useful than it sounds, but with a major caveat. According to AirOps research, only 30% of brands stay visible from one AI answer to the next, and only 20% across five consecutive runs. A snapshot check on Tuesday means nothing by Thursday.
This is the weakest part of the AEO ecosystem right now. We can optimize content. We can track crawlers. But measuring “how often does AI cite me?” with any statistical confidence is still basically unsolved. Server-side bot tracking is the best proxy available — you can at least confirm bots are coming and which pages they care about. What you can’t confirm is whether those crawl visits are turning into citations.
The Audit
There are no standardized AEO audit tools the way SEMrush or Lighthouse handle SEO and performance. You’re building the checklist yourself, or borrowing one. Since I couldn’t find anything that covered everything I cared about, I built my own framework around four dimensions — basically the four questions I kept asking myself about every page on this site:
| Dimension | What It Measures |
|---|---|
| Discoverability | Can AI crawlers find and access the content? (robots.txt, llms.txt, crawl permissions) |
| Extractability | Can AI systems parse structured meaning? (schema markup, semantic HTML, heading hierarchy) |
| Trust | Does the content carry credibility signals? (author attribution, timestamps, cited sources) |
| Citability | Is the content structured to be quotable? (clear answers, direct language, factual density) |
Each dimension has its own checklist. The score itself matters less than what the audit reveals in the process — every gap I found became a task, and the work documented across this series is the result of going through that checklist systematically.
Two things surprised me when I went through this systematically.
Freshness isn’t just about content — it’s about signals. I mentioned in the first chapter that AI systems favor fresh content — and the data backs it up: AI-cited content is 25.7% fresher than traditional Google results, and in ChatGPT specifically, 76.4% of the most-cited pages were updated in the last 30 days. What I realized working on this site is that it’s not enough to update the text — you need visible proof. Adding “last updated” timestamps to every post, keeping dateModified current in the BlogPosting schema, and making sure the llms.txt reflects recent changes. The content can be identical, but if the freshness signals are stale, AI systems treat it as stale.
Localization quality matters more than coverage. Running this site in two languages already gives it a visibility advantage — AI systems treat each language version independently. But machine-translated pages with awkward phrasing or missing cultural context score lower on citability. The pages that perform best are the ones that read like they were written natively, not translated. That’s exactly why this site only exists in English and Spanish — the two languages I actually speak and can personally audit. I could scale to more languages with AI translation, but I wouldn’t be able to read every sentence and reshape it until it sounds right. I go through every phrase, rewrite what feels off, and build the final version myself. It’s a process that takes time, but if you want to deliver quality content with a real author’s voice, it’s important.
Where This Is Heading
I’ll be honest: we’re still figuring this out. All of us. The IETF AIPREF working group is drafting specs for how websites express preferences about AI content use — training, output, search, each as separate categories. Until that lands, we’re relying on robots.txt, a file that predates large language models by fifteen years. It works, but it was never designed for this.
What I do know is that the numbers are real. A 13-month analysis by Search Engine Land (February 2026) found AI search traffic converting at roughly 18% — the highest-converting source in their dataset. Vercel reported ChatGPT referrals hitting 10% of new signups. Tally.so saw ChatGPT become their number one referral source, period. And on the other side of the equation, major tech publications are losing up to 97% of their organic traffic as AI Overviews eat into the queries they used to own.
How much of this site’s traffic comes from AI citations? I honestly don’t know. That’s the measurement gap I’ve been talking about this whole chapter. The bots are visiting — I can see that in the dashboard. Which pages they care about — that’s visible too. Whether those visits turn into citations that send people here — still a black box.
But the infrastructure to serve them well exists today. And the ground under search is moving whether we’re ready or not.
Let’s keep building.
Resources
Measurement Tools
- Bing AI Performance in Webmaster Tools — Citation tracking in Microsoft Copilot and Bing AI
- Otterly.ai — AI citation monitoring across platforms
- HubSpot AEO Grader — Free AEO audit scoring tool
Research & Data
- AirOps: AI Citation Volatility — 30% of brands stay visible across consecutive AI answers
- Search Engine Land: 13 Months of LLM Traffic Data — AI search traffic converts at ~18%, the highest-converting source
- HubSpot: AEO Adoption Trends — AEO strategy and implementation insights
- Vercel Case Study — ChatGPT grows to 10% of new signups
Standards
- IETF AIPREF Working Group — Formal AI content permission specifications in progress
- Cloudflare: Markdown for Agents — Content negotiation at the edge

Sergio Alexander Florez Galeano
CTO & Co-founder at DailyBot
Colombian software engineer and entrepreneur (DailyBot, YC S21). I write about AI agents, developer tools, startups, and the craft of software engineering — and I build this site in the open at XergioAleX.com.
Stay in the loop
Get notified when I publish something new. No spam, unsubscribe anytime.
No spam. Unsubscribe anytime.