
Como parte de un ejercicio típico de algoritmia en la universidad, hice un pequeño análisis comparativo de los algoritmos de ordenamiento más populares, buscando estudiar la complejidad de cada uno y cómo las diferentes formas de resolver un mismo problema pueden afectar los tiempos de ejecución.
Quiero aclarar que este es solo un análisis académico muy simple que quise documentar, y que tal vez sirva a futuro para otros estudiantes de ciencias de la computación.
Comencé desarrollando un pequeño script en Java que genera números aleatorios de cinco dígitos y los almacena en un archivo de texto, para poder analizar el mismo conjunto de datos entre diferentes algoritmos. El script lo puedes encontrar en este repositorio y ejecutar de la siguiente forma:
# Ruta del archivo
> algorithms/java/RandomNumbers.java
# Ejecutar script en Java
$ javac RandomNumbers.java && java RandomNumbersLo anterior genera el archivo numbers/numbers.txt con n números aleatorios definidos dentro del script. En mis experimentos llegué a generar un archivo de 1.000.000.000 de datos (cerca de 5 GB), por eso no lo adjunté en el repositorio.
Algoritmos evaluados
En un paso siguiente procedí a implementar algoritmos de ordenamiento populares:
- Burbuja (Bubble Sort):
O(n^2) - Conteo (Counting Sort):
O(n+k) - Montones (Heapsort):
O(n log n) - Inserción (Insertion Sort):
O(n^2) - Mezcla (Merge Sort):
O(n log n) - Rápido (Quicksort):
O(n log n) - Selección (Selection Sort):
O(n^2)
Para esta tarea seleccioné C y los scripts se encuentran en algorithms/c/sortAlgorithms.
Automatización de pruebas
Dado que para hacer un buen análisis se deben correr muchas pruebas, creé un par de scripts para automatizarlas:
# Script base para ejecutar cualquier algoritmo y generar logs de tiempos
> algorithms/c/benchmark.c
# Correr prueba
# arg1, arg2 => nombre del algoritmo y cantidad de elementos
$ gcc benchmark.c -o benchmark.out && ./benchmark.out arg1 arg2
# Script para correr múltiples pruebas
> algorithms/c/runTest.c
# Correr pruebas
$ gcc runTest.c -o runTest.out && ./runTest.outCon esto ya estaba todo listo. Solo faltaba dejar corriendo runTest.c en una máquina. Aunque era un ejercicio académico sin gran rigor científico, procuré usar un pequeño ambiente controlado para evitar ruido por otros procesos.
Para eso creé dos droplets en Digital Ocean:

El segundo servidor tenía el doble de recursos, así que en teoría debía rendir mejor.
También configuré Java y C en ambos servidores con este script de aprovisionamiento: ServerConfig/provision.sh
# Base installation
sudo apt-get update -y
sudo apt-get upgrade -y
sudo apt-get install -y build-essential gcc python-dev python-pip python-setuptools
# Git
sudo apt-get install -y git
# Install Java
sudo apt-get install default-jre -y
sudo apt-get install default-jdk -y
sudo apt-get install openjdk-7-jre -y
sudo apt-get install openjdk-7-jdk -yResultados
En cada máquina se corrieron pruebas con el mismo archivo de números aleatorios, aumentando el tamaño en diferentes intervalos (10, 100, 1.000, 10.000, etc.). Los resultados detallados están en results/analysis.ods.
Como pausa útil, este fue el truco para dejar el proceso en background sin depender de la sesión:
$ gcc runTest.c -o runTest.out && ./runTest.out
# Ctrl + z
disown -h %1
bg 1Después de varios días, los experimentos apenas iban por 1.600.000 de datos en los algoritmos O(n^2), así que detuve la ejecución en ambos servidores y empecé el análisis.
M1 = Máquina 1 (1 núcleo, 1GB RAM)
M2 = Máquina 2 (2 núcleos, 2GB RAM)
Burbuja (Bubble Sort): O(n^2)
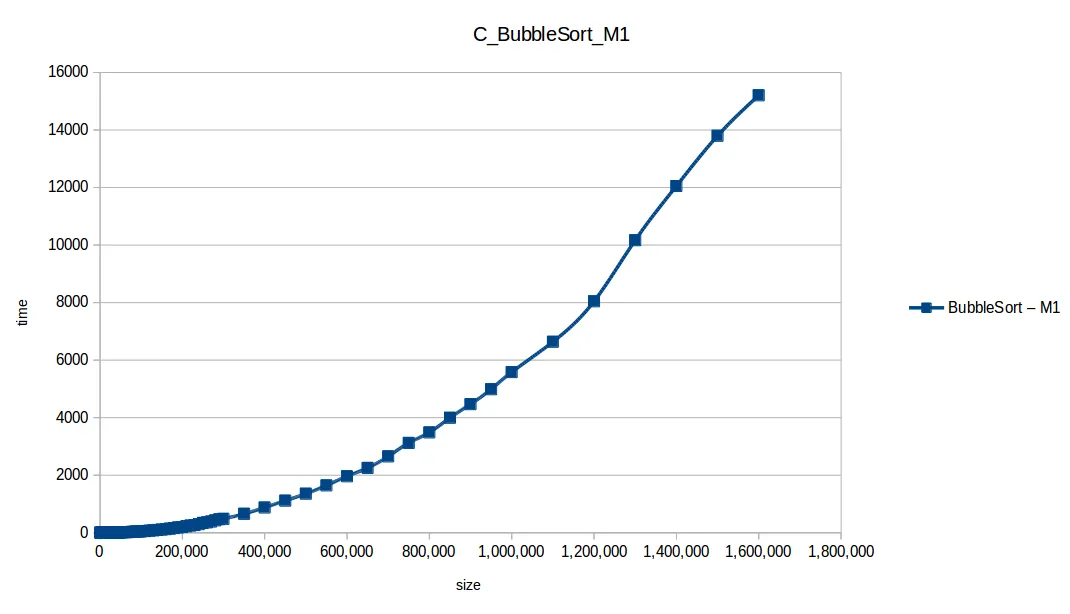
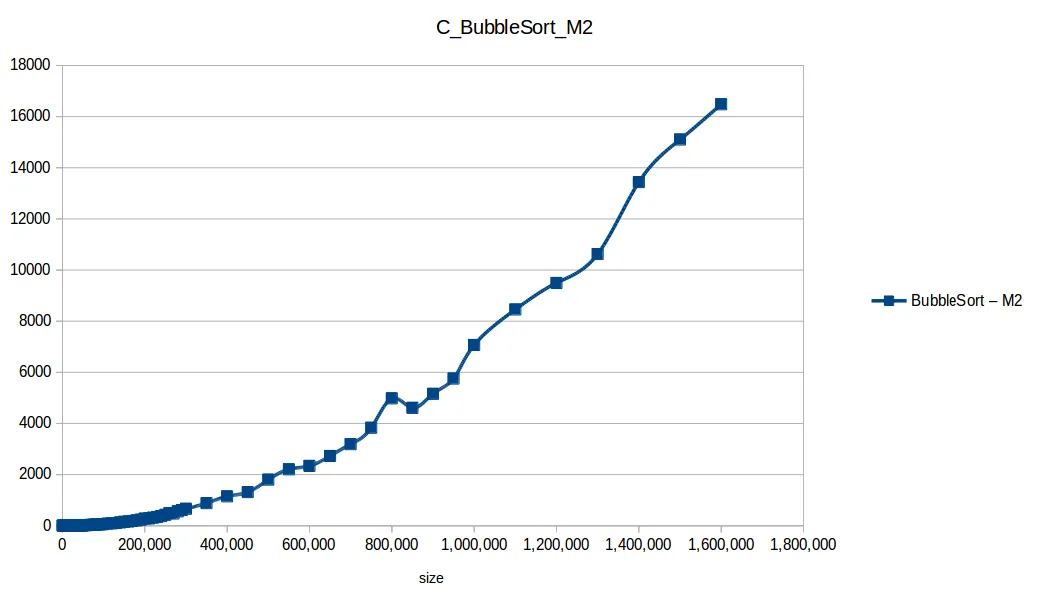
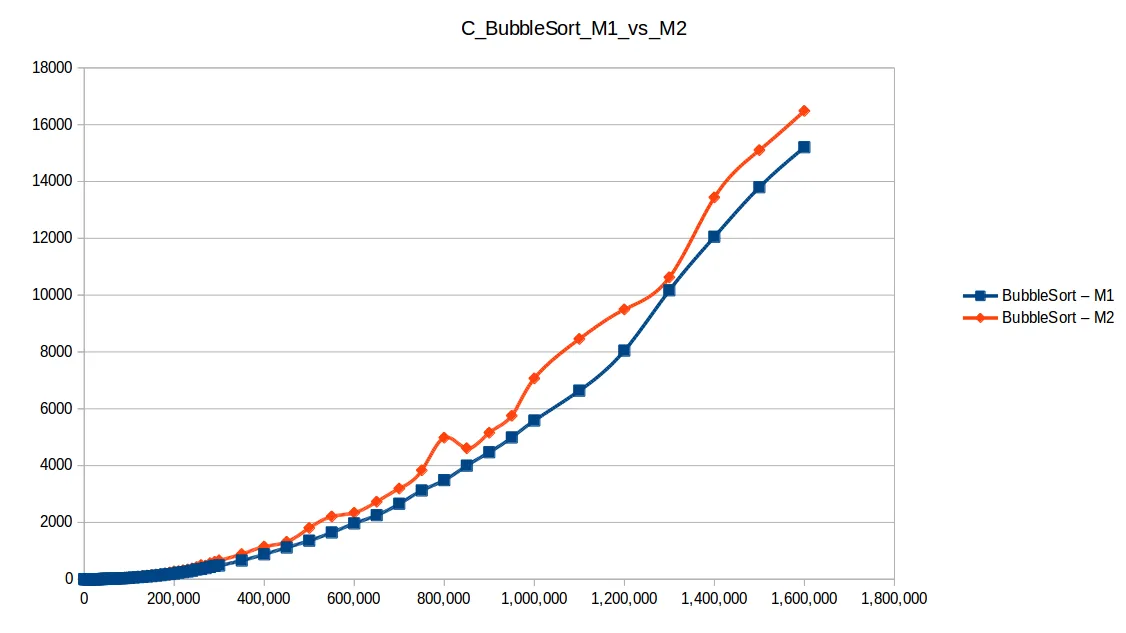
Conteo (Counting Sort): O(n+k)
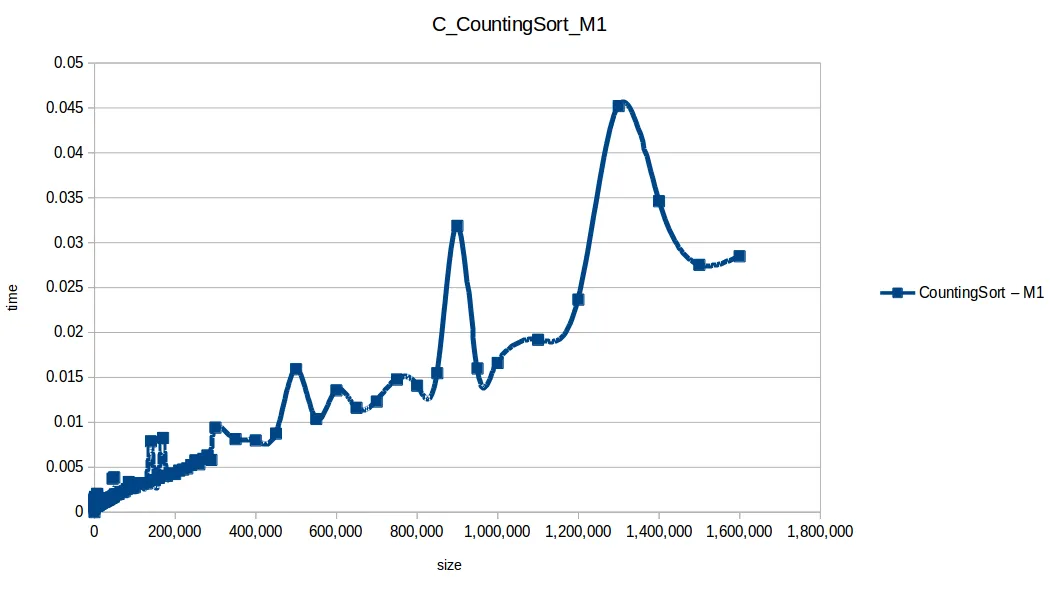
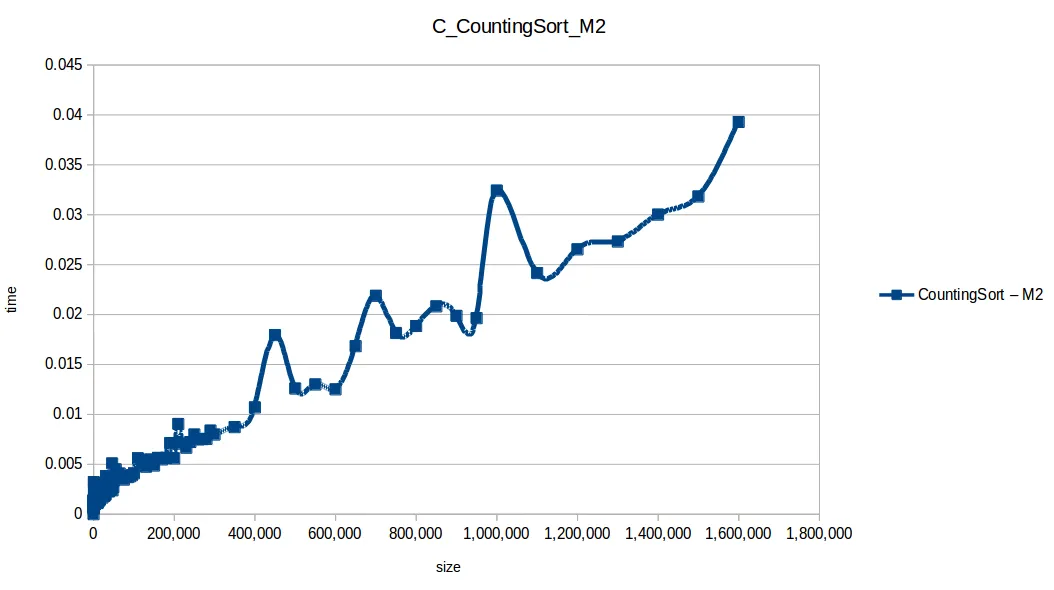
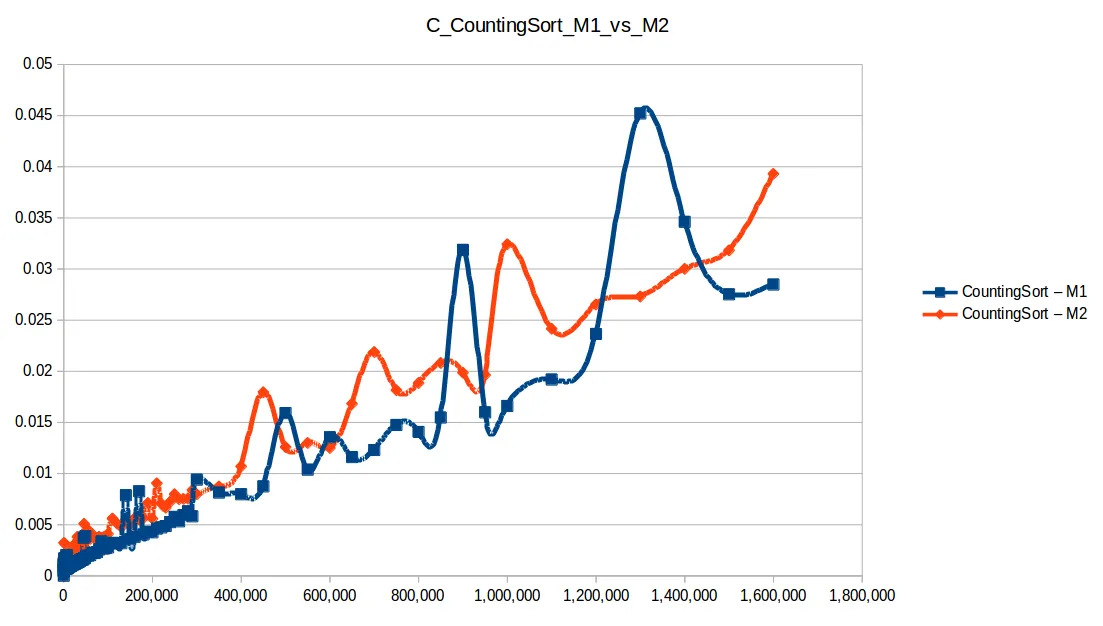
Montones (Heapsort): O(n log n)
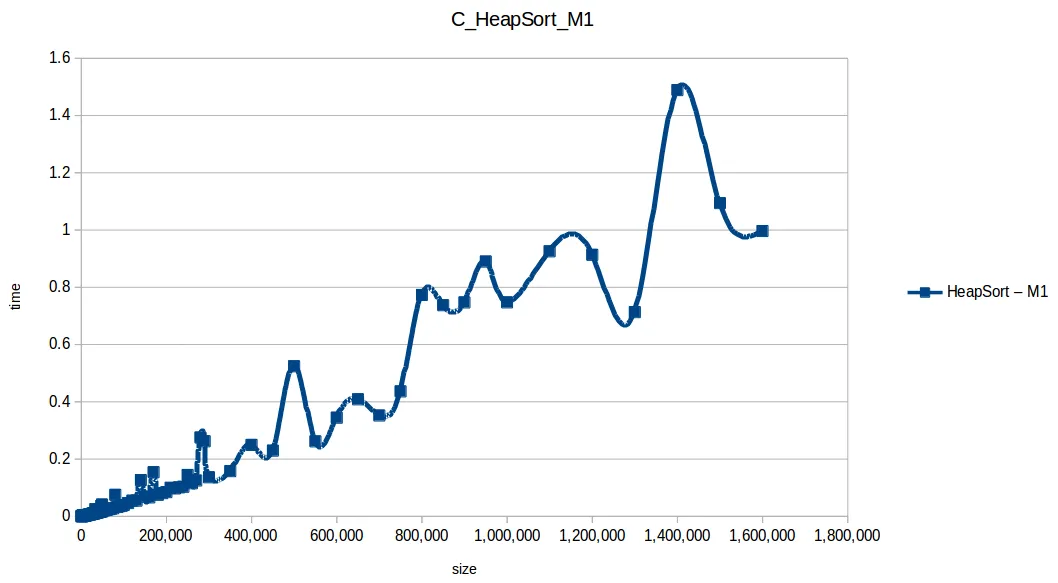
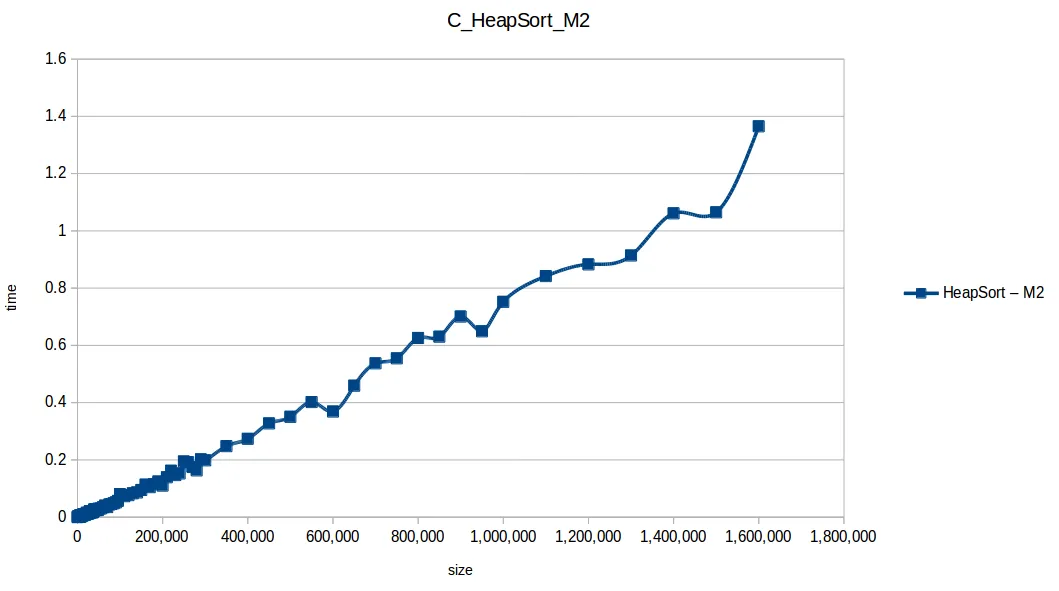
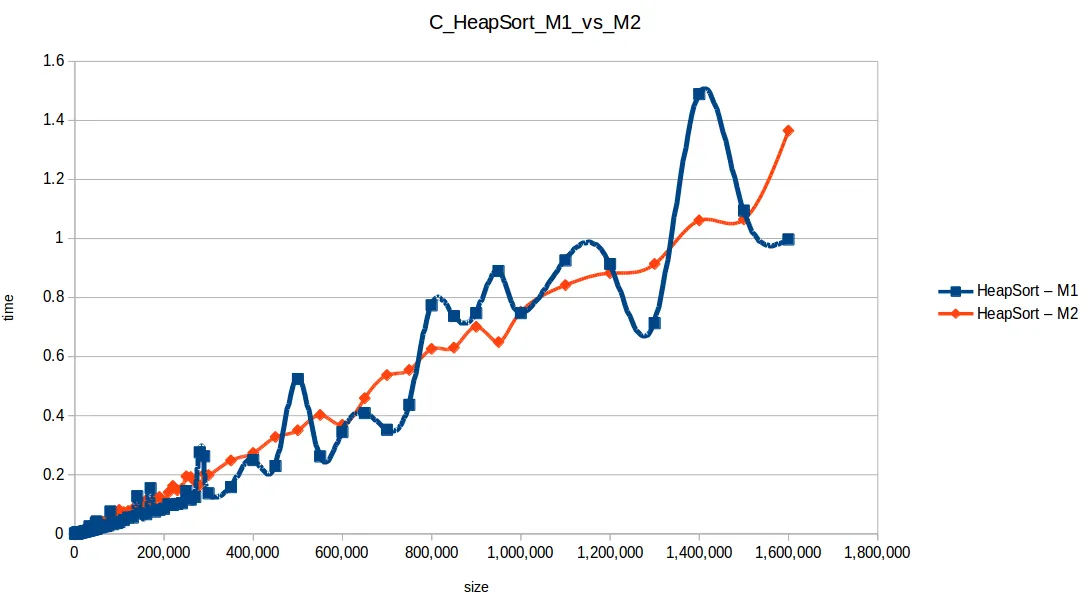
Inserción (Insertion Sort): O(n^2)
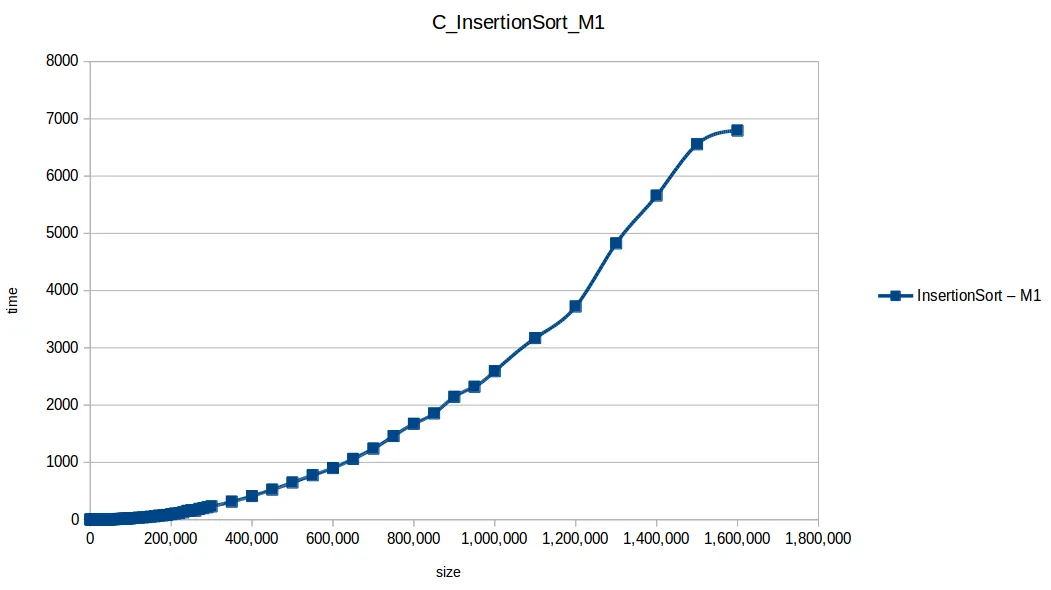
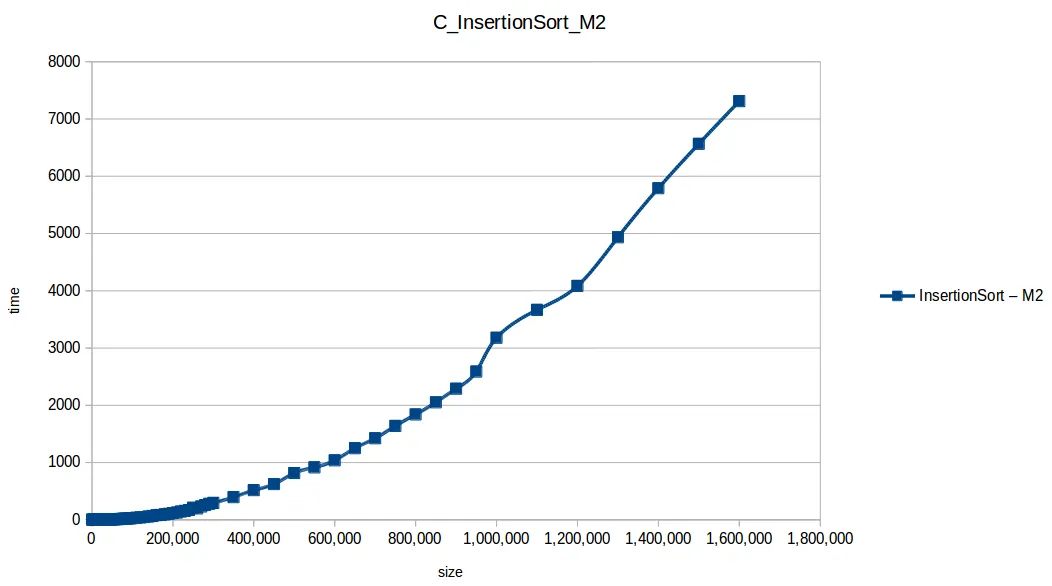
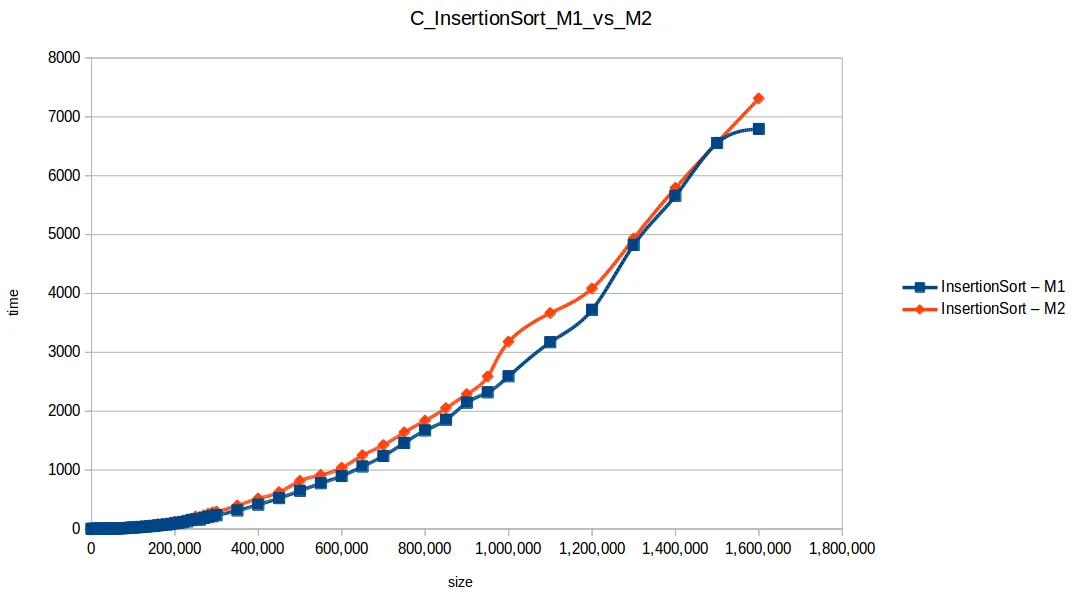
Mezcla (Merge Sort): O(n log n)
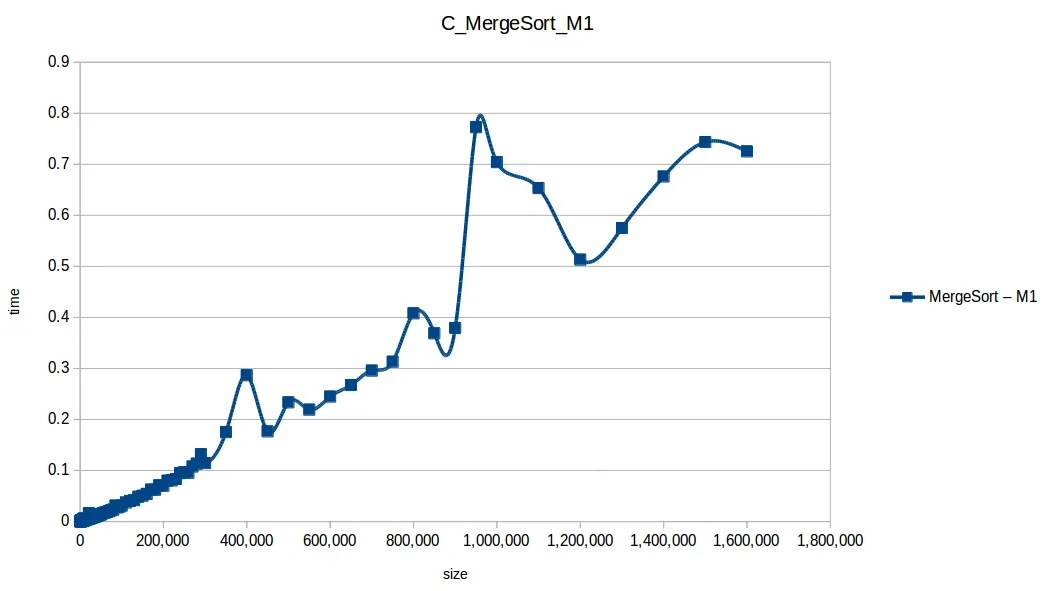
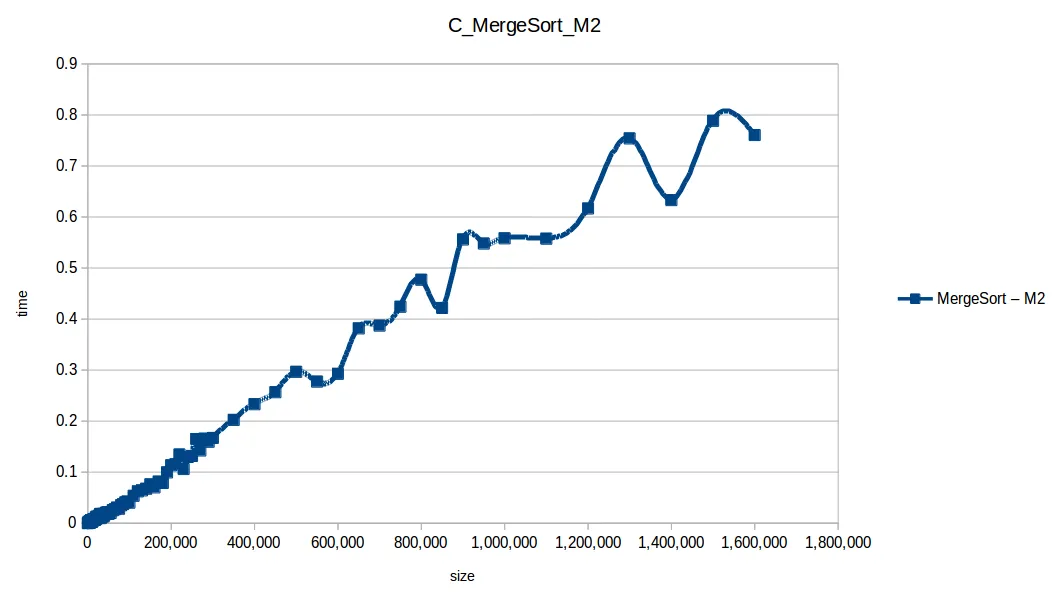
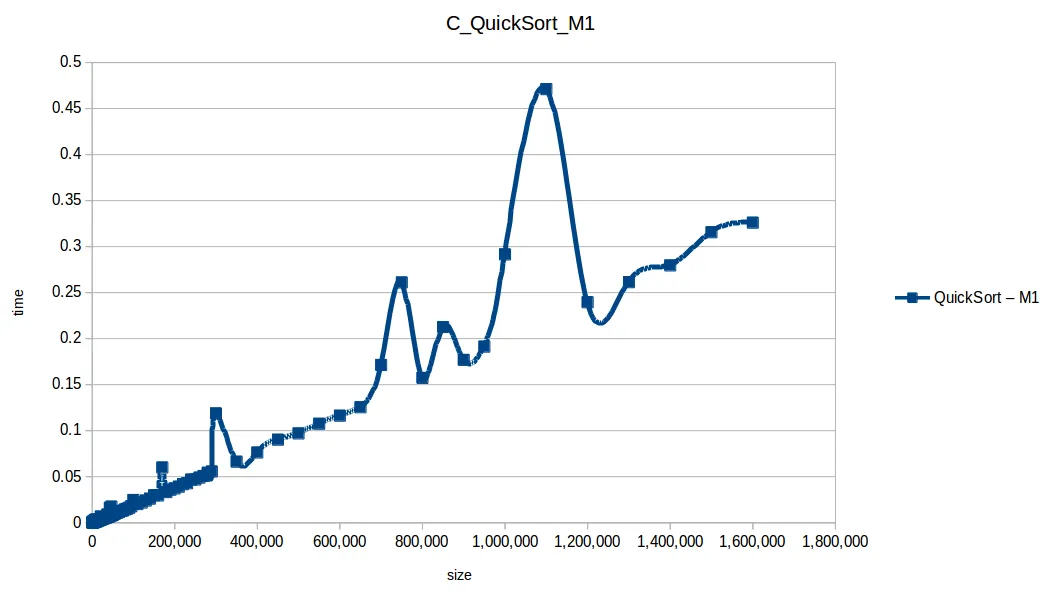
Rápido (Quicksort): O(n log n)
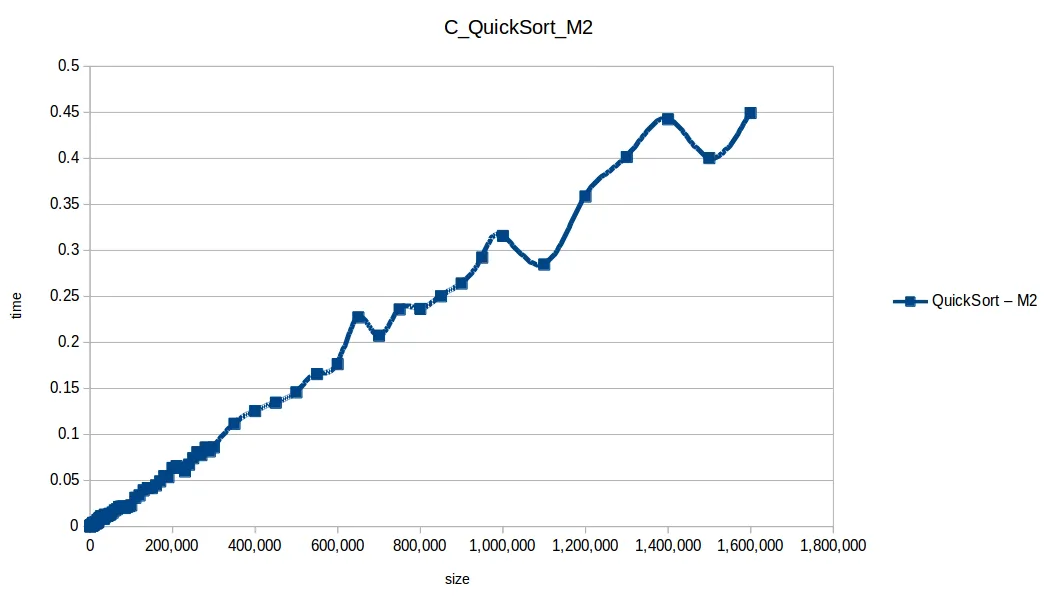
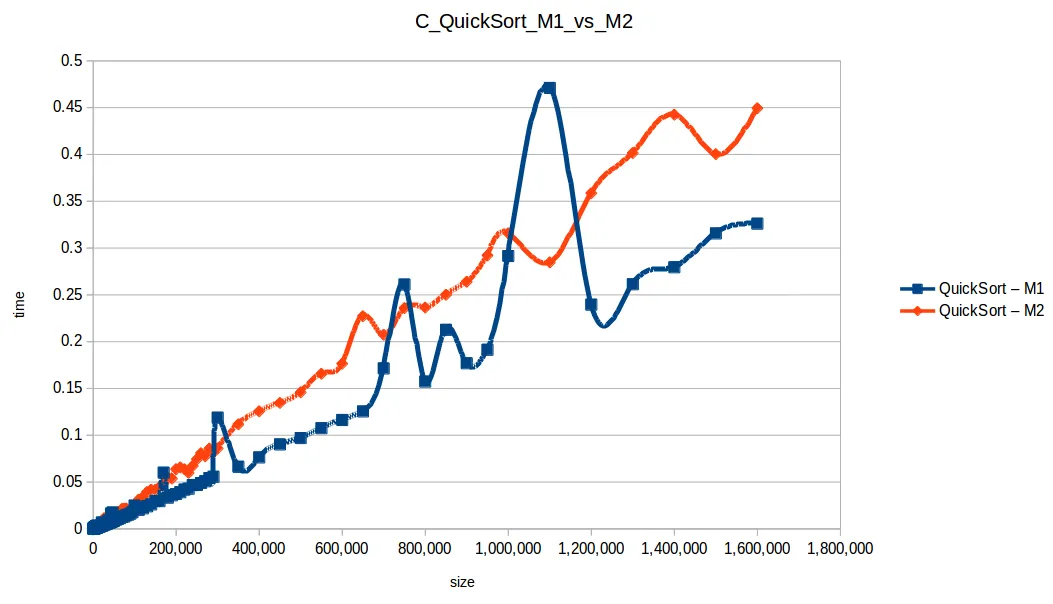
Selección (Selection Sort): O(n^2)
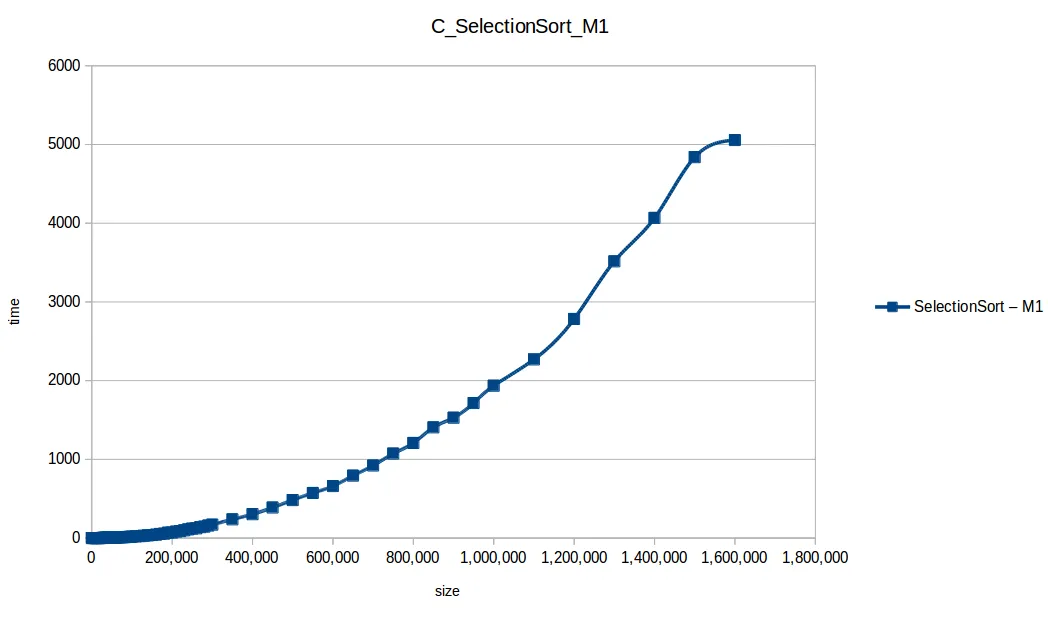
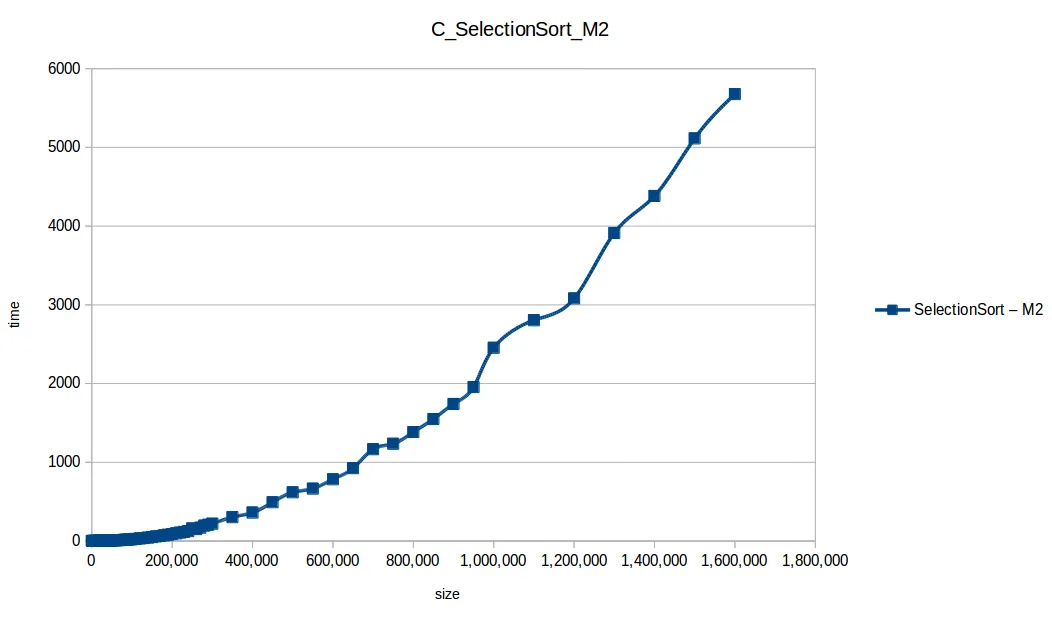
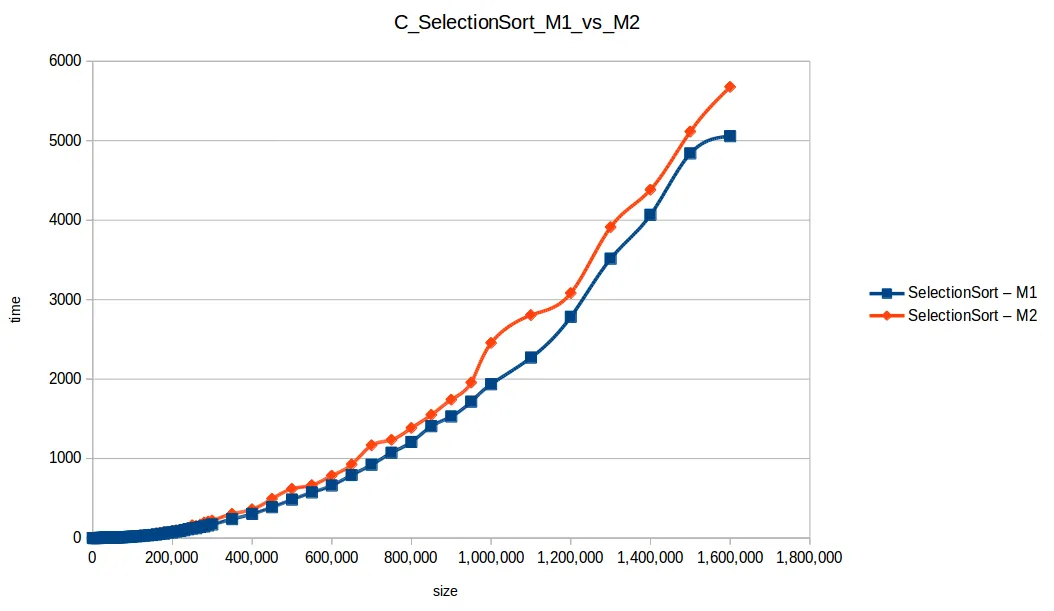
Gráfica comparativa de todos los algoritmos
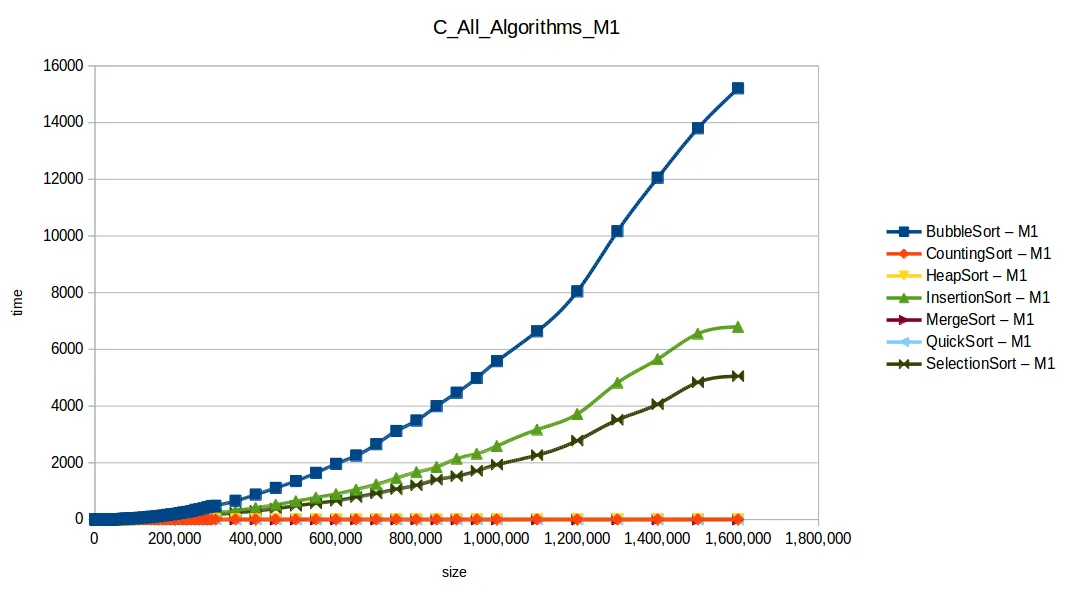
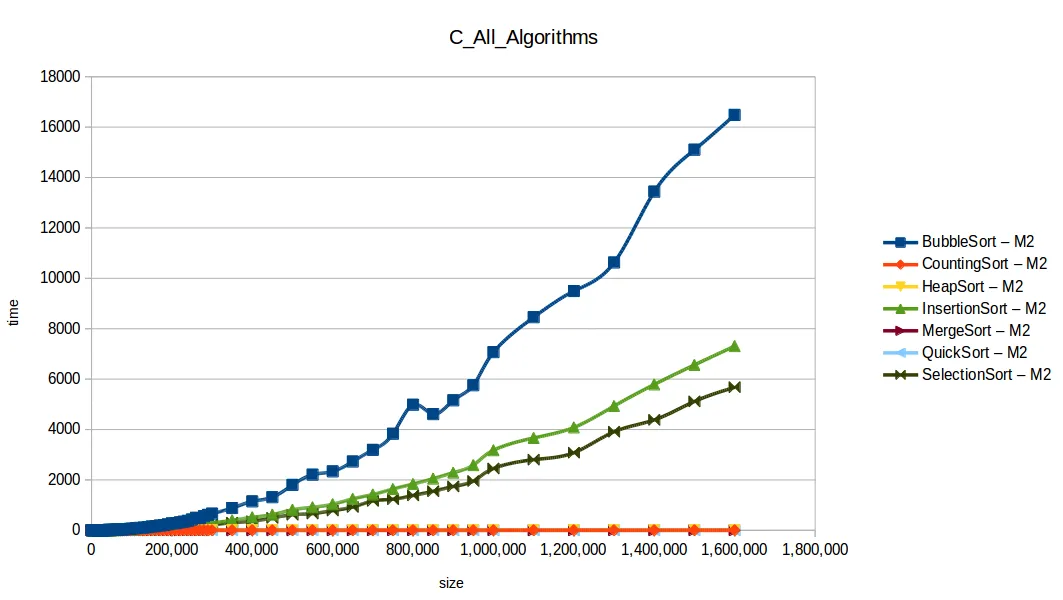
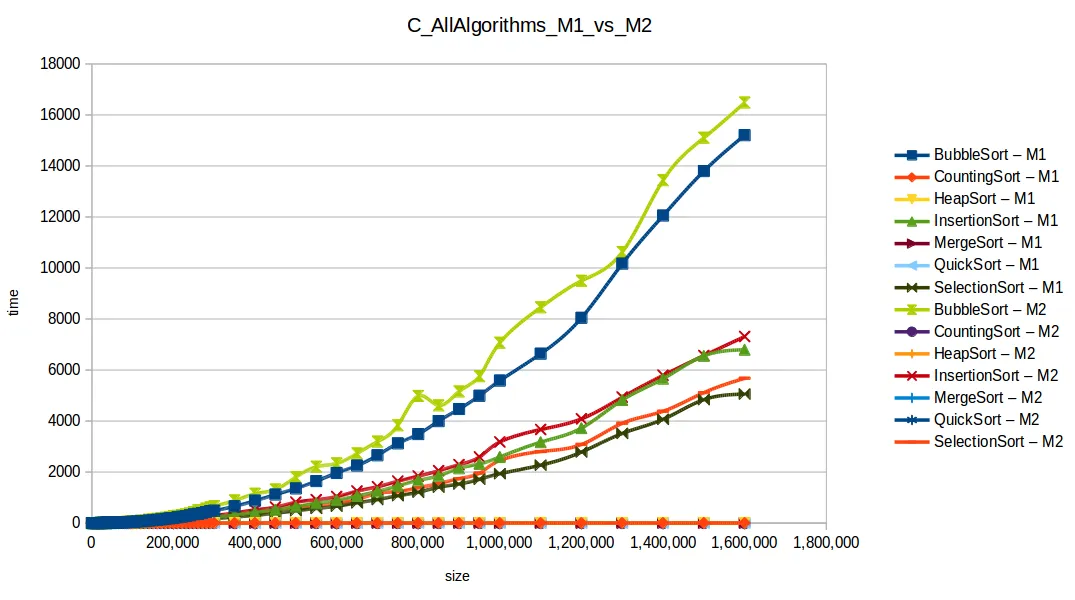
En esa comparativa, los cuatro algoritmos rápidos (quickSort, mergeSort, heapSort, countingSort) se solapan por escala. El perdedor claro fue bubbleSort, seguido por insertionSort y selectionSort.
Esto refleja un reto clásico en computación: para un mismo problema hay muchas soluciones, pero cada una funciona mejor bajo condiciones concretas.
Tiempos de respuesta (últimos 7 puntos)
Máquina 1 (M1)
| Size | BubbleSort | CountingSort | HeapSort | InsertionSort | MergeSort | QuickSort | SelectionSort |
|---|---|---|---|---|---|---|---|
| 1,000,000 | 5584.254499 | 0.016609 | 0.747395 | 2592.498977 | 0.704281 | 0.291499 | 1935.487457 |
| 1,100,000 | 6637.222252 | 0.019187 | 0.925764 | 3171.445715 | 0.653455 | 0.471039 | 2269.966268 |
| 1,200,000 | 8045.953682 | 0.023652 | 0.913537 | 3722.638885 | 0.513099 | 0.239454 | 2783.279525 |
| 1,300,000 | 10169.383378 | 0.045208 | 0.713308 | 4824.250285 | 0.575149 | 0.261289 | 3514.914589 |
| 1,400,000 | 12053.658798 | 0.034613 | 1.489084 | 5658.739951 | 0.676112 | 0.279478 | 4066.729922 |
| 1,500,000 | 13798.854123 | 0.027525 | 1.094257 | 6555.365499 | 0.743651 | 0.315602 | 4839.340426 |
| 1,600,000 | 15205.680544 | 0.028478 | 0.996648 | 6794.512119 | 0.725347 | 0.325990 | 5056.213092 |
Máquina 2 (M2)
| Size | BubbleSort | CountingSort | HeapSort | InsertionSort | MergeSort | QuickSort | SelectionSort |
|---|---|---|---|---|---|---|---|
| 1,000,000 | 7069.317038 | 0.032415 | 0.752168 | 3178.694237 | 0.558200 | 0.315689 | 2454.531144 |
| 1,100,000 | 8458.150387 | 0.024157 | 0.842038 | 3666.359787 | 0.557481 | 0.284579 | 2804.449695 |
| 1,200,000 | 9495.898708 | 0.026530 | 0.882819 | 4084.581924 | 0.616636 | 0.358502 | 3081.748250 |
| 1,300,000 | 10626.023771 | 0.027309 | 0.913814 | 4933.201883 | 0.753890 | 0.401456 | 3912.714921 |
| 1,400,000 | 13439.250082 | 0.030009 | 1.061221 | 5790.797804 | 0.633180 | 0.442449 | 4066.729922 |
| 1,500,000 | 15102.736592 | 0.031826 | 1.064744 | 6565.630358 | 0.788551 | 0.400238 | 5114.565289 |
| 1,600,000 | 16483.694808 | 0.039298 | 1.365129 | 7311.347004 | 0.760618 | 0.449284 | 5676.768371 |
Algoritmos rápidos
Al graficar solo los algoritmos eficientes (quickSort, mergeSort, heapSort, countingSort), casi ninguno superó 1 segundo con 1.600.000 datos.
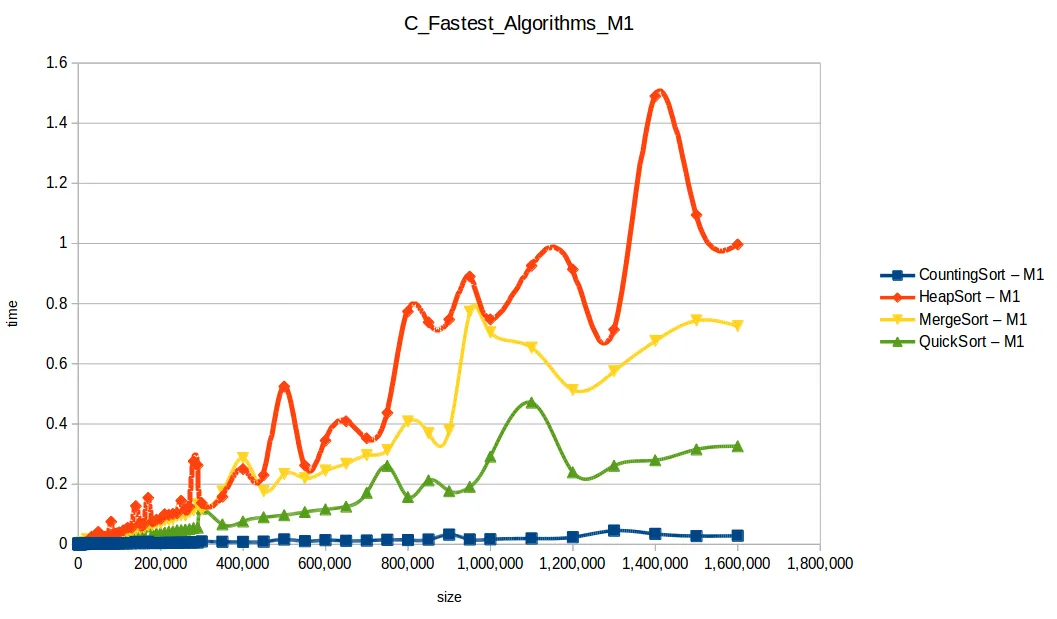
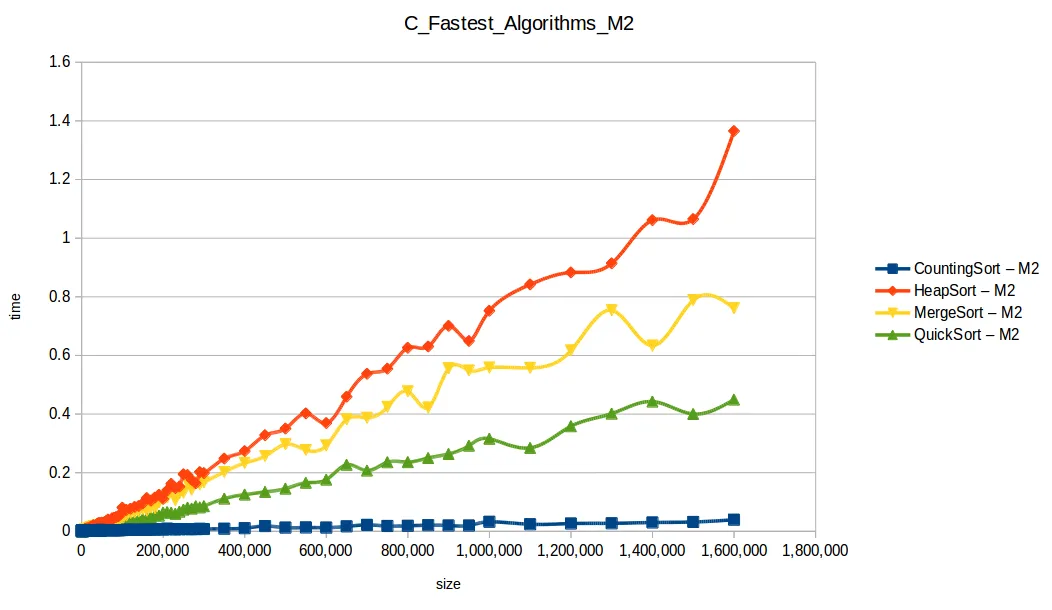
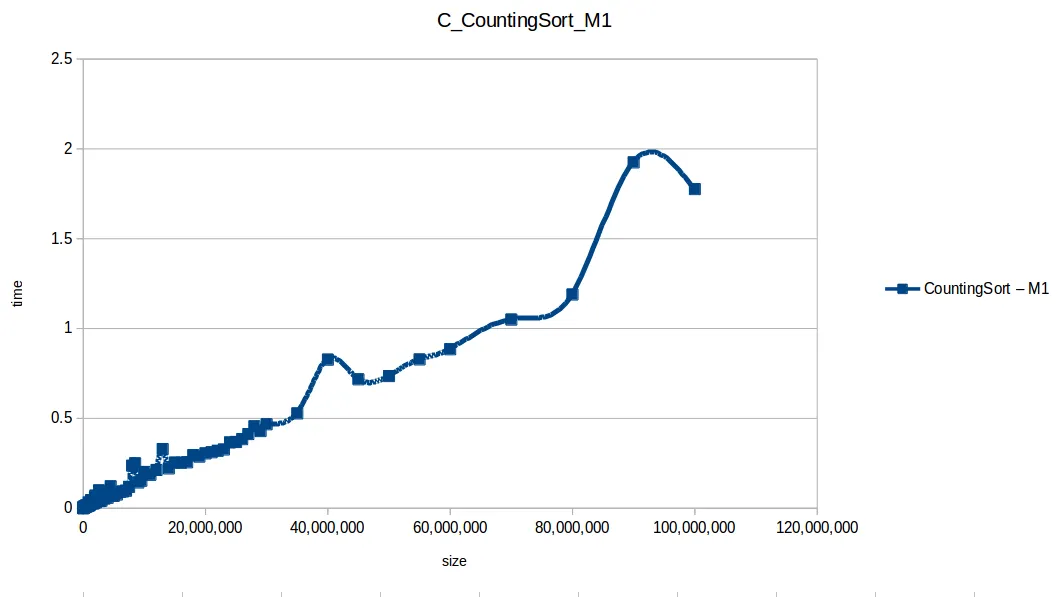
El ganador fue countingSort (O(n+k)), pero no es una bala de plata:
- Solo funciona con enteros.
- Puede consumir mucha memoria si
máximo - mínimoes grande.
En segundo lugar quedó quickSort, muy usado en práctica, aunque puede degradar a O(n^2) con mala selección de pivote y distribuciones adversas.
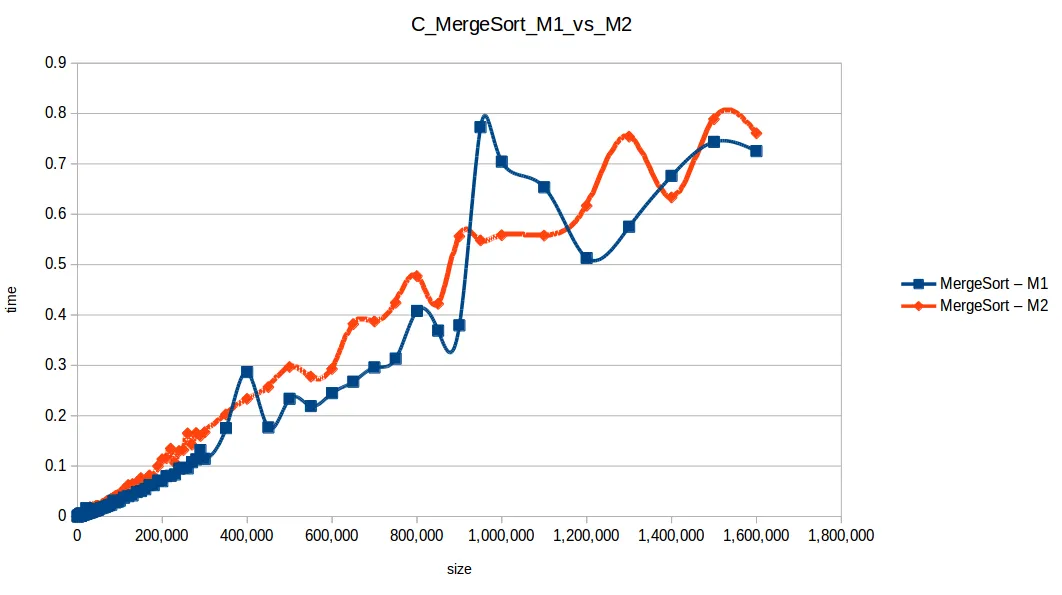
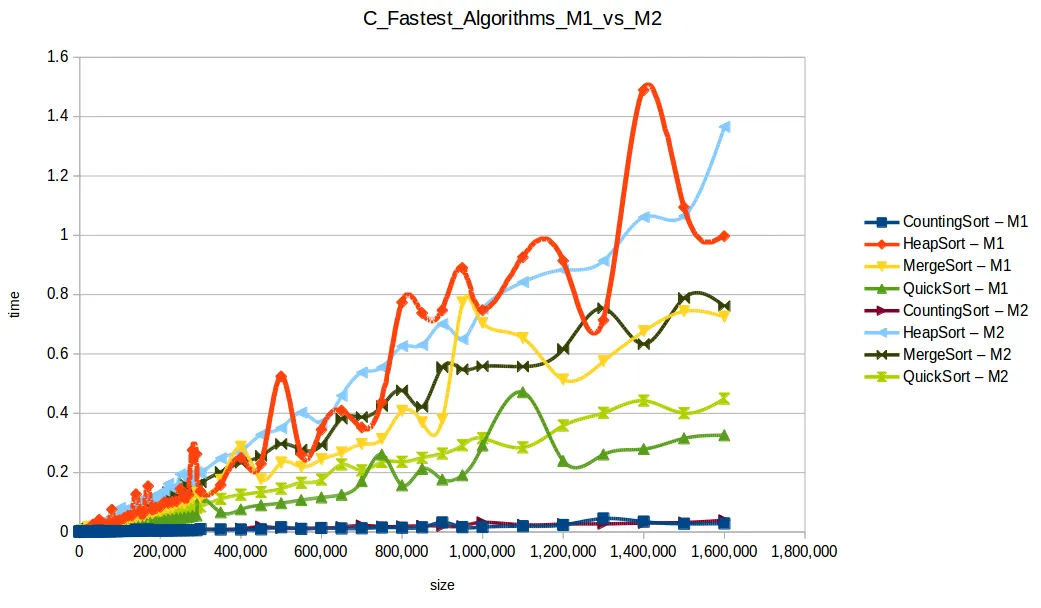
Máquina 1 vs Máquina 2
Surgió una pregunta importante: ¿cómo puede M1 vencer a M2 en tiempos si M2 tiene el doble de recursos?
La clave es que los algoritmos no estaban paralelizados. Aunque M2 tiene dos núcleos, el código no usaba hilos para explotarlos realmente.
Eso deja la comparación más ligada a frecuencia de CPU por núcleo:
- M1:
2399.998 MHz - M2:
1799.998 MHz
Información del sistema
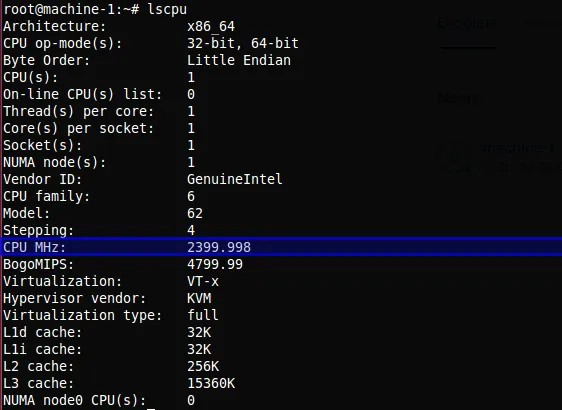
lscpu: 1 núcleo a 2399.998 MHz — la mayor frecuencia de reloj compensó el menor número de recursos.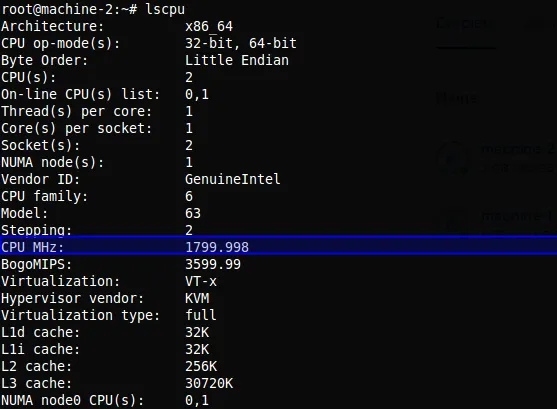
lscpu: 2 núcleos a 1799.998 MHz — más núcleos y RAM, pero menor frecuencia por núcleo.Las unidades de frecuencia:
- 1 Hertz (Hz) = un ciclo/segundo
- 1 Kilohertz (KHz) = 1024 Hz
- 1 Megahertz (MHz) = 1024 KHz
- 1 Gigahertz (GHz) = 1024 MHz
- 1 Terahertz (THz) = 1024 GHz
Comando usado para inspeccionar CPU:
$ lscpuPrueba extendida (máxima capacidad por memoria)
Luego extendí el experimento enfocándome en algoritmos eficientes para ver cuánto soportaban las máquinas por memoria disponible:
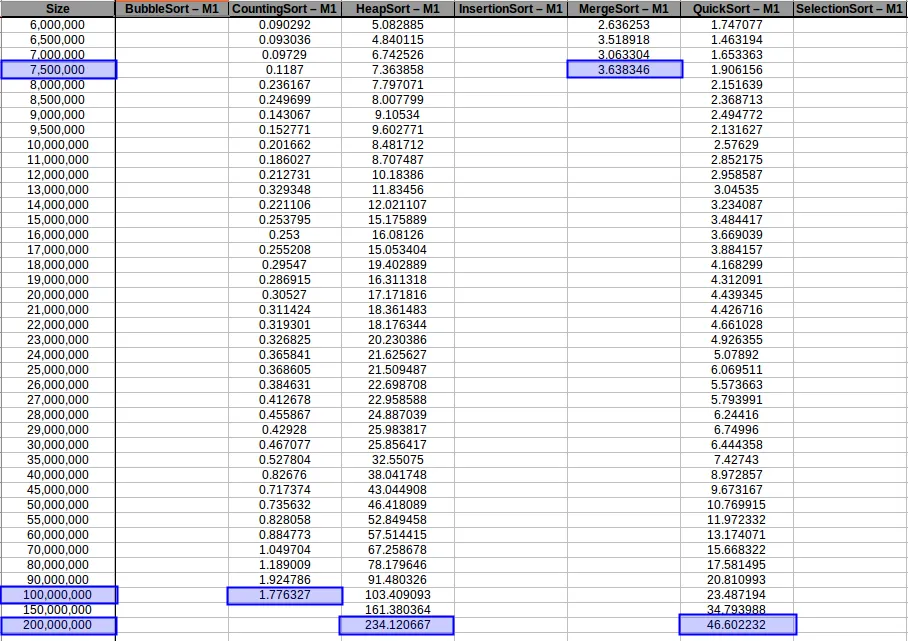
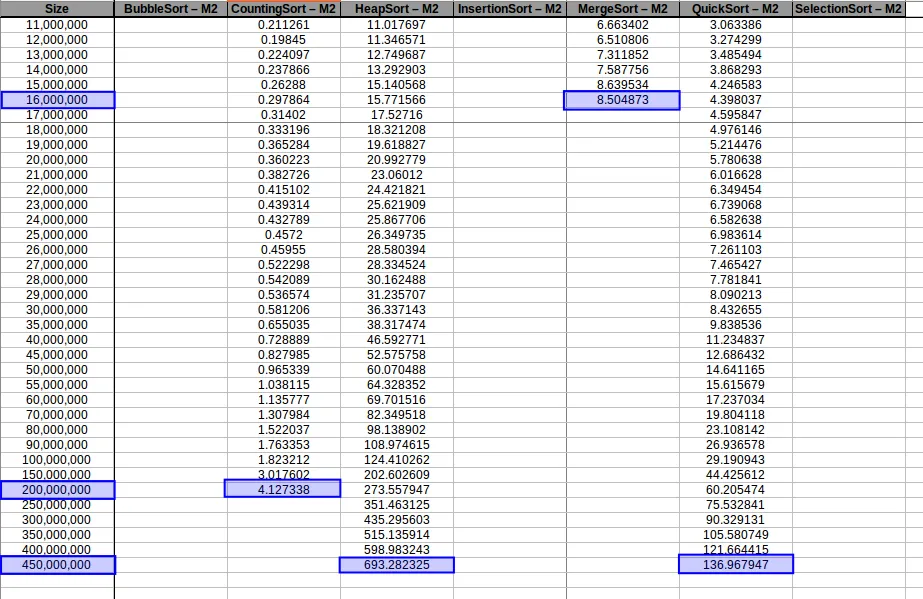
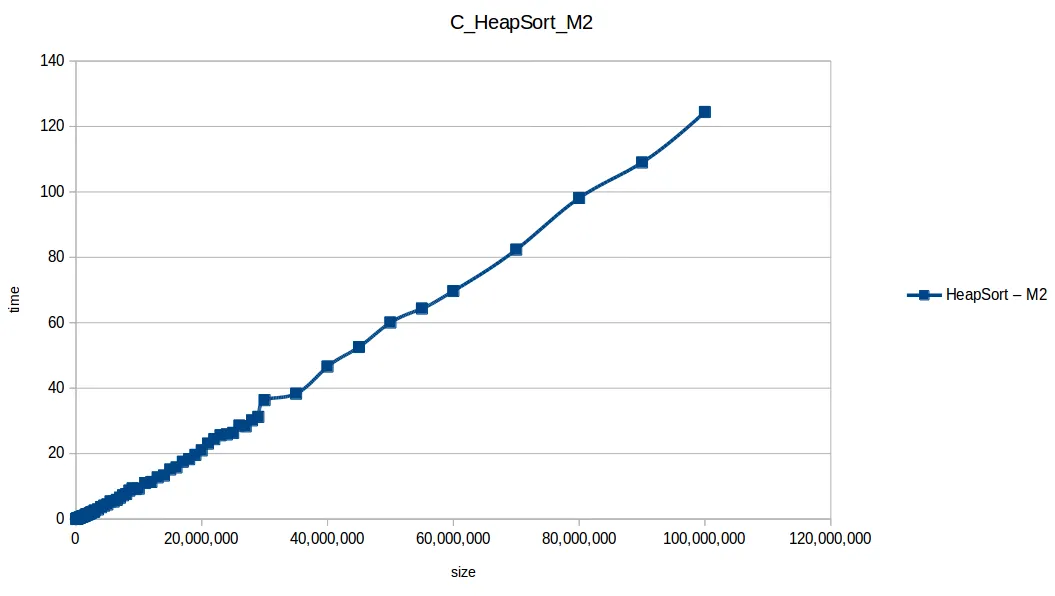
Aquí M2 (2GB RAM) sí logró procesar más volumen en varios casos.
Counting Sort hasta máximo volumen
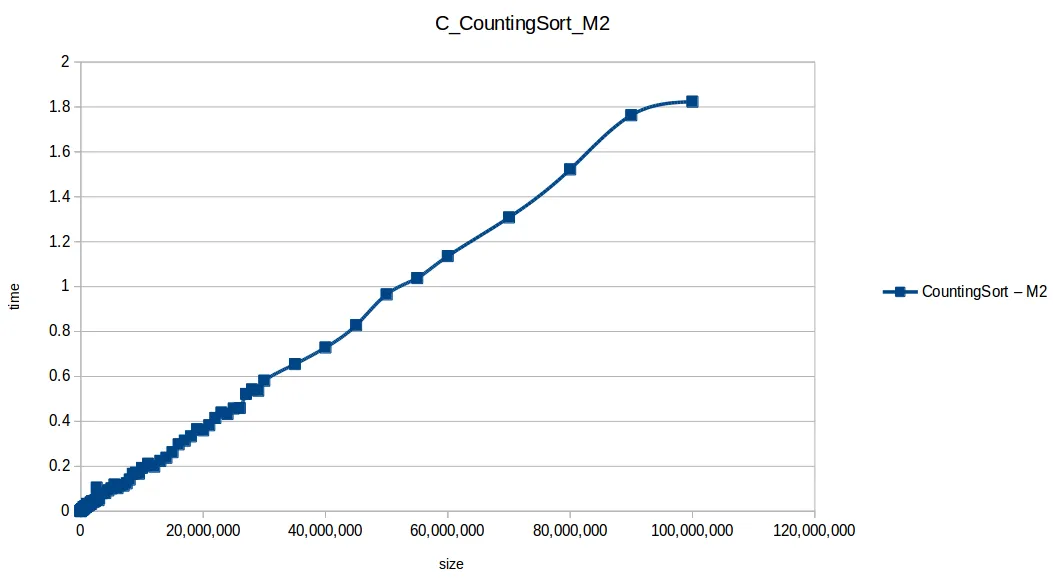
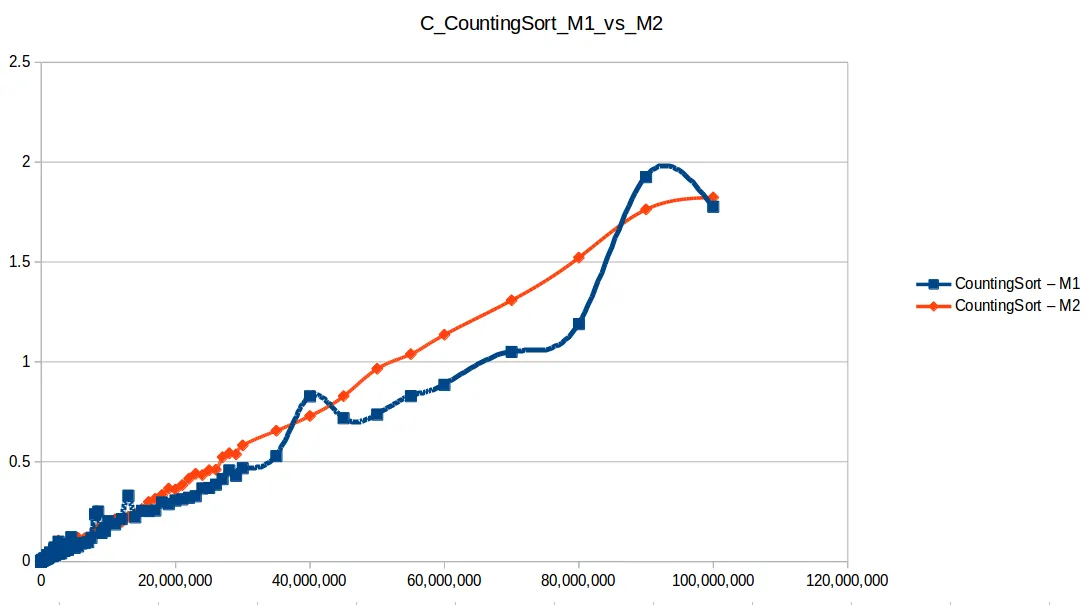
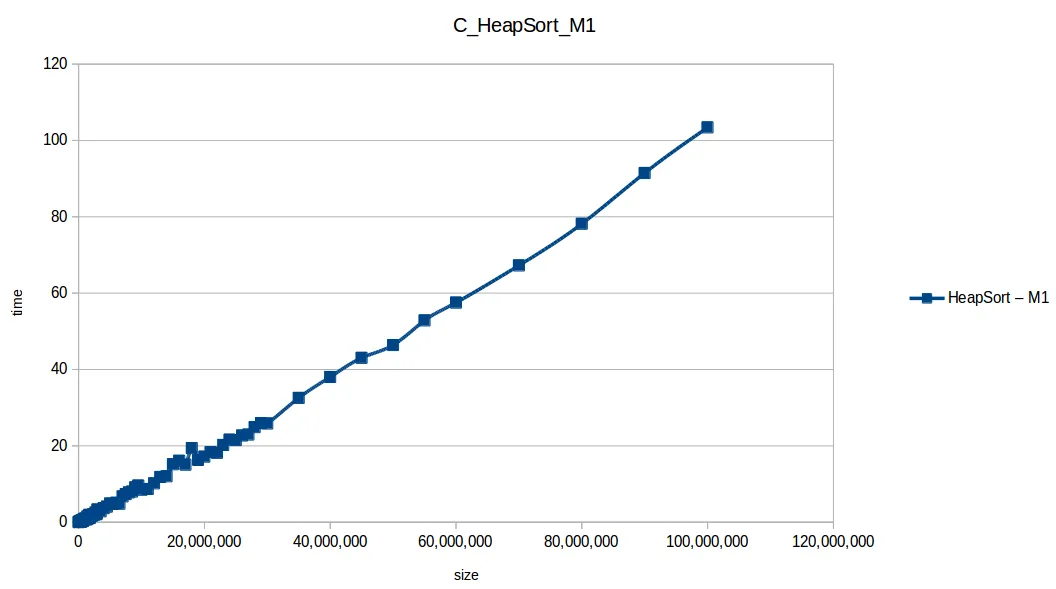
Heap Sort hasta máximo volumen
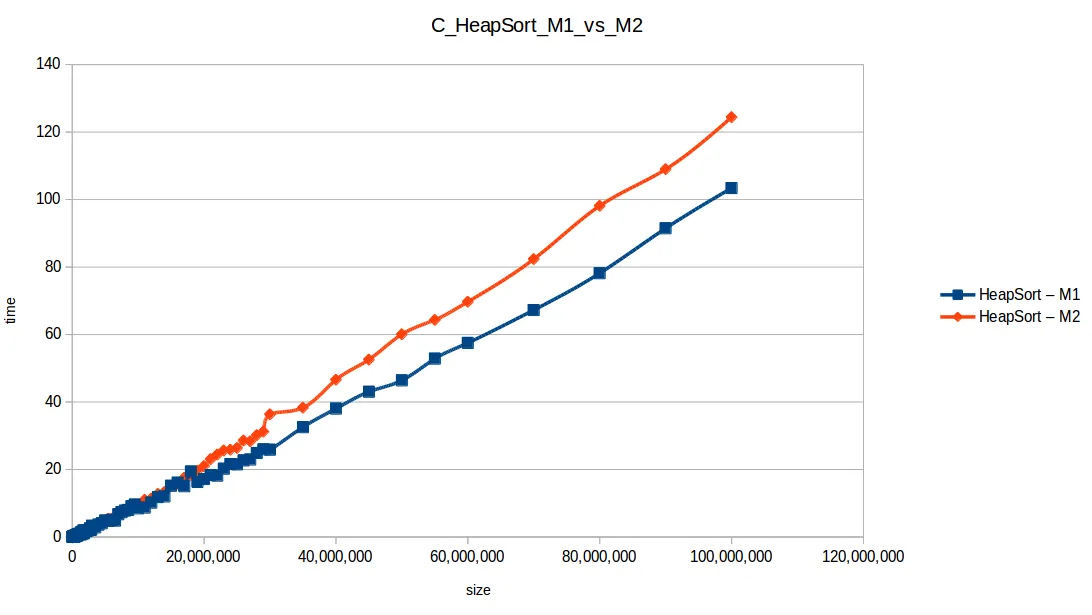
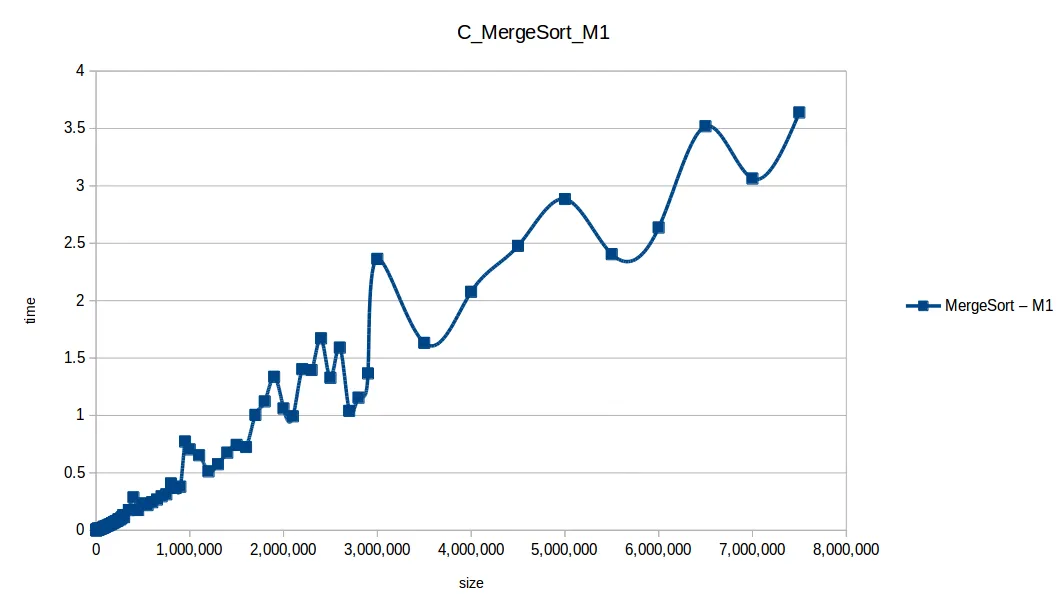
Merge Sort hasta máximo volumen
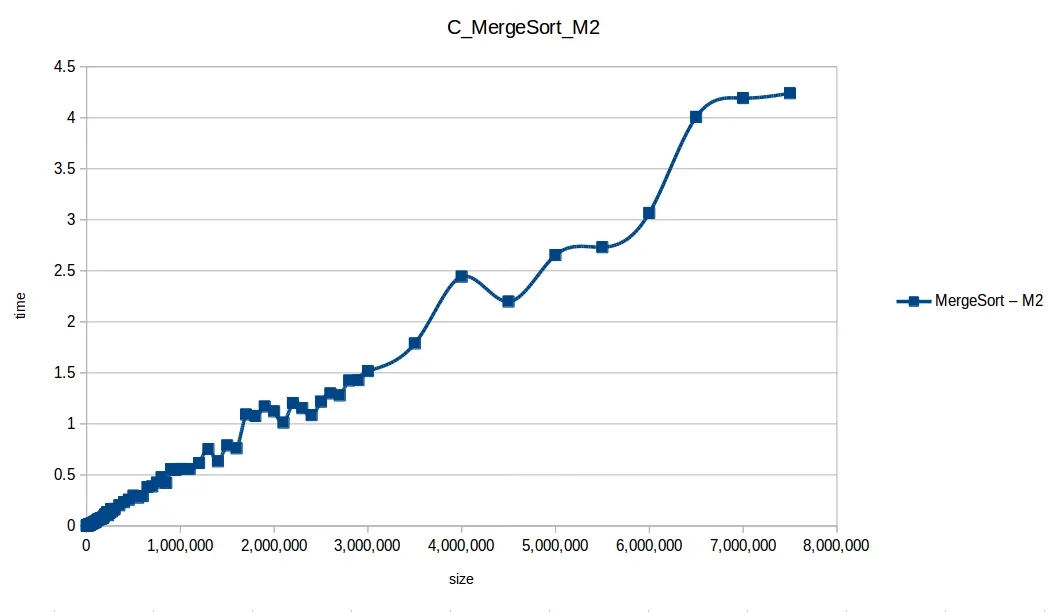
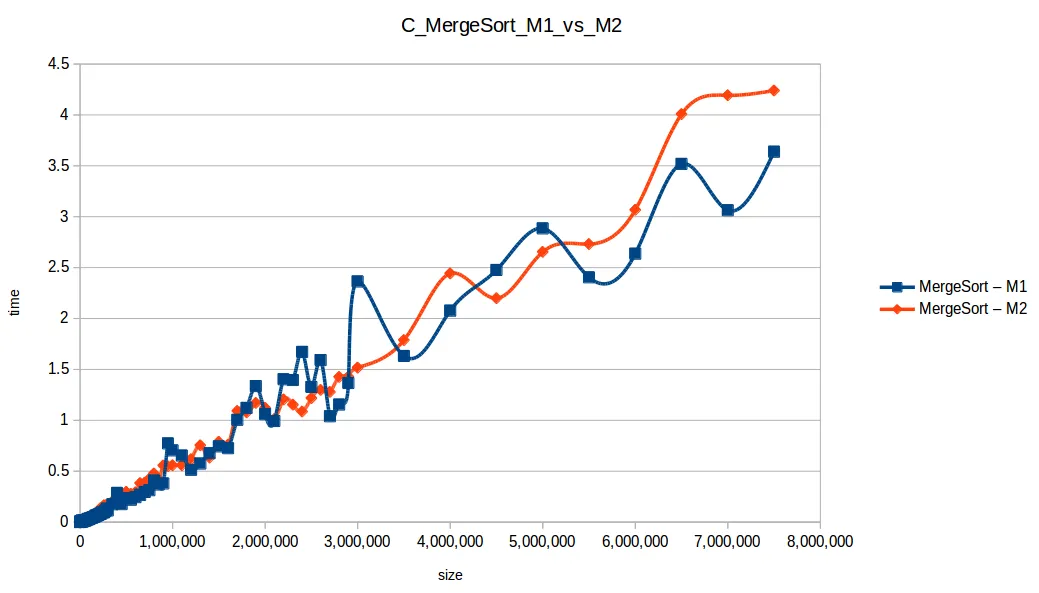
Quick Sort hasta máximo volumen
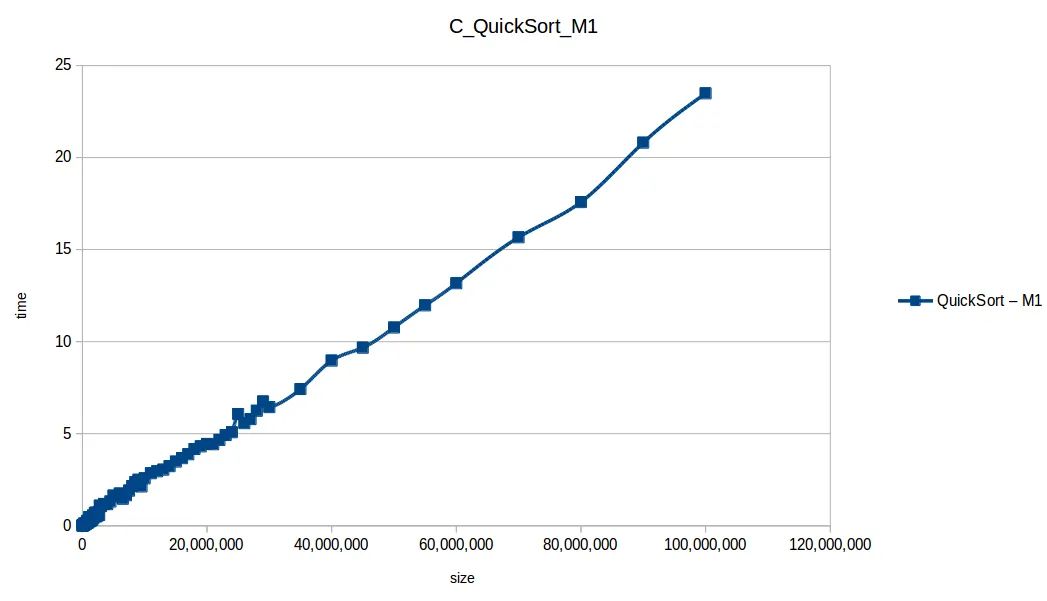
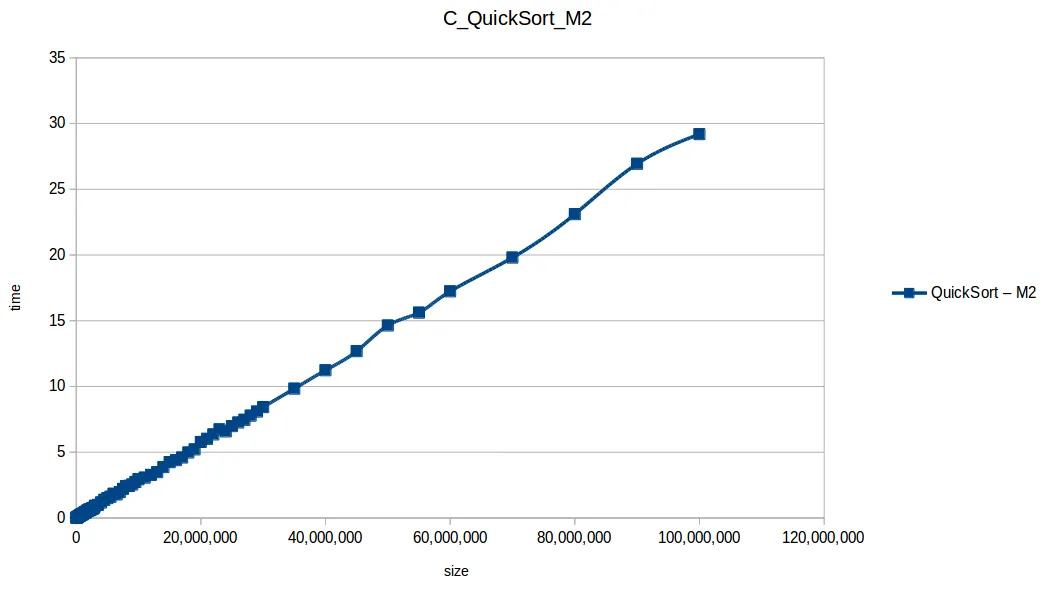
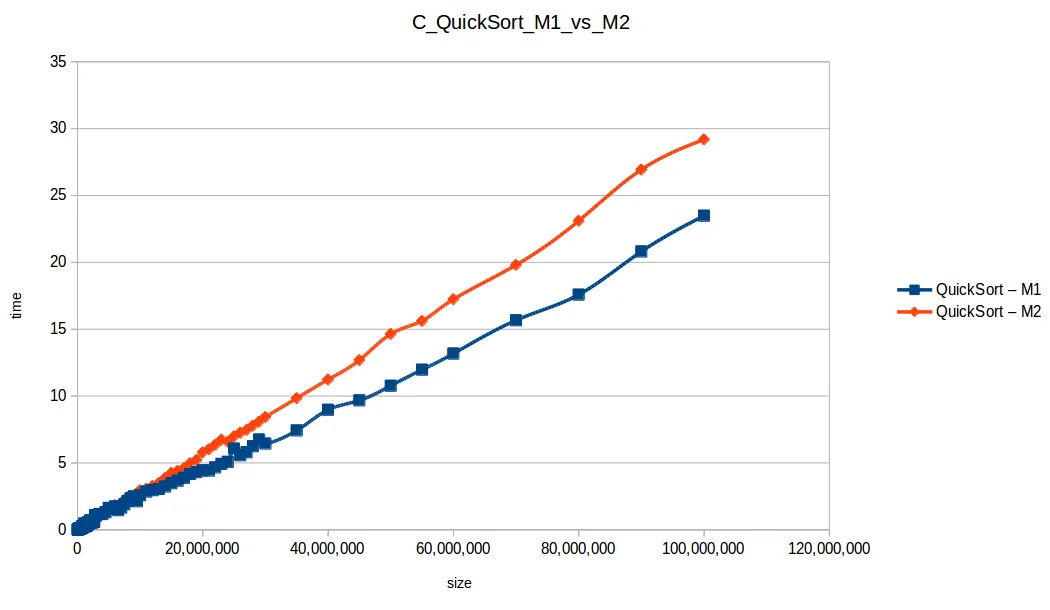
Comparativa final de algoritmos eficientes
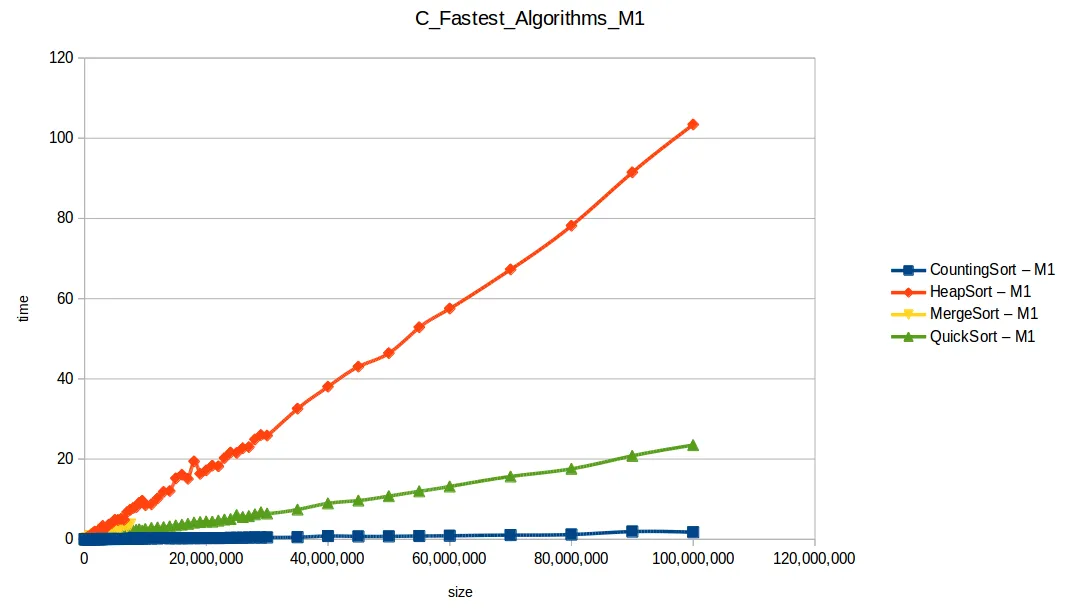
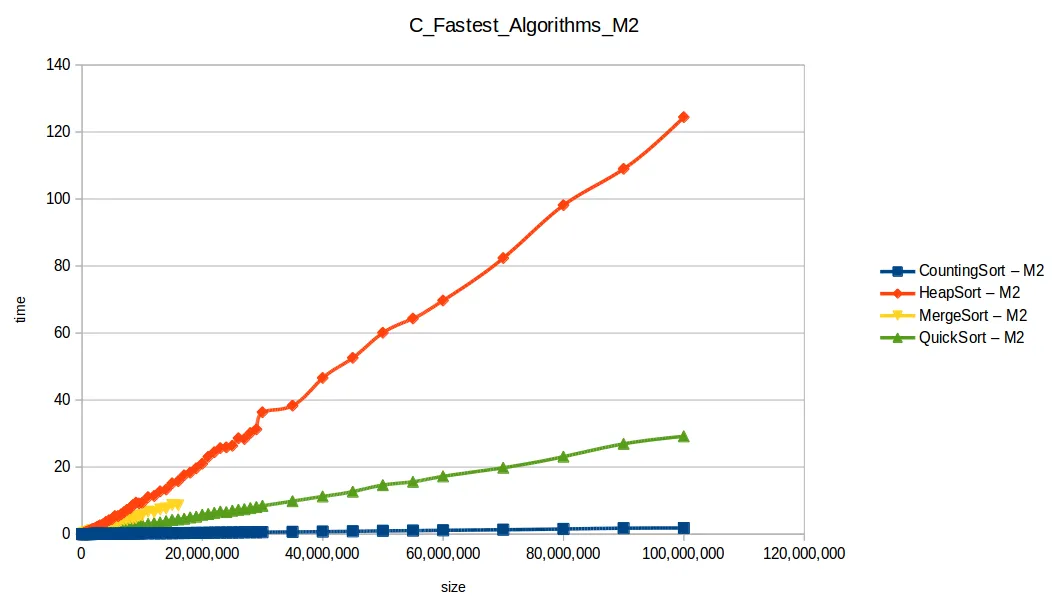
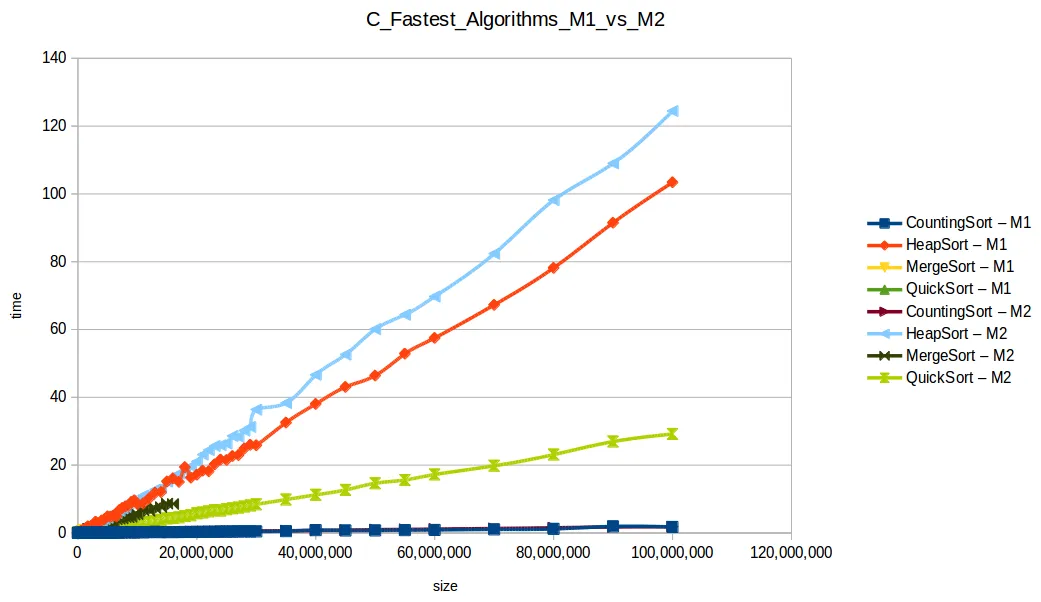
Al extender el experimento con mayor volumen de datos, las curvas se volvieron más uniformes y comparables con sus funciones de complejidad teórica.
Conclusiones
Este ejercicio me ayudó a reforzar varias ideas:
- Complejidad algorítmica importa, pero no cuenta toda la historia.
- El hardware influye según el tipo de algoritmo y su uso real de recursos.
- Más RAM no siempre acelera, pero puede ampliar el límite de datos procesables.
- Paralelismo real requiere diseño explícito (hilos, partición de trabajo, etc.).
Espero que este análisis le sirva a quien está empezando en ciencias de la computación o quiere repasar fundamentos.
Recursos: Repositorio con código en GitHub
“La inteligencia consiste no solo en el conocimiento, sino también en la destreza de aplicar los conocimientos en la práctica.”
Aristóteles

Sergio Alexander Florez Galeano
CTO y Cofundador en DailyBot
Ingeniero de software y emprendedor colombiano (DailyBot, YC S21). Escribo sobre agentes de IA, herramientas para desarrolladores, startups y el arte de la ingeniería de software, y construyo este sitio a la vista de todos en XergioAleX.com.
Mantente al día
Recibe una notificación cuando publique algo nuevo. Sin spam, cancela cuando quieras.
Sin spam. Cancela cuando quieras.